rcfile
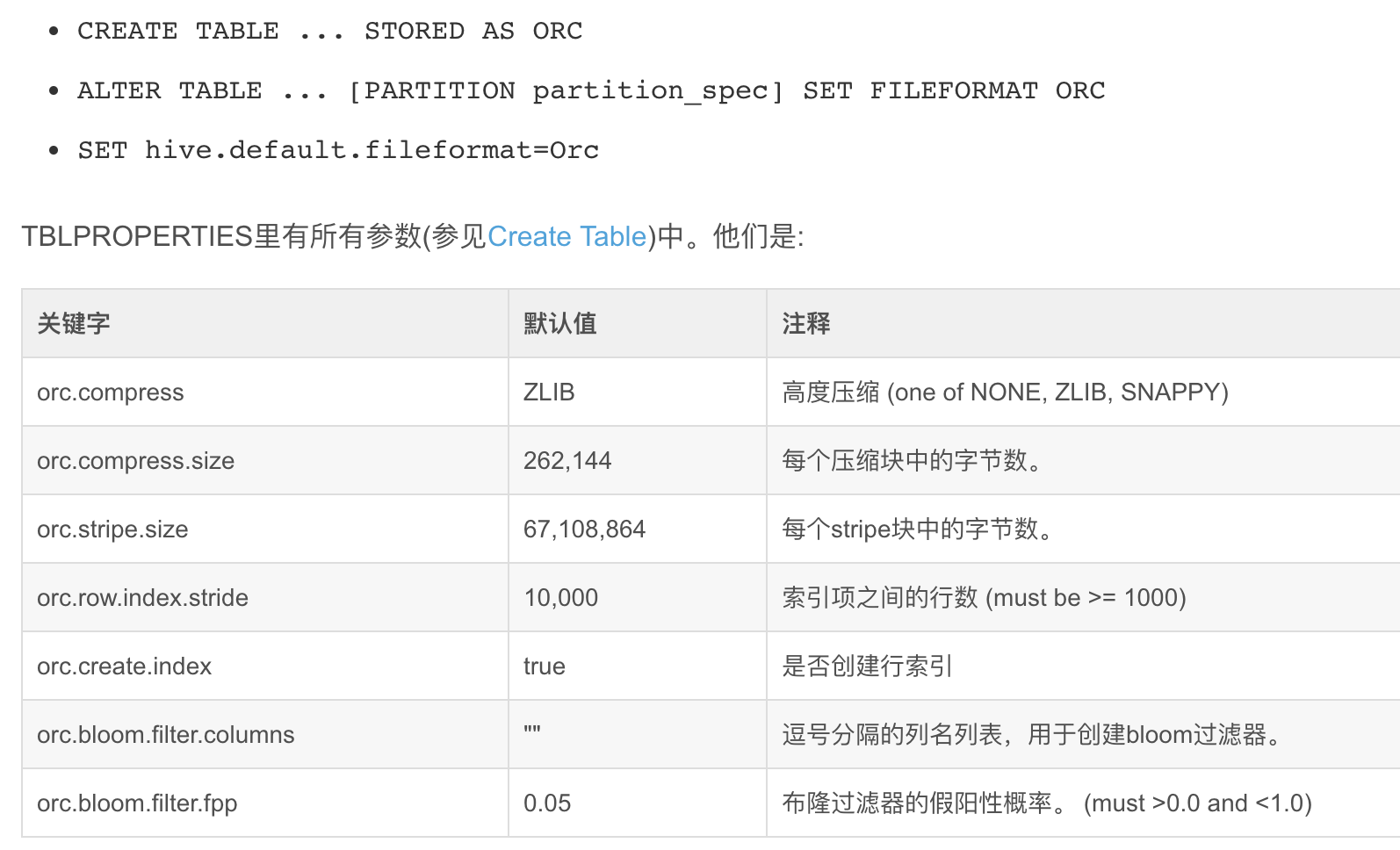
在传统的数据库系统中,主要有三种数据存储方式:
水平的行存储结构: 行存储模式就是把一整行存在一起,包含所有的列,这是最常见的模式。这种结构能很好的适应动态的查询,比如 select a from tableA 和 select a, b, c, d, e, f, g from tableA 这样两个查询其实查询的开销差不多,都需要把所有的行读进来过一遍,拿出需要的列。而且这种情况下,属于同一行的数据都在同一个 HDFS 块上,重建一行数据的成本比较低。但是这样做有两个主要的弱点:a)当一行中有很多列,而我们只需要其中很少的几列时,我们也不得不把一行中所有的列读进来,然后从中取出一些列。这样大大降低了查询执行的效率。b)基于多个列做压缩时,由于不同的列数据类型和取值范围不同,压缩比不会太高。
垂直的列存储结构: 列存储是将每列单独存储或者将某几个列作为列组存在一起。列存储在执行查询时可以避免读取不必要的列。而且一般同列的数据类型一致,取值范围相对多列混合更小,在这种情况下压缩数据能达到比较高的压缩比。但是这种结构在重建出行时比较费劲,尤其适当一行的多个列不在一个 HDFS 块上的时候。 比如我们从第一个 DataNode 上拿到 column A,从第二个 DataNode 上拿到了 column B,又从第三个 DataNode 上拿到了 column C,当要把 A,B,C 拼成一行时,就需要把这三个列放到一起重建出行,需要比较大的网络开销和运算开销。
混合的 PAX 存储结构: PAX 结构是将行存储和列存储混合使用的一种结构,主要是传统数据库中提高 CPU 缓存利用率的一种方法,并不能直接用到 HDFS 中。但是 RCFile 也是继承自它的思想,先按行存再按列存。
RCFile 的设计理念是“ first horizontally-partition, then vertically-partition”,这使得 RCFile 同时具有 Row-Store 和 Column-Store 两者的所有优势。RCFile 的主要特点是:
1). 保证数据记录的所有字段都在集群中同一个节点上;
2). 集群节点上每一列数据单独压缩,使得 RCFile 的数据压缩率非常高;
3). 在数据读取的时候只读取需要使用的数据列,不使用的数据列永远不会去读取。
在每一个 HDFS block 中,RCFile 以 Row-Group 的形式组织和管理数据,一个 HDFS block 可包含 Row-Group 的数量取决于 Row-Group 和 HDFS block 的大小。在 RCFile 中同一个表的所有 Row-Group 具有相同的大小。
每个 Row-Group 由三个数据段组成。
1). 第一个数据段是一个同步标志,它放在 Row-Group 的开头,RCFile 使用同步标志来隔离 HDFS block 中两个连续的 Row-Group;
2). 第二个数据段是 Row-Group 的元数据头部信息,Row-Group 里数据记录的数量、每个数据列占用多少字节、每个数据列的每个字段占用多少字节等等信息都保存在这里;
3). 第三个数据段是表数据段,表数据段采用 Column-Store 的方式组织数据,在表数据段里,同一列的所有字段被连续的存储在一起。
数据的布局: 首先根据 HDFS 的结构,一个表可以由多个 HDFS 块构成。在每个 HDFS 块中,RCFile 以 row group 为基本单位组织数据,一个表多所有 row group 大小一致,一个 HDFS 块中可以包含多个 row group。每个 row group 包含三个部分,第一部分是 sync marker,用来区分一个 HDFS 块中两个连续多 row group。第二部分是 row group 的 metadata header,记录每个 row group 中有多少行数据,每个列数据有多少字节,以及每列一行数据的字节数。第三部分就是 row group 中的实际数据,这里是按列存储的。
数据的压缩: 在 metadata header 部分用 RLE (Run Length Encoding) 方法压缩,因为对于记录每个列数据中一行数据的字节数是一样的,这些数字重复连续出现,因此用这种方法压缩比比较高。在压缩实际数据时,每列单独压缩。
数据的追加写: RCFile 会在内存里维护每个列的数据,叫 column holder,当一条记录加入时,首先会被打散成多个列,人后追加到每列对应的 column holder,同时更新 metadata header 部分。可以通过记录数或者缓冲区大小控制内存中 column holder 的大小。当记录数或缓冲大小超过限制,就会先压缩 metadata header,再压缩 column holder,然后写到 HDFS。
数据的读取和惰性解压(lazy decompression): RCFile 在处理一个 row group 时,只会读取 metadata header 和需要的列,合理利用列存储在 I/O 方面的优势。而且即使在查询中出现的列技术读进内存也不一定会被解压缩,只有但确定该列数据需要用时才会去解压,也就是惰性解压(lazy decompression)。例如对于 select a from tableA where b = 1,会先解压 b 列,如果对于整个 row group 中的 b 列,值都不为 1,那么就没必要对这个 row group 对 a 列去解压,因为整个 row group 都跳过了。
row group 的大小: row group 太小肯定是不能充分发挥列存储的优势,但是太大也会有问题。首先,论文中实验指出,当 row group 超过某一阈值时,很难再获得更高当压缩比。其次,row group 太大会降低 lazy decompression 带来的益处,还是拿 select a from tableA where b = 1 来说,如果一个 row group 里有一行 b = 1,我们还是要解压 a 列,从而根据 metadata header 中的信息找到 b = 1 的那行的 a 列的值,如果此时我们把 row group 设小一点,假设就设成 1,这样对于 b <> 1 的行都不需要解压 a 列。最后论文中给出一个一般性的建议,建议将 row group 设成 4MB。
ORCfile
ORC(OptimizedRC File)存储源自于RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎,对schema演化(修改schema需要重新生成数据)支持较差,而ORC是对RC改进,但它仍对schema演化支持较差,主要是在压缩编码,查询性能方面做了优化。RC/ORC最初是在Hive中得到使用,最后发展势头不错,独立成一个单独的项目。Hive 1.x版本对事务和update操作的支持,便是基于ORC实现的(其他存储格式暂不支持)。ORC发展到今天,已经具备一些非常高级的feature,比如支持update操作,支持ACID,支持struct,array复杂类型。你可以使用复杂类型构建一个类似于parquet的嵌套式数据架构,但当层数非常多时,写起来非常麻烦和复杂,而parquet提供的schema表达方式更容易表示出多级嵌套的数据类型。
ORC File包含一组组的行数据,称为stripes,除此之外,ORC File的file footer还包含一些额外的辅助信息。在ORC File文件的最后,有一个被称为postscript的区,它主要是用来存储压缩参数及压缩页脚的大小。
在默认情况下,一个stripe的大小为250MB。大尺寸的stripes使得从HDFS读数据更高效。
在file footer里面包含了该ORC File文件中stripes的信息,每个stripe中有多少行,以及每列的数据类型。当然,它里面还包含了列级别的一些聚合的结果,比如:count, min, max, and sum。这里贴一下文档上的图:
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于之前的rcfile里的RowGroup概念,不过大小由4MB->250MB,这样应该能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
每个Stripe都包含index data、row data以及stripe footer,Stripe footer包含流位置的目录:
1,Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset,据说还包括每个Column的max和min值,具体没细看代码。
2,Row Data:存的是具体的数据,和RCfile一样,先取部分行,然后对这些行按列进行存储。与RCfile不同的地方在于每个列进行了编码,分成多个Stream来存储,具体如何编码在下一篇解析里会讲。
3,Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
ORCFILE主要特点:
混合存储结构,先按行存储,一组行数据叫stripes,stripes内部按列式存储。
支持各种复杂的数据类型,比如: datetime, decimal, 以及一些复杂类型(struct, list, map, and union);
在文件中存储了一些轻量级的索引数据;
基于数据类型的块模式压缩:
a、integer类型的列用行程长度编码(run-length encoding)
b、String类型的列用字典编码(dictionary encoding);
如上图所示,ORC文件中的每个strip都包含Index data,Row data和一个stripe footer。
stripe footer包含一个流位置目录。Row data用于表扫描。
Index data包括每个列的最小值和最大值,以及每个列中的行位置。(还可能包含一些字段或bloom过滤器。) 行索引项提供了偏移量可以找到正确的压缩块和在解压缩块后的字节。注意,ORC索引仅用于选择stripe footer和Row data,而不用于相应查询。
针对相对频繁的行索引使用,允许使用stripe可以进行多行跳过操作,从而实现快速读取,尽管有较大的条带大小。默认情况下,可以跳过10,000行。
由于基于谓词的筛选能够跳过大量行集,对一个表您可以在其第二主键上进行排序,从而大大减少执行时间。例如,如果主分区是事务日期,则可以根据状态、编码和姓氏对表进行排序。然后一次记录查找将跳过所有其他查询的记录。
https://www.cnblogs.com/xianhan/p/7149490.html
参考:
http://lxw1234.com/archives/2016/04/630.htm
https://blog.csdn.net/dabokele/article/details/51542327
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
http://www.360doc.com/content/15/0526/16/20466010_473411459.shtml
https://blog.csdn.net/maizi1045/article/details/79667857