sortByKey
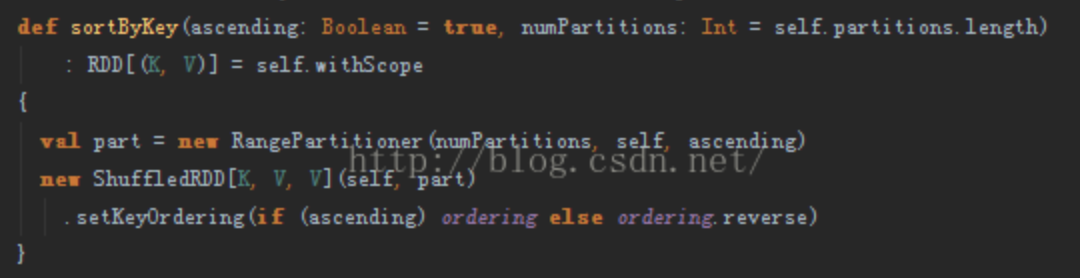
该函数会对原始RDD中的数据进行Shuffle操作,从而实现排序。
这个函数中,传入两个參数,ascending表示是升序还是降序,默认true表示升序.
第二个參数是运行排序使用的partition的个数,默认是当前RDD的partition个数.
groupByKey、reduceByKey与sortByKey
groupByKey把相同的key的数据分组到一个集合序列当中:
[(“hello”,1), (“world”,1), (“hello”,1), (“fly”,1), (“hello”,1), (“world”,1)] –> [(“hello”,(1,1,1)),(“word”,(1,1)),(“fly”,(1))]
reduceByKey把相同的key的数据聚合到一起并进行相应的计算:
[(“hello”,1), (“world”,1), (“hello”,1), (“fly”,1), (“hello”,1), (“world”,1)] add–> [(“hello”,3),(“word”,2),(“fly”,1)]
sortByKey按key的大小排序,默认为升序排序:
[(3,”hello”),(2,”word”),(1,”fly”)] –> [(1,”fly”),(2,”word”),(3,”hello”)]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39 from pyspark import SparkConf, SparkContext
from operator import add
conf = SparkConf()
sc = SparkContext(conf=conf)
def func_by_key():
data = [
"hello world", "hello fly", "hello world",
"hello fly", "hello fly", "hello fly"
]
data_rdd = sc.parallelize(data)
word_rdd = data_rdd.flatMap(lambda s: s.split(" ")).map(lambda x: (x, 1))
group_by_key_rdd = word_rdd.groupByKey()
print("groupByKey:{}".format(group_by_key_rdd.mapValues(list).collect()))
print("groupByKey mapValues(len):{}".format(
group_by_key_rdd.mapValues(len).collect()
))
reduce_by_key_rdd = word_rdd.reduceByKey(add)
print("reduceByKey:{}".format(reduce_by_key_rdd.collect()))
print("sortByKey:{}".format(reduce_by_key_rdd.map(
lambda x: (x[1], x[0])
).sortByKey().map(lambda x: (x[0], x[1])).collect()))
func_by_key()
sc.stop()
"""
result:
groupByKey:[('fly', [1, 1, 1, 1]), ('world', [1, 1]), ('hello', [1, 1, 1, 1, 1, 1])]
groupByKey mapValues(len):[('fly', 4), ('world', 2), ('hello', 6)]
reduceByKey:[('fly', 4), ('world', 2), ('hello', 6)]
sortByKey:[(2, 'world'), (4, 'fly'), (6, 'hello')]
"""
从结果可以看出,groupByKey对分组后的每个key的value做mapValues(len)后的结果与reduceByKey的结果一致,即:如果分组后要对每一个key所对应的值进行操作则应直接用reduceByKey;sortByKey是按key排序,如果要对value排序,可以交换key与value的位置,再排序。
https://www.cnblogs.com/FG123/p/9746830.html