https://blog.csdn.net/kwu_ganymede/article/details/51299115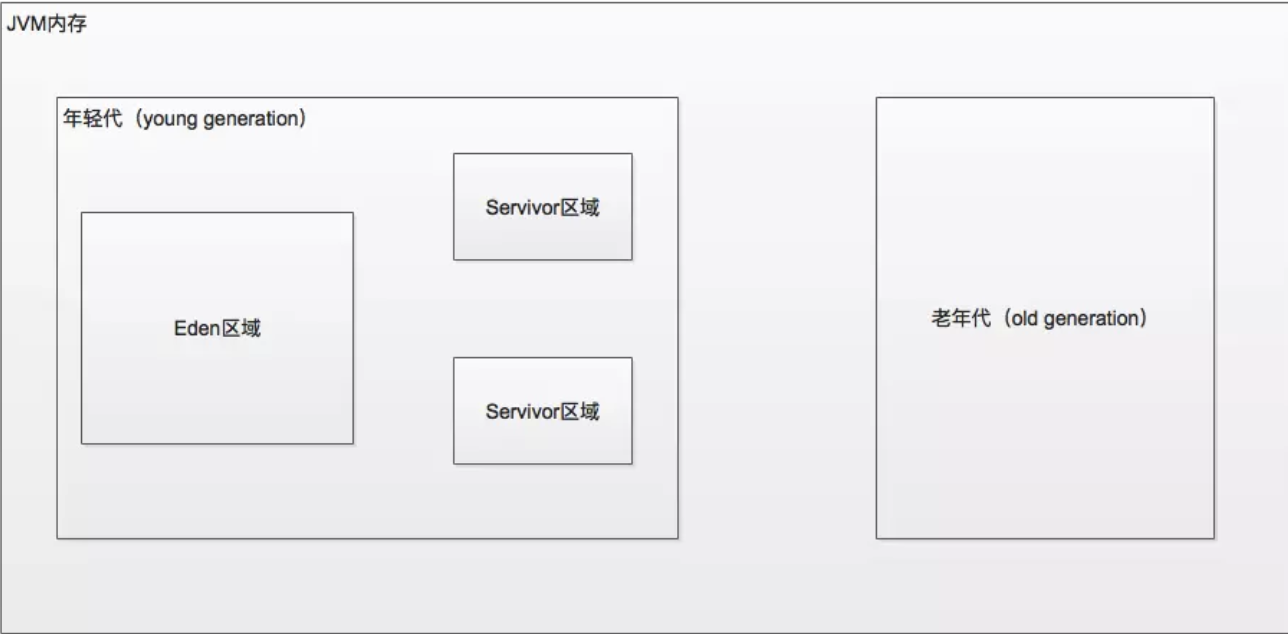
关于JVM内存的深入知识在这里不赘述,请大家自行对相关知识进行补充。好,说回Spark,运行Spark作业的时候,JVM对会对Spark作业产生什么影响呢?答案很简单,如果数据量过大,一定会导致JVM内存不足。在Spark作业运行时,会创建出来大量的对象,每一次将对象放入JVM时,首先将创建的对象都放入到eden区域和其中一个survivor区域中;当eden区域和一个survivor区域放满了以后,这个时候会触发minor gc,把不再使用的对象全部清除,而剩余的对象放入另外一个servivor区域中。JVM中默认的eden,survivor1,survivor2的内存占比为8:1:1。当存活的对象在一个servivor中放不下的时候,就会将这些对象移动到老年代。如果JVM的内存不够大的话,就会频繁的触发minor gc,这样会导致一些短生命周期的对象进入到老年代,老年代的对象不断的囤积,最终触发full gc。一次full gc会使得所有其他程序暂停很长时间。最终严重影响我们的Spark的性能和运行速度。
内存瓶颈


Spark从1.6.0版本开始,内存管理模块就发生了改变,旧版本的内存管理模块是实现了StaticMemoryManager 类,现在被称为”legacy”。”Legacy”模式默认被置为不可用,这就意味着当你用Spark1.5.x和Spark1.6.x运行相同的代码会有不同的结果,应当多加注意。考虑的兼容性,可以通过设置spark.memory.useLegacyMode为可用,默认是false.
这篇文章介绍自spark1.6.0版本后的新的内存管理模型,它实现的是UnifiedMemoryManager类。
在这张图中你可以看到三个主要内存区域。
Reserved Memory.这部分内存是被系统预留的,它的大小也是被硬编码的。在Spark1.6.0版本,它的大小是300MB,这就意味着这部分内存不能计入Spark内存计算,除非重新编译源码或设置spark.testing.reservedMemory,它的大小是不可改变的,因为park.testing.reservedMemory只是一个测试参数所以在生产中不推荐使用。注意,这部分内存只是被称为“Reserved”,实际上它不会被spark用来干任何事情 ,但是它限制了你在spark中可分配的内存大小。即使你想将全部JVM堆内存用于spark缓存数据,也不能使用这部分空闲内存(不是真的就浪费了,其实它存储了Spark的一些内部对象)。供参考,如果你不能为executor至少1.5 * Reserved Memory = 450MB的堆内存,任务将会失败并提示”please use larger heap size“的错误信息。
User Memory.这部分内存是分配Spark Memory内存之后的部分,而且这部分用来干什么完全取决于你。你可以用来存储RDD transformations过程使用的数据结构。例如,你可以通过mapPartitions transformation 重写Spark aggregation,mapPartitions transformations 保存hash表保证aggregation运行。这部分数据就保存在User Memory。再次强调,这是User Memory它完全由你决定存什么、如何使用,Spark完全不会管你拿这块区域用来做什么,怎么用,也不会考虑你的代码在这块区域是否会导致内存溢出。
Spark Memory.这部分内存就是由Spark管理了。这部分内存大小的计算:(“Java Heap” – “Reserved Memory”) * spark.memory.fraction,而且在spark1.6.0版本默认大小为: (“Java Heap” – 300MB) 0.75。例如:如果堆内存大小有4G,将有2847MB的Spark Memory,Spark Memory=(4\1024MB-300)*0.75=2847MB。这部分内存会被分成两部分:Storage Memory和Execution Memory,而且这两部分的边界由spark.memory.storageFraction参数设定,默认是0.5即50%。新的内存管理模型中的优点是,这个边界不是固定的,在内存压力下这个边界是可以移动的。如一个区域内存不够用时可以从另一区域借用内存。 下边来讨论如何移动及使用的:
1 | 1. Storage Memory.这部分内存即可以用来缓存spark数据也可以用来做unroll序列化数据的临时空间。广播变量以block的形式也存储在这里。你奇怪的是unroll,因为你可能会说,并不需要那么多空间去unroll block使其可用——在没有足够内存去unroll bolock的情况下,如果得到持久化级别的允许,将直接在这部分内存unroll block。至于广播变量,当它的持久化级别为MEMORY_AND_DISK时,就会缓存到此。 |
下边我们来说一下Storage Memory 和Execution Memory之间的边界移动。从Execution Memory的本质来看,你不能将这部分内存空间的数据挤出去,因为这部分内存的数据是用来计算的中间结果,如果计算过程找不到原来存到这的block数据任务就会失败。但是对于Storage Memory内存就不会这样,它只是用来缓存内存中数据,如果将里边的block数据驱逐出去,就会更新block 元数据映射信息使用到时告知该block被移除了,要想再拿到这些数据从HDD中读取即可(或者如果缓存级别没有溢写就重新计算)。
所以,我们只能Execution Memory可以向Storage Memory挤用空间,反之不可。那么当什么时候会发生Execution Memory 向Storage Memory挤用空间呢?有两种可能:
只要Storage Memory有可用空间,就可以增大Execution Memory 大小,减少Storage Memory 大小。
Storage Memory的空间大小已经超出了初始设定的大小,并且将这部分空间全部占用,在这种情况下就可以强制将从Storage Memory中移出Blocks,减少它的空间到初始大小。
反过来,在只有当Execution Memory空间有空余时,Storage Memory才可以向Execution Memory借用空间,也就是说Execution Memory只要不够用了就可以向Storage Memory挤占空间不管Storage Memory有没有空余,而Storage Memory只能当Execution Memory有空余时才要以借用不能抢占。
初始Storage Memory 大小:“Spark Memory” spark.memory.storageFraction = (“Java Heap” – “Reserved Memory”) spark.memory.fraction spark.memory.storageFraction。根据默认值,即(“Java Heap” – 300MB) 0.75 0.5 = (“Java Heap” – 300MB) 0.375. 如果Java Heap=4G,那么就有1423.5MB大小的Storage Memory空间。
这就意味着当我们使用Spark cacheu并加载全部数据到executor中时,至少要将Storage Memory大小等于默认初始值大小。因为当Storage Memory区域还没满时,Execution Memory区域已经膨胀大于其初始设定大小时,我们不能强制将Execution Memory抢占的空间数据驱逐,所以最终Storage Memory会变小。
希望这篇文章可以帮你更好的理解spark新的内存管理机制,并以此来应用。
https://www.cnblogs.com/dreamfly2016/p/5720526.html
降低cache操作的内存占比
spark中,堆内存又被划分成了两块儿,一块儿是专门用来给RDD的cache、persist操作进行RDD数据缓存用的;另外一块儿,就是我们刚才所说的,用来给spark算子函数的运行使用的,存放函数中自己创建的对象。默认情况下,给RDD cache操作的内存占比是0.6,即60%的内存都给了cache操作了。但是问题是,如果某些情况下cache占用的内存并不需要占用那么大,这个时候可以将其内存占比适当降低。怎么判断在什么时候调整RDD cache的内存占用比呢?其实通过Spark监控平台就可以看到Spark作业的运行情况了,如果发现task频繁的gc,就可以去调整cache的内存占用比了。通过SparkConf.set("spark.storage.memoryFraction","0.3")来设定。0.6 -> 0.5 -> 0.4 -> 0.2大家可以自己去调,然后观察spark作业的运行统计
针对该情况,大家可以 在 spark webui观察。
yarn 去运行的话,那么就通过yarn的界面,去查看你的spark作业的 运行统计。
很简单, 大家一层一层点击进去就好。
可以看到每个stage 的运行情况。 包括每个task的运行时间统计。gc时间。
如果发现gc太贫乏。时间太长,那么就可以适当调整这个比例。
降低cache操作的内存占比,大不了用persist 操作。选择一部分缓存的rdd数据写入磁盘,或者序列化的的方式。配合kryo序列化类。
减少rdd缓存的内存占用,降低cache操作内存占比。
对应的 算子函数的内存占比,就提升了。
这个时候,可能就减少minor gc 的频率,同时减少full gc的频率,对性能的 提升 有一定帮助的。
堆外内存和连接等待时长的调整
其实这两个参数主要是为了解决一些Spark作业运行时候出现的一些错误信息而进行调整的
- 堆外内存
a) 问题提出
有时候,如果你的spark作业处理的数据量特别特别大,几亿数据量;然后spark作业一运行就会出现类似shuffle file cannot find,executor、task lost,out of memory(内存溢出)等这样的错误。这是因为可能是说executor的堆外内存不太够用,导致executor在运行的过程中,可能会内存溢出;然后可能导致后续的stage的task在运行的时候,可能要从一些executor中去拉取shuffle map output文件,但是executor可能已经挂掉了,关联的blockmanager也没有了;所以可能会报shuffle output file not found;resubmitting task;executor lost 这样的错误;最终导致spark作业彻底崩溃。 上述情况下,就可以去考虑调节一下executor的堆外内存。也许就可以避免报错;此外,有时,堆外内存调节的比较大的时候,对于性能来说,也会带来一定的提升。
b) 解决方案:--conf spark.yarn.executor.memoryOverhead=2048
在spark-submit脚本里面添加如上配置。默认情况下,这个堆外内存上限大概是300多M;我们通常项目中真正处理大数据的时候,这里都会出现问题导致spark作业反复崩溃无法运行;此时就会去调节这个参数,到至少1G或者更大的内存。通常这个参数调节上去以后,就会避免掉某些OOM的异常问题,同时呢,会让整体spark作业的性能,得到较大的提升。 - 连接等待时长的调整
a) 问题提出:
由于JVM内存过小,导致频繁的Minor gc,有时候更会触犯full gc,一旦出发full gc;此时所有程序暂停,导致无法建立网络连接;spark默认的网络连接的超时时长是60s;如果卡住60s都无法建立连接的话,那么就宣告失败了。碰到一种情况,有时候报错信息会出现一串类似file id not found,file lost的错误。这种情况下,很有可能是task需要处理的那份数据的executor在正在进行gc。所以拉取数据的时候,建立不了连接。然后超过默认60s以后,直接宣告失败。几次都拉取不到数据的话,可能会导致spark作业的崩溃。也可能会导致DAGScheduler,反复提交几次stage。TaskScheduler,反复提交几次task。大大延长我们的spark作业的运行时间。
b) 解决方案:--conf spark.core.connection.ack.wait.timeout=300
在spark-submit脚本中添加如上参数,调节这个值比较大以后,通常来说,可以避免部分的偶尔出现的某某文件拉取失败,某某文件lost掉的错误。
查看gc
spark-env.sh:
JAVA_OPTS=” -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps”
https://www.cnblogs.com/jcchoiling/p/6494652.html
参考:
https://www.jianshu.com/p/e4557bf9186b
https://www.cnblogs.com/lifeone/p/6434356.html
https://www.cnblogs.com/dreamfly2016/p/5720180.html