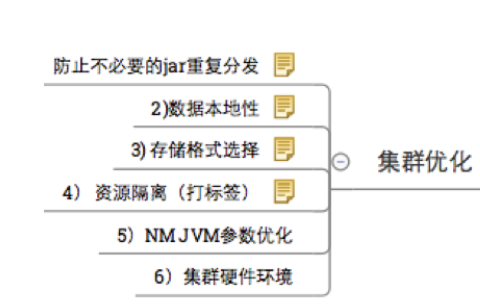
spark集群优化
数据本地性
如何配置Locality呢?可以统一采用spark.locality.wait来设置,默认3s(例如设置5000ms)。当然可以分别设置spark.locality.wait.process、spark.locality.wait.node、spark.locality.wait.rack等;1
2
3spark.locality.wait.process 进程内等待时间 3 3
spark.locality.wait.node 节点内等待时间 3 8
spark.locality.wait.rack 机架内等待时间 3 5
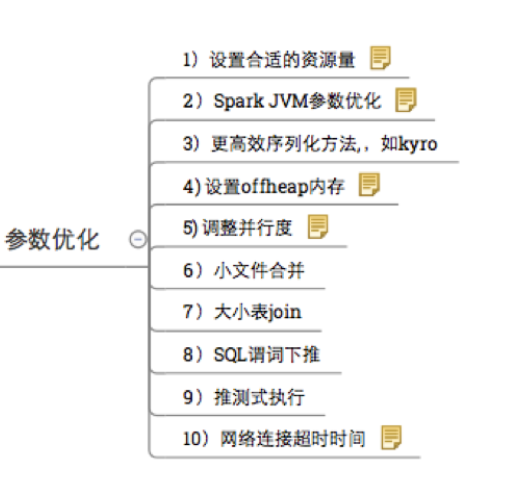
Spark参数优化
计算资源

1
2
3spark.executor.overhead.memory executor堆外内存 512m 1.5g
spark.executor.memory executor堆内存 1g 9g
spark.executor.cores executor拥有的core数 1 3
num-executors
参数说明:该参数用于设置Spark作业总共要用多少个Executor进程来执行。Driver在向YARN集群管理器申请资源时,YARN集群管理器会尽可能按照你的设置来在集群的各个工作节点上,启动相应数量的Executor进程。这个参数非常之重要,如果不设置的话,默认只会给你启动少量的Executor进程,此时你的Spark作业的运行速度是非常慢的。
参数调优建议:每个Spark作业的运行一般设置50~100个左右的Executor进程比较合适,设置太少或太多的Executor进程都不好。设置的太少,无法充分利用集群资源;设置的太多的话,大部分队列可能无法给予充分的资源。
executor-memory
参数说明:该参数用于设置每个Executor进程的内存。Executor内存的大小,很多时候直接决定了Spark作业的性能,而且跟常见的JVM OOM异常,也有直接的关联。
参数调优建议:每个Executor进程的内存设置4G~8G较为合适。但是这只是一个参考值,具体的设置还是得根据不同部门的资源队列来定。可以看看自己团队的资源队列的最大内存限制是多少,num-executors乘以executor-memory,是不能超过队列的最大内存量的。此外,如果你是跟团队里其他人共享这个资源队列,那么申请的内存量最好不要超过资源队列最大总内存的1/3~1/2,避免你自己的Spark作业占用了队列所有的资源,导致别的同学的作业无法运行。
每个executor进程所使用的内存数。默认值为“1g”。根据集群的硬件情况,应该把这个值设置为“4g”、“8g”、“16g”或者更高。
executor-cores
参数说明:该参数用于设置每个Executor进程的CPU core数量。这个参数决定了每个Executor进程并行执行task线程的能力。因为每个CPU core同一时间只能执行一个task线程,因此每个Executor进程的CPU core数量越多,越能够快速地执行完分配给自己的所有task线程。
参数调优建议:Executor的CPU core数量设置为2~4个较为合适。同样得根据不同部门的资源队列来定,可以看看自己的资源队列的最大CPU core限制是多少,再依据设置的Executor数量,来决定每个Executor进程可以分配到几个CPU core。同样建议,如果是跟他人共享这个队列,那么num-executors * executor-cores不要超过队列总CPU core的1/3~1/2左右比较合适,也是避免影响其他同学的作业运行。
driver-memory
参数说明:该参数用于设置Driver进程的内存。
参数调优建议:Driver的内存通常来说不设置,或者设置1G左右应该就够了。唯一需要注意的一点是,如果需要使用collect算子将RDD的数据全部拉取到Driver上进行处理,那么必须确保Driver的内存足够大,否则会出现OOM内存溢出的问题。
driver进程使用的总内存数。和内核数一样,建议根据你的应用及硬件情况,把这个值设置为“16g”或“32g”。默认”1g”。
spark.driver.cores
在集群模式下管理资源时,用于driver程序的CPU内核数量。默认为1。在生产环境的硬件上,这个值可能最少要上调到8或16。
spark.driver.maxResultSize
如果应用频繁用此driver程序,建议对这个值的设置高于其默认值“1g”。0表示没有限制。这个值反映了Spark action的全部分区中最大的结果集的大小。
spark.local.dir
这个看起来很简单,就是Spark用于写中间数据,如RDD Cache,Shuffle,Spill等数据的位置,那么有什么可以注意的呢。
首先,最基本的当然是我们可以配置多个路径(用逗号分隔)到多个磁盘上增加整体IO带宽,这个大家都知道。
其次,目前的实现中,Spark是通过对文件名采用hash算法分布到多个路径下的目录中去,如果你的存储设备有快有慢,比如SSD+HDD混合使用,那么你可以通过在SSD上配置更多的目录路径来增大它被Spark使用的比例,从而更好地利用SSD的IO带宽能力。当然这只是一种变通的方法,终极解决方案还是应该像目前HDFS的实现方向一样,让Spark能够感知具体的存储设备类型,针对性的使用。
需要注意的是,在Spark 1.0 以后,SPARK_LOCAL_DIRS(Standalone, Mesos) or LOCAL_DIRS (YARN)参数会覆盖这个配置。比如Spark On YARN的时候,Spark Executor的本地路径依赖于Yarn的配置,而不取决于这个参数。
spark.default.parallelism
一般为 executor_cores*num_executors 的 1~4 倍,系统默认值 64,不设置的话会导致 task 很多的时候被分批串行执行,或大量 cores 空闲,资源浪费严重。
该参数用于设置每个stage的默认task数量。这个参数极为重要,如果不设置可能会直接影响你的Spark作业性能。
spark.files.maxPartitionBytes = 128 M(默认)
代表着rdd的一个分区能存放数据的最大字节数,如果一个400m的文件,只分了两个区,则在action时会发生错误。当一个spark应用程序执行时,生成spark.context,同时会生成两个参数,由上面得到的spark.default.parallelism推导出这两个参数的值
1 | sc.defaultParallelism = spark.default.parallelism |
当sc.defaultParallelism和sc.defaultMinPartitions最终确认后,就可以推算rdd的分区数了。
spark.serializer
问题:序列化时间长、结果大
解决方案:
spark默认使用JDK 自带的ObjectOutputStream,这种方式产生的结果大、CPU处理时间长,可以通过设置spark.serializer为org.apache.spark.serializer.KeyoSerializer。
另外如果结果已经很大,那就最好使用广播变量方式了,结果你懂得。
spark.speculation
问题: 任务执行速度倾斜
解决方案:
如果数据倾斜,一般是partition key取得不好,可以考虑其他的并行处理方式,并在中间加上aggregation操作;如果是Worker倾斜,例如在某些Worker上的executor执行缓慢,可以通过设置spark.speculation=true 把那些持续慢的节点去掉;
1 | 使用场景: |
spark.cleaner.ttl
Spark记录任何对象的元数据的持续时间(按照秒来计算)。默认值设为“infinite”(无限),对长时间运行的job来说,可能会造成内存泄漏。适当地进行调整,最好先设置为3600,然后监控性能。
spark.executor.cores
每个executor的CPU核数。这个默认值基于选择的资源调度器。如果使用YARN或者Standalone集群模式,应该调整这个值
spark.akka.frameSize
Spark集群通信中最大消息的大小。当程序在带有上千个map及reduce任务的大数据集上运行时,应该把这个值从128调为512,或者更高。
spark.akka.threads
用于通信的Akka的线程数。对于运行多核的driver应用,推荐将这个属性值从4提高为16、32或更高
spark.cores.max
设置应用程序从集群所有节点请求的最大CPU内核数。如果程序在资源有限的环境下运行,应该把这个属性设置最大为集群中spark可用的CPU核数
offheap(executor)
1 | spark.executor.overhead.memory executor堆外内存 512 1.5g |
默认executor的0.1
spark.executor.logs.rolling.*
有四个属性用于设定及维护spark日志的滚动。当spark应用长周期运行时(超过24小时),应该设置这个属性
spark.python.worker.memory
如果使用python开发spark应用,这个属性将为每个python worker进程分配总内存数。默认值512m
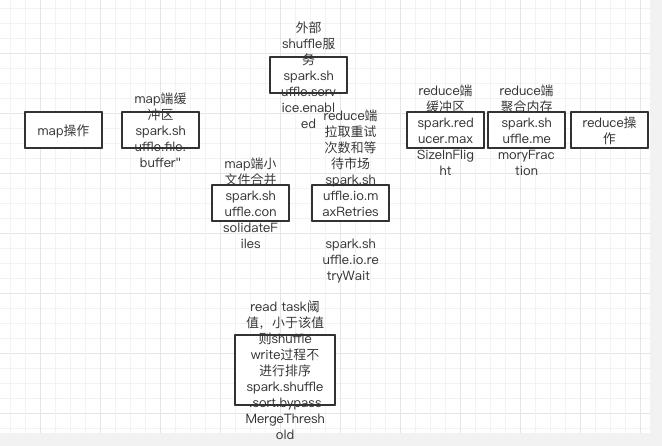
优化shuffle过程参数
1
2
3
4spark.rpc.askTimeout rpc超时时间 10 1000
spark.shuffle.sort.bypassMergeThreshold shuffle read task阈值,小于该值则shuffle write过程不进行排序 200 600
spark.shuffle.io.retryWait 每次重试拉取数据的等待间隔 5 30
spark.shuffle.io.maxRetries 拉取数据重试次数 3 10
1 | spark.shuffle.manager 默认sort |
其中spark.shuffle.file.buffer主要负责shuffle write过程写数据到磁盘过程的buffer,如果内存大的话建议提高该参数;spark.reducer.maxSizeInFlight负责shuffle read过程中reduce端机器从map端机器同时读取数据的大小。

spark.shuffle.manager
这是Spark里shuffle数据的实现方法,默认为“sort”。这里提到它是因为,如果应用使用Tungsten,应该把这个属性值设置为“Tungsten-sort”。
调节map端内存缓冲区
为什么要调节map端内存缓冲区
默认情况下,shuffle的map task,输出的文件到内存缓冲区,当内存缓冲区满了,才会溢写spill操作到磁盘,如果该缓冲区比较小,而map端输出文件又比较大,会频繁的出现溢写到磁盘,影响性能。
如何调整1
2//设置map 端内存缓冲区大小(默认32k)
conf.set("spark.shuffle.file.buffer", "64k");
调节reduce端内存占比
为什么要调节reduce端内存占比,reduce task 在进行汇聚,聚合等操作时,实际上使用的是自己对应的executor内存,默认情况下executor分配给reduce进行聚合的内存比例是0.2,如果拉取的文件比较大,会频繁溢写到本地磁盘,影响性能。1
2//设置reduce端内存占比
conf.set("spark.shuffle.memoryFraction", "0.4");
https://www.jianshu.com/p/069c37aad295
spark.shuffle.service.enabled
在Spark内开启外部的shuffle服务。如果需要调度动态分配,就必须设置这个属性。默认为false
spark.reducer.maxSizeInFlight
调节reduce端缓冲区大小避免OOM异常
为什么要调节reduce端缓冲区大小
对于map端不断产生的数据,reduce端会不断拉取一部分数据放入到缓冲区,进行聚合处理;
当map端数据特别大时,reduce端的task拉取数据是可能全部的缓冲区都满了,此时进行reduce聚合处理时创建大量的对象,导致OOM异常;
如何调节reduce端缓冲区大小
当由于以上的原型导致OOM异常出现是,可以通过减小reduce端缓冲区大小来避免OOM异常的出现
但是如果在内存充足的情况下,可以适当增大reduce端缓冲区大小,从而减少reduce端拉取数据的次数,提供性能。1
2//调节reduce端缓存的大小(默认48M)
conf.set("spark.reducer.maxSizeInFlight", "24");
解决JVM GC导致的shuffle文件拉取失败
问题描述
下一个stage的task去拉取上一个stage的task的输出文件时,如果正好上一个stage正处在full gc的情况下(所有线程后停止运行),它们之间是通过netty进行通信的,就会出现很长时间拉取不到数据,此时就会报shuffle file not found的错误;但是下一个stage又重新提交task就不会出现问题了。
如何解决
调节最大尝试拉取次数:spark.shuffle.io.maxRetries 默认为3次
调节每次拉取最大的等待时长:spark.shuffle.io.retryWait 默认为5秒1
2
3
4
5//调节拉取文件的最大尝试次数(默认3次)
conf.set("spark.shuffle.io.maxRetries", "60");
//调节每次拉取数据时最大等待时长(默认为5s)
conf.set("spark.shuffle.io.retryWait", "5s");
spark.shuffle.consolidateFiles为true
问题:map|reduce数量大,造成shuffle小文件数目多
解决方案:
通过设置spark.shuffle.consolidateFiles为true,来合并shuffle中间文件,此时文件数为reduce tasks数目;
开启map端输出文件的合并机制
为什么要开启map端输出文件的合并机制
默认情况下,map端的每个task会为reduce端的每个task生成一个输出文件,reduce段的每个task拉取map端每个task生成的相应文件
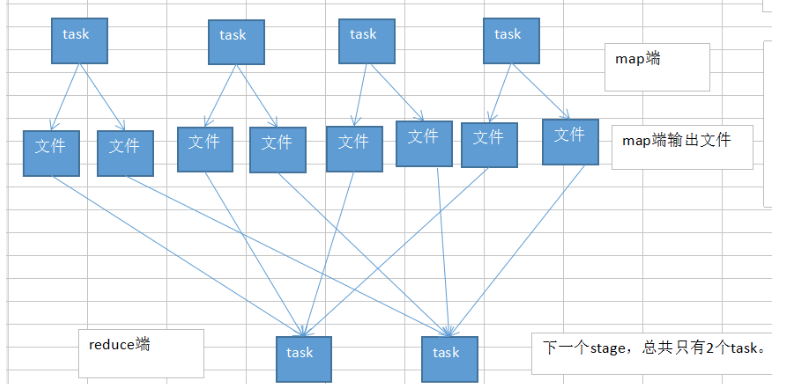
开启后,map端只会在并行执行的task生成reduce端task数目的文件,下一批map端的task执行时,会复用首次生成的文件
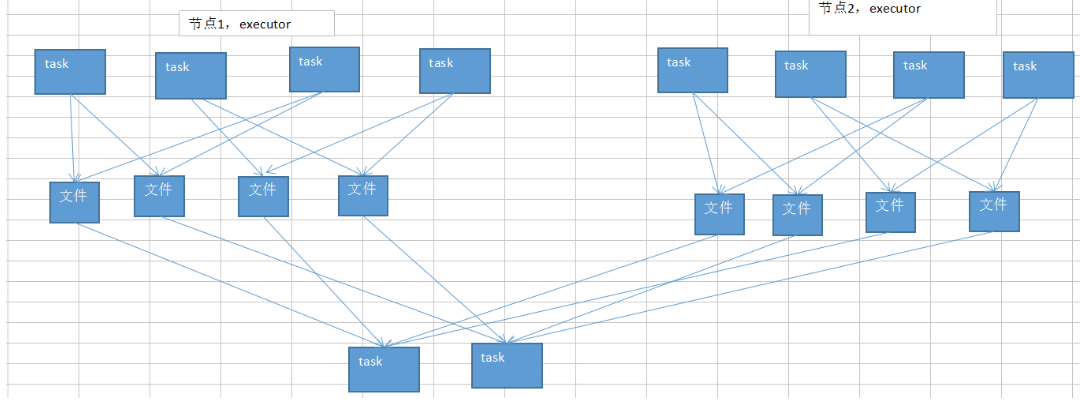
如何开启1
2//开启map端输出文件的合并机制
conf.set("spark.shuffle.consolidateFiles", "true");
修改shuffle管理器
有哪些shuffle管理器
HashShuffleManager:1.2.x版本前的默认选择
SortShuffleManager:1.2.x版本之后的默认选择,会对每个task要处理的数据进行排序;同时,可以避免像 HashShuffleManager那么默认去创建多份磁盘文件,而是一个task只会写入一个磁盘文件,不同reduce task需要的的数据使用offset来进行划分。
tungsten-sort(钨丝):1.5.x之后的出现,和SortShuffleManager相似,但是它本事实现了一套内存管理机制,性能有了很大的提高,而且避免了shuffle过程中产生大量的OOM、GC等相关问题。
如何选择
如果不需要排序,建议使用HashShuffleManager以提高性能
如果需要排序,建议使用SortShuffleManager
如果不需要排序,但是希望每个task输出的文件都合并到一个文件中,可以去调节bypassMergeThreshold这个阀值(默认为200),因为在合并文件的时候会进行排序,所以应该让该阀值大于reduce task数量。
如果需要排序,而且版本在1.5.x或者更高,可以尝试使用 tungsten-sort
在项目中如何使用
1 | //设置spark shuffle manager (hash,sort,tungsten-sort) |
yarn-cluster模式的JVM内存溢出无法执行的问题
问题描述
有些spark作业,在yarn-client模式下是可以运行的,但在yarn-cluster模式下,会报出JVM的PermGen(永久代)的内存溢出,OOM.
出现以上原因是:yarn-client模式下,driver运行在本地机器上,spark使用的JVM的PermGen的配置,是本地的默认配置128M;
但在yarn-cluster模式下,driver运行在集群的某个节点上,spark使用的JVM的PermGen是没有经过默认配置的,默认是82M,故有时会出现PermGen Out of Memory error log.
如何处理
在spark-submit脚本中设置PermGen--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -XX:MaxPermSize=256M"(最小128M,最大256M)
如果使用spark sql,sql中使用大量的or语句,可能会报出jvm stack overflow,jvm栈内存溢出,此时可以把复杂的sql简化为多个简单的sql进行处理即可。
checkpoint的使用
checkpoint的作用
默认持久化的Rdd会保存到内存或磁盘中,下次使用该Rdd时直接冲缓存中获取,不需要重新计算;如果内存或者磁盘中文件丢失,再次使用该Rdd时需要重新进行。
如果将持久化的Rdd进行checkpoint处理,会把内存写入到hdfs文件系统中,此时如果再次使用持久化的Rdd,但文件丢失后,会从hdfs中获取Rdd并重新进行缓存。
如何使用
首先设置checkpoint目录1
2//设置checkpoint目录
javaSparkContext.checkpointFile("hdfs://hadoop-senior.ibeifeng.com:8020/user/yanglin/spark/checkpoint/UserVisitSessionAnalyzeSpark");
将缓存后的Rdd进行checkpoint处理1
2//将缓存后的Rdd进行checkpoint
sessionRowPairRdd.checkpoint();
使用KryoSerializer进行序列化
使用KryoSerializer序列化的好处
默认情况,spark使用的是java的序列化机制,ObjectOutputStream / ObjectInputStream,对象输入输出流机制,来进行序列化。
该序列化的好处是方便使用,但必须实现Serializable接口,缺点是效率低,速度慢,序列化后的占用空间大
KryoSerializer序列化机制,效率高,速度快,占用空间小(只有java序列化的1/10),可以减少网络传输
使用方法1
2
3
4//配置使用KryoSerializer进行序列化
conf.set("spark.serializer","org.apache.spark.serializer.KryoSerializer")
//(为了使序列化效果达到最优)注册自定义的类型使KryoSerializer序列化
.registerKryoClasses(new Class[]{ExtractSession.class,FilterCount.class,SessionDetail.class,Task.class,Top10Session.class,Top10.class,VisitAggr.class});
使用KryoSerializer序列化的场景
算子函数中使用到的外部变量,使用KryoSerializer后,可以优化网络传输效率,优化集群中内存的占用和消耗
持久化Rdd,优化内存占用,task过程中创建对象,减少GC次数
shuffle过程,优化网络的传输性能1
2
3
4spark.kryo.classToRegister 当使用Kryo做对象序列化时,需要注册这些类。对于Kryo将序列化的应用所用的所有自定义对象,必须设置这些属性
spark.kryo.register 当自定义类需要扩展“KryoRegister”类接口时,用它代替上面的属性。
spark.rdd.compress 设置是否应当压缩序列化的RDD,默认false。但是和前面说过的一样,如果硬件充足,应该启用这个功能,因为这时的CPU性能损失可以忽略不计
spark.serializer 如果设置这个值,将使用Kryo序列化,而不是使用java的默认序列化方法。强烈推荐配置成Kryo序列化,因为这样可以获得最佳的性能,并改善程序的稳定性
将每个task中都使用的大的外部变量作为广播变量
没有使用广播变量的缺点
默认情况,task使用到了外部变量,每个task都会获取一份外部变量的副本,会占用不必要的内存消耗,导致在Rdd持久化时不能写入到内存,只能持久化到磁盘中,增加了IO读写操作。
同时,在task创建对象时,内存不足,进行频繁的GC操作,降低效率
使用广播变量的好处
广播变量不是每个task保存一份,而是每个executor保存一份。
广播变量初始化时,在Driver上生成一份副本,task运行时需要用到广播变量中的数据,首次使用会在本地的Executor对应的BlockManager中尝试获取变量副本;如果本地没有,那么就会从Driver远程拉取变量副本,并保存到本地的BlockManager中;此后这个Executor中的task使用到的数据都从本地的BlockManager中直接获取。
Executor中的BlockManager除了从远程的Driver中拉取变量副本,也可能从其他节点的BlockManager中拉取数据,距离越近越好。
将rdd进行持久化
持久化的原则
Rdd的架构重构和优化
尽量复用Rdd,差不多的Rdd进行抽象为一个公共的Rdd,供后面使用
公共Rdd一定要进行持久化
对应对次计算和使用的Rdd,一定要进行持久化
持久化是可以序列化的
首先采用纯内存的持久化方式,如果出现OOM异常,则采用纯内存+序列化的方法,如果依然存在OOM异常,使用内存+磁盘,以及内存+磁盘+序列化的方法
为了数据的高可靠性,而且内存充足时,可以使用双副本机制进行持久化
持久化的代码实现
.persist(StorageLevel.MEMORY_ONLY())
持久化等级
StorageLevel.MEMORY_ONLY() 纯内存 等效于 .cache()
序列化的:后缀带有_SER 如:StorageLevel.MEMORY_ONLY_SER() 内存+序列化
后缀带有_DISK 表示磁盘,如:MEMORY_AND_DISK() 内存+磁盘
后缀带有_2表示副本数,如:MEMORY_AND_DISK_2() 内存+磁盘且副本数为2
代码优化

collect输出大量结果时速度慢
解决方案:
collect源码中是把所有的结果以一个Array的方式放在内存中,可以直接输出到分布式的文件系统,然后查看文件系统中的内容;
repartition
问题: 通过多步骤的RDD操作后有很多空任务或者小任务产生
解决方案:
使用coalesce或者repartition去减少RDD中partition数量;
shuffle算子并行度调优
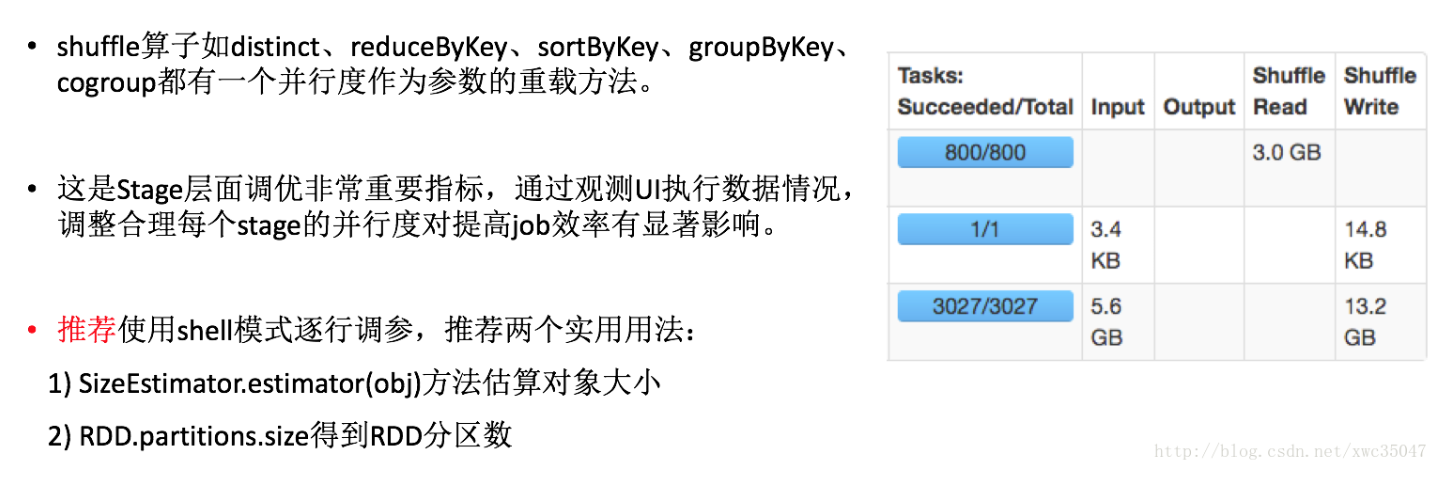
数据倾斜

优化数据结构

推荐使用dataset
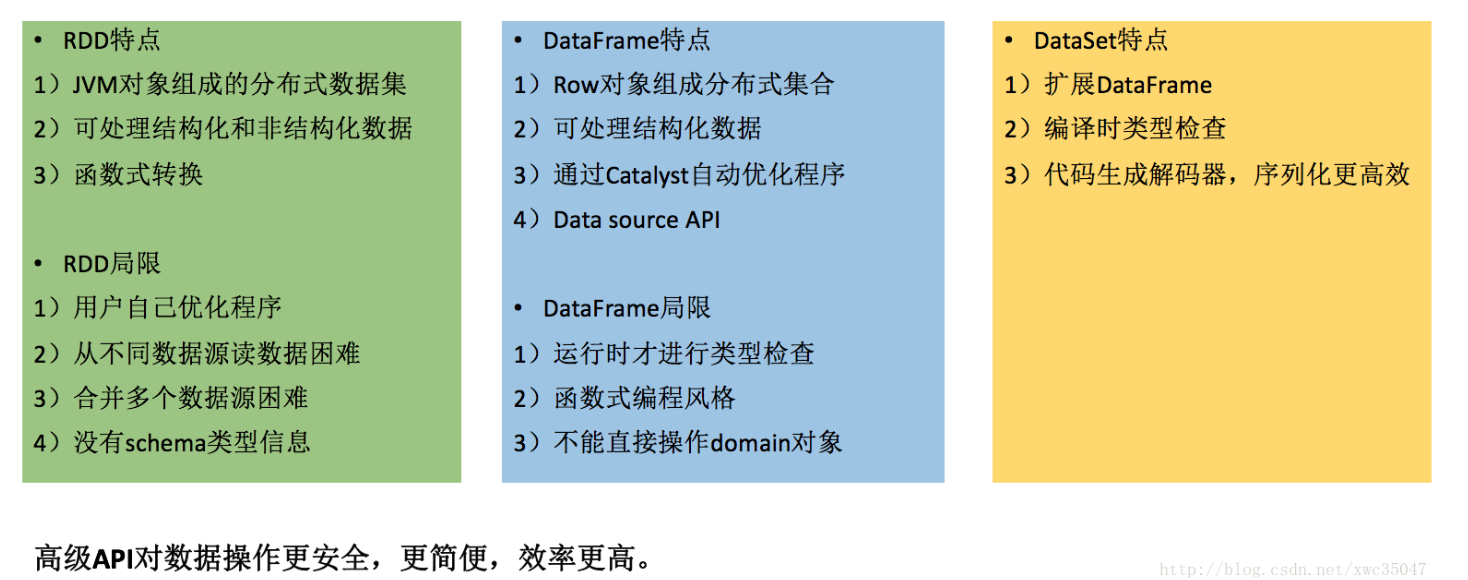
spark sql
spark.sql.shuffle.partitions
1 | spark.sql.shuffle.partitions 并发度 200 800 |

对于大SQL,提高该值显著提升执行效率和稳定性
大小表join
1 | spark.sql.autoBroadcastJoinThreshold 小表需要broadcast的大小阈值 10485760 33554432 |
默认10M
谓词下推
1 | spark.sql.orc.filterPushdown orc格式表是否谓词下推 false true |


spark.sql.files.openCostInBytes
该参数默认4M,表示小于4M的小文件会合并到一个分区中,用于减小小文件,防止太多单个小文件占一个分区情况。
存储格式选择
spark.sql.hive.convertCTAS默认为false,如果为true则表示用户创建的表使用parquet格式,下面测试不同数据格式建表的存储大小和查询时间记录
orc格式的存储效率最佳,查询时间性能也比较好。考虑开启参数,建表默认使用orc格式1
2spark.sql.hive.convertCTAS 创建表是否使用默认格式 false true
spark.sql.sources.default 默认数据源格式 parquet orc
spark.dynamicAllocation.enabled
该特性用于join操作,目的是实现无shuffle的join,不是对所有SQL有效,调整为true可开启该特性
spark.streaming
spark.streaming.concurrentJobs
问题:Spark Streaming吞吐量不高
可以设置spark.streaming.concurrentJobs
Spark Streaming 运行速度突然下降了,经常会有任务延迟和阻塞
解决方案:
这是因为我们设置job启动interval时间间隔太短了,导致每次job在指定时间无法正常执行完成,换句话说就是创建的windows窗口时间间隔太密集了;
GC调优
这里根据调研,有效的参数主要是InitiatingHeapOccupancyPercent,表示ConcGCThreads和G1HeapRegionSize。
推荐35,15,4
executor的stdout、stderr日志在集群本地,当出问题时,可以到相应的节点查询,当然从web ui上也可以直接看到。
executor除了stdout、stderr日志,我们可以把gc日志打印出来,便于我们对jvm的内存和gc进行调试。1
--conf spark.executor.extraJavaOptions="-XX:+PrintGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintHeapAtGC -XX:+PrintGCApplicationConcurrentTime -Xloggc:gc.log"
除了executor的日志,nodemanager的日志也会给我们一些帮助,比如因为超出内存上限被kill、资源抢占被kill等原因都能看到。
除此之外,spark am的日志也会给我们一些帮助,从yarn的application页面可以直接看到am所在节点和log链接。1
2
3
4
5
6
7
8
9./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \
参考:
https://blog.csdn.net/stark_summer/article/details/42981201
https://www.cnblogs.com/lifeone/p/6428885.html
https://www.cnblogs.com/lifeone/p/6434840.html
https://www.jianshu.com/p/da7d5edfb61f
https://blog.csdn.net/xwc35047/article/details/71039830
https://www.cnblogs.com/dreamfly2016/p/5720526.html