Druid是什么

也是基于列存的。
对比时间序列数据库TSDB

对比分布式OLAP数据库

es本身是检索(全恩)系统,现在也可以增强聚合计算,不过olap上有些短板。
kylin是需要预计算的,批量构建cube的过程很难满足低延时的数据写入。
presto需要起一堆的进程去查hdfs文件,一般也很难做到低延时的数据写入以及快速交互式查询。不过可以考虑presto+hbase
Druid的优缺点

数据写入前预聚合
目前版本0.12.0
不支持join
明细查询也要瓶颈,当然也可以关掉预计算rollup,直接查明细数据,但是这样会增大数据量存储,对检索效率有影响。bit本身的索引结构只有bitmap索引,不适合明细查询。不像其他明细查询的数据库有B+等,LSM树等,没有这种索引类型
是否需要druid

一定要处理时间序列的数据,druid是对时间进行分片的。
实时报表类的,各种即席查询。
需要提前定义schema
Druid概念与特性

数据模型
事件
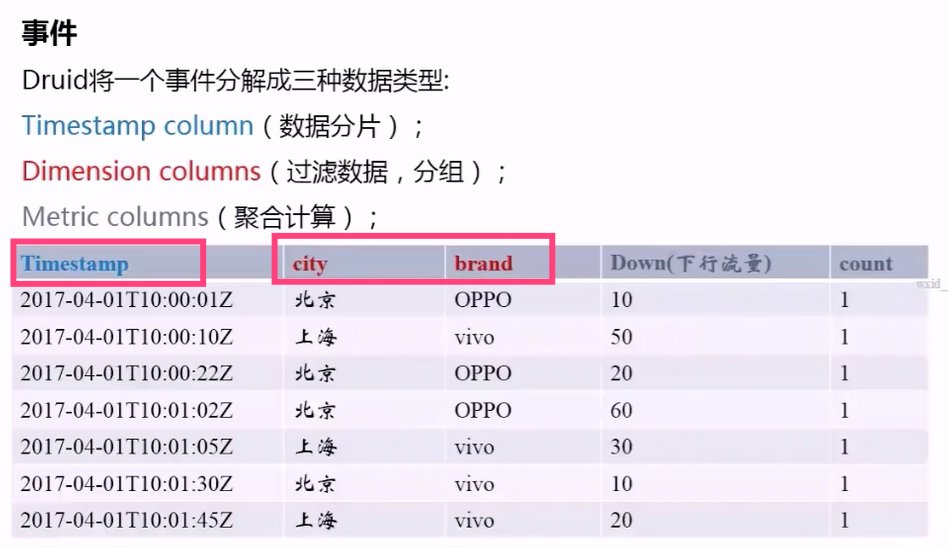
时间字段
维度列
指标列,数值字段
roll-up
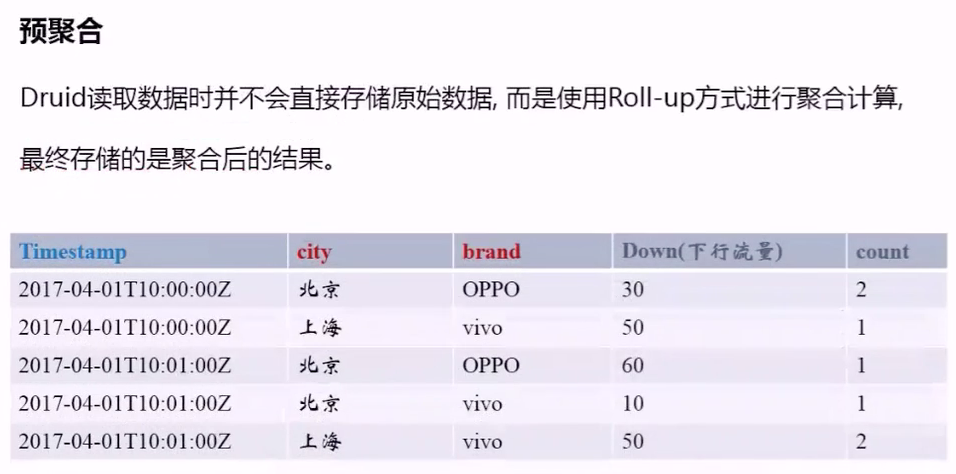
此图是按照分钟级聚合的。
在指定的时间粒度内,把维度列相同的数据,将他们的指标列按照用户指定的方式进行聚合。
对数据压缩有很大所用
数据存储

segment官方推荐大小300-700M
维度列

维度列中包含一个字典,对所有值进行编码。

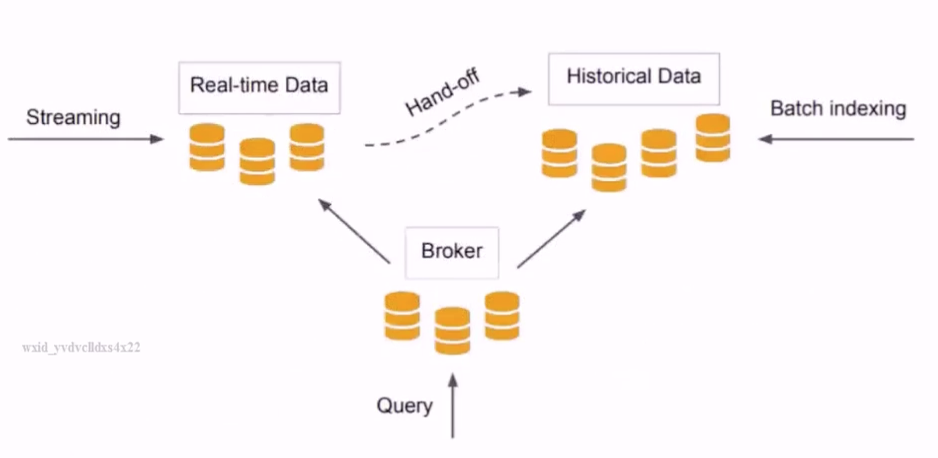
数据写入
实时

kafka可追加segment
traquality会抛弃迟到的数
??
离线

??
数据查询
查询模式
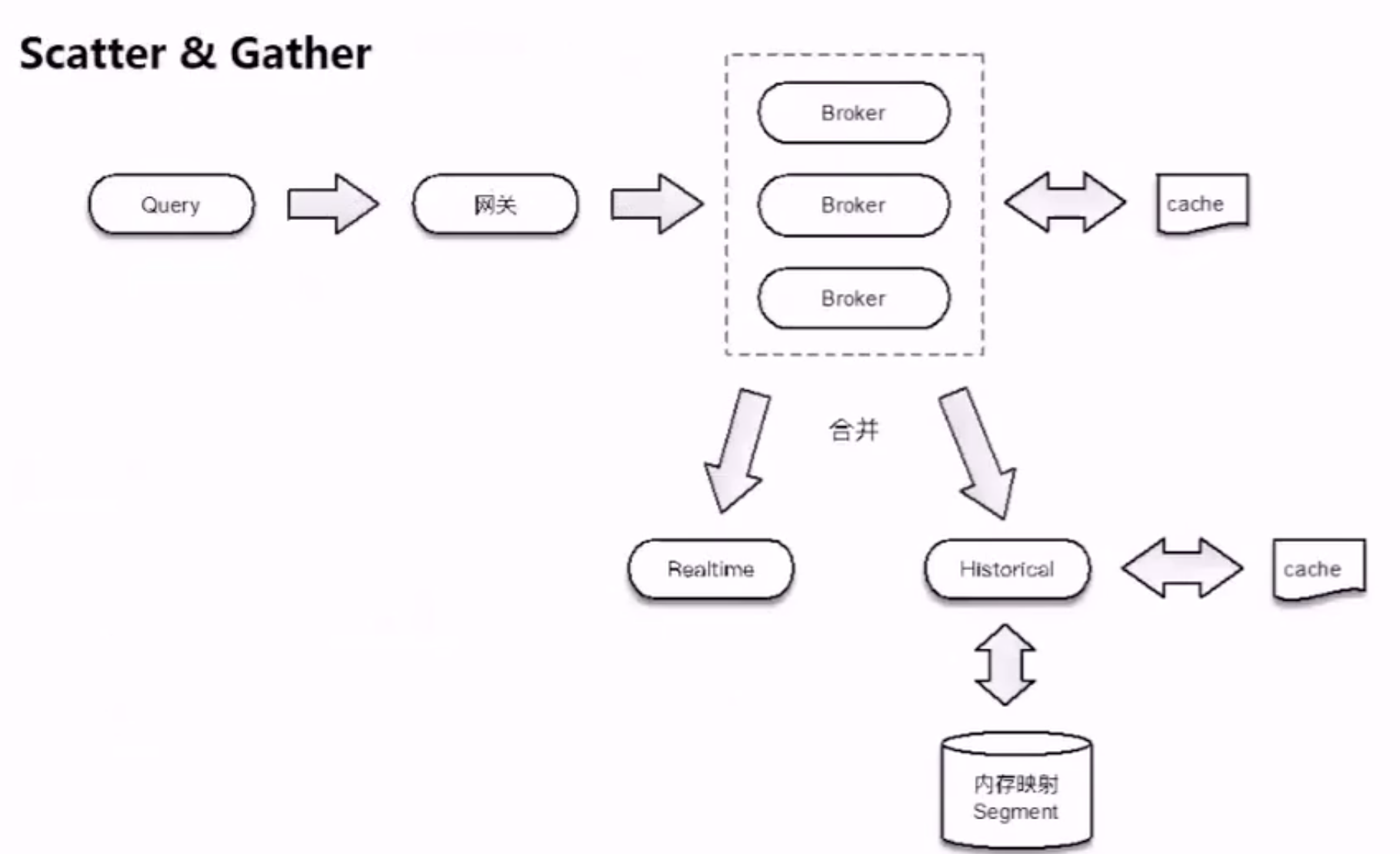


Druid vs ES

Druid vs KV存储(hbase)

Druid vs SQL on Hadoop(presto,spark sql)

druid做distinct是先group by 然后在count
预聚合是在内存中做的。
Druid架构以及原理
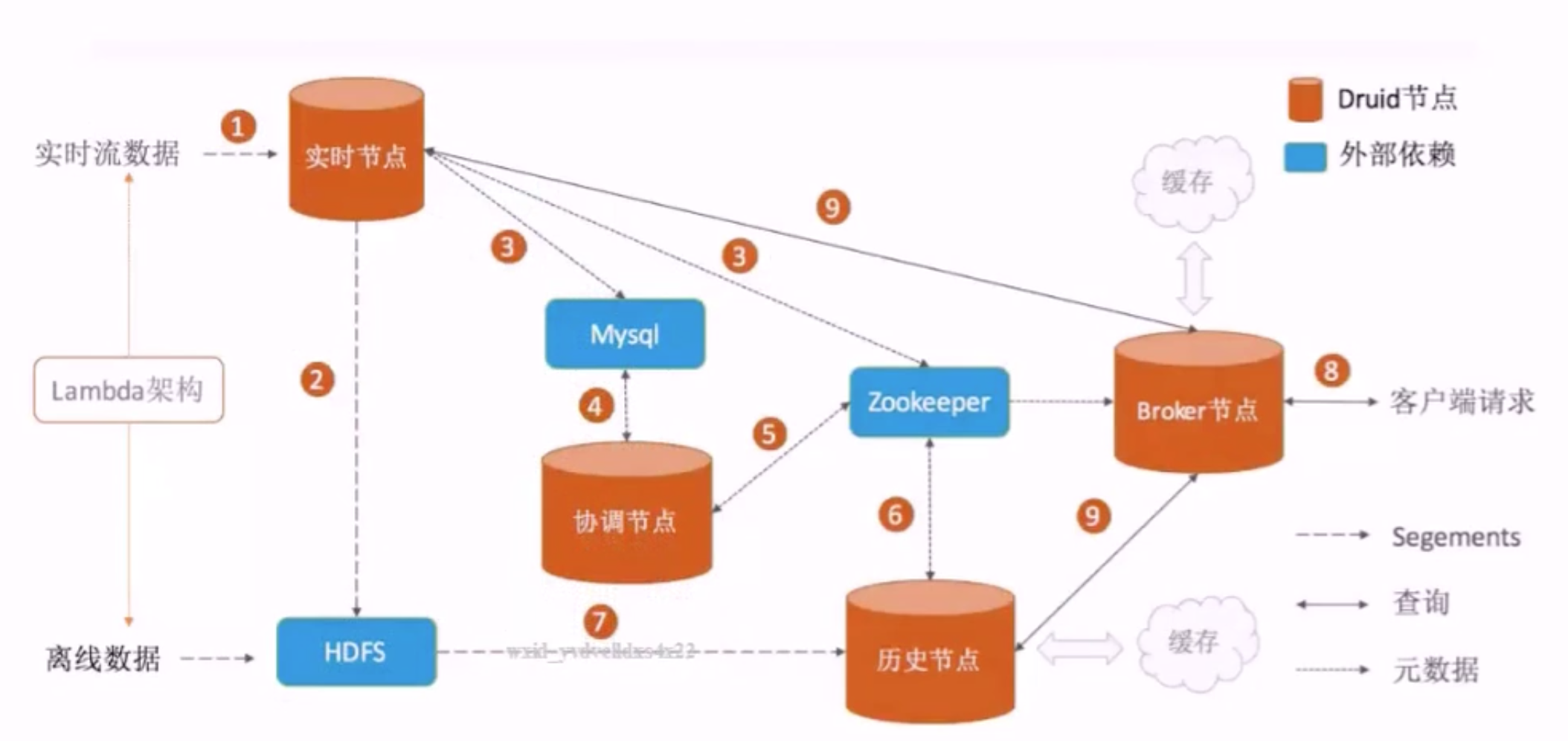
外部依赖

角色节点

Coordinator

Historical

Broker

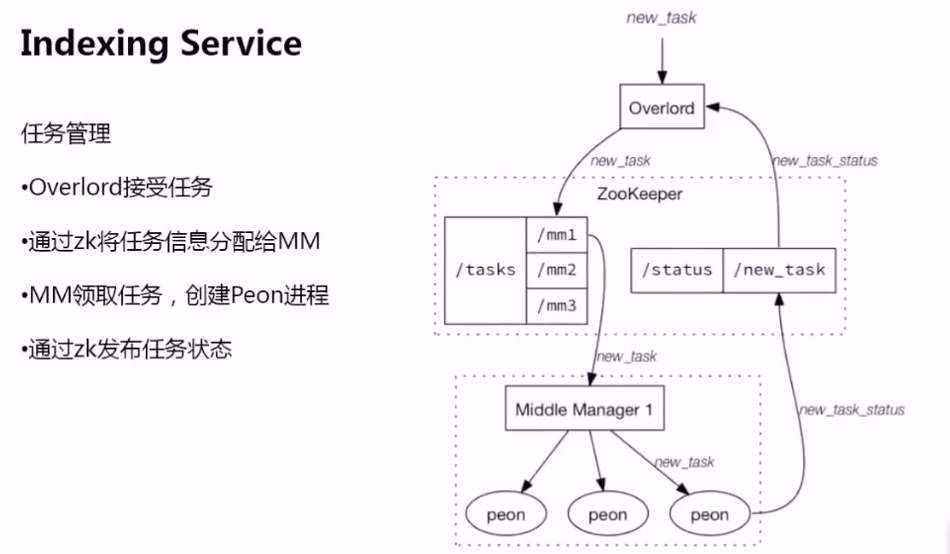
Indexing Service

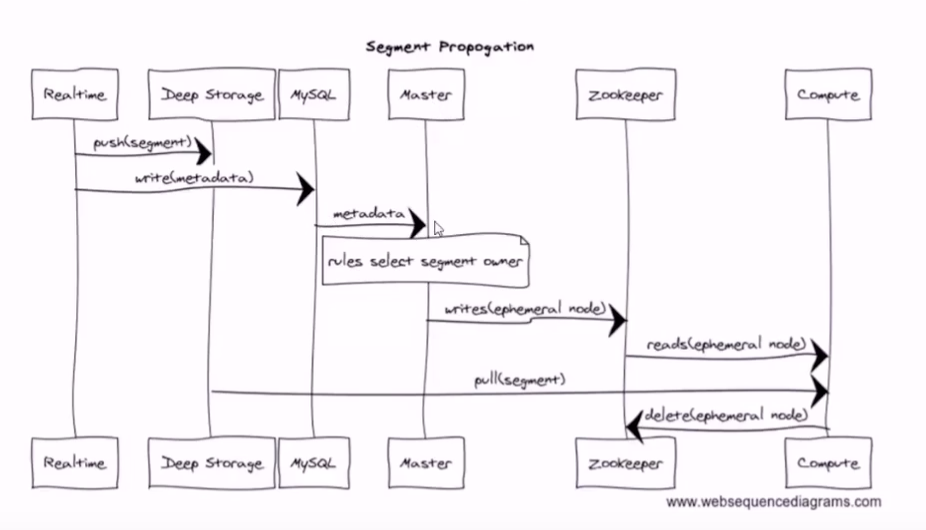
第三方依赖
Zookeeper

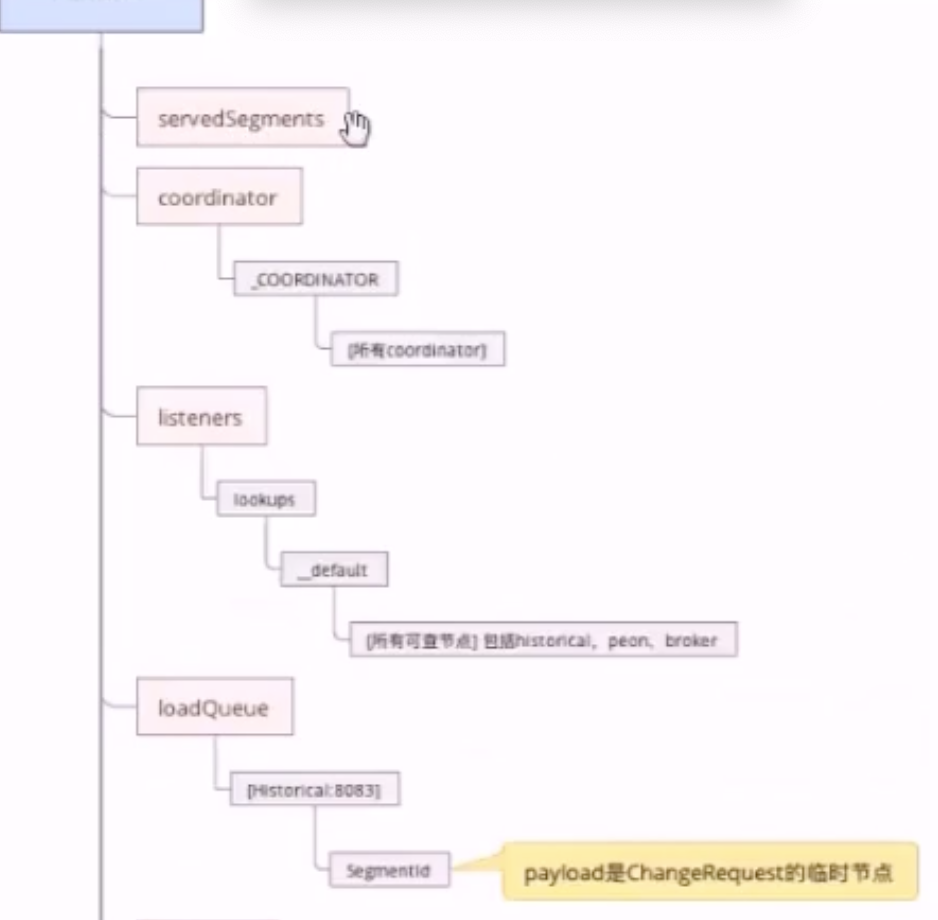
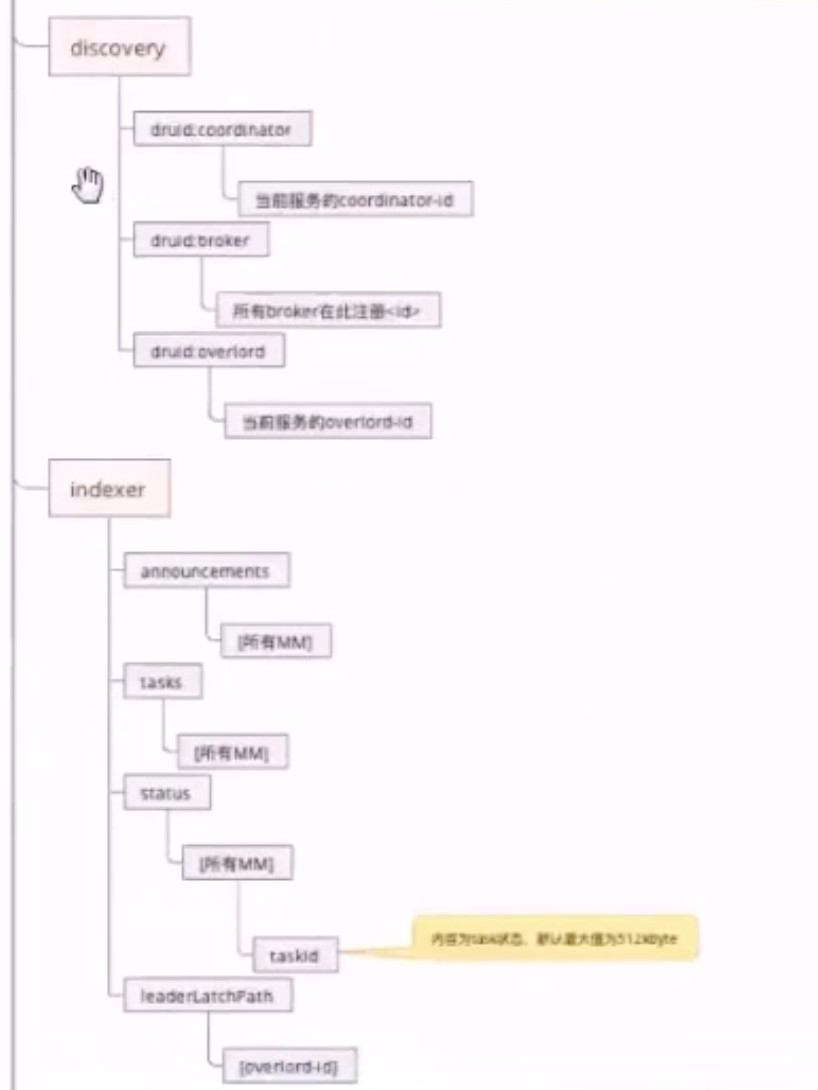
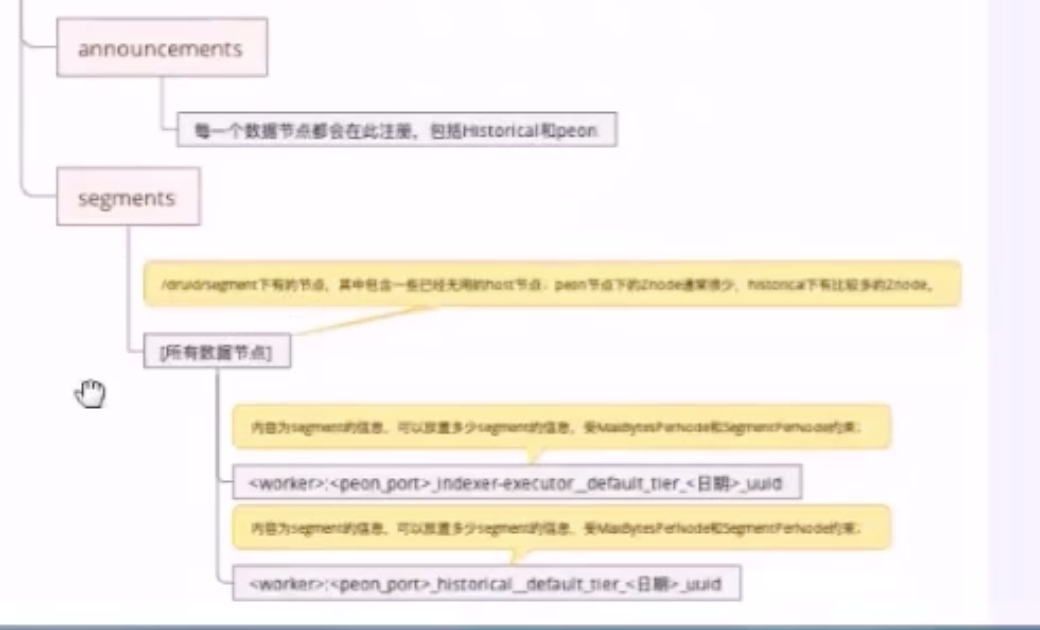
元数据

DeepStorage
