Jobtracker是hadoop1.x中的组件,它的功能相当于:
Resourcemanager+MRAppMaster
TaskTracker 相当于:
Nodemanager + yarnchild
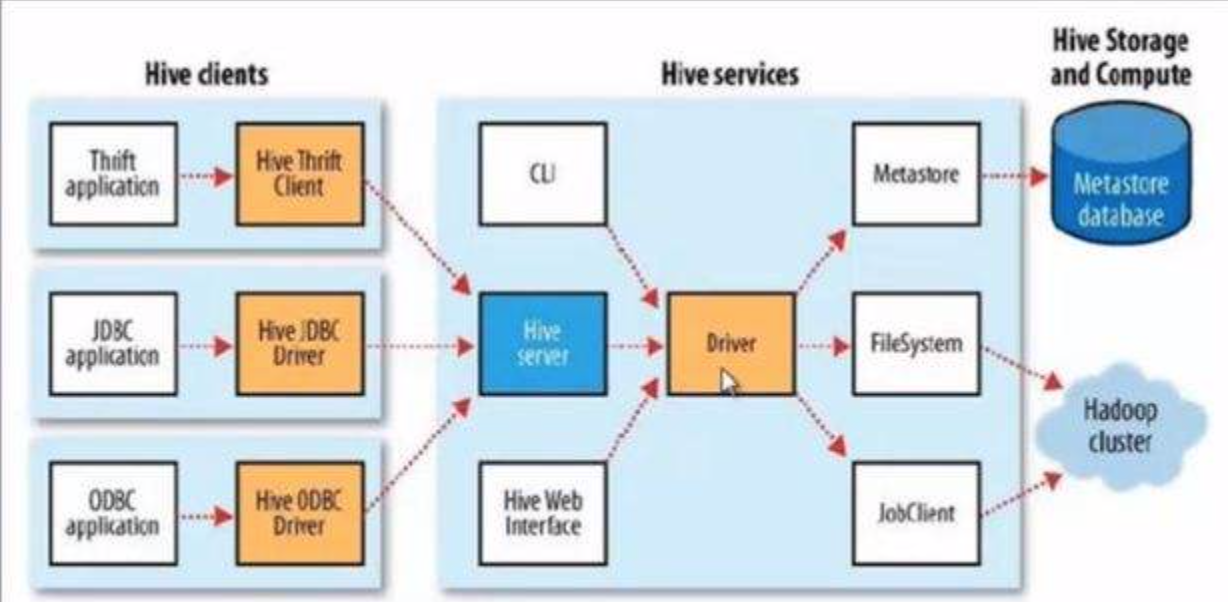
hive里面有两种服务模式
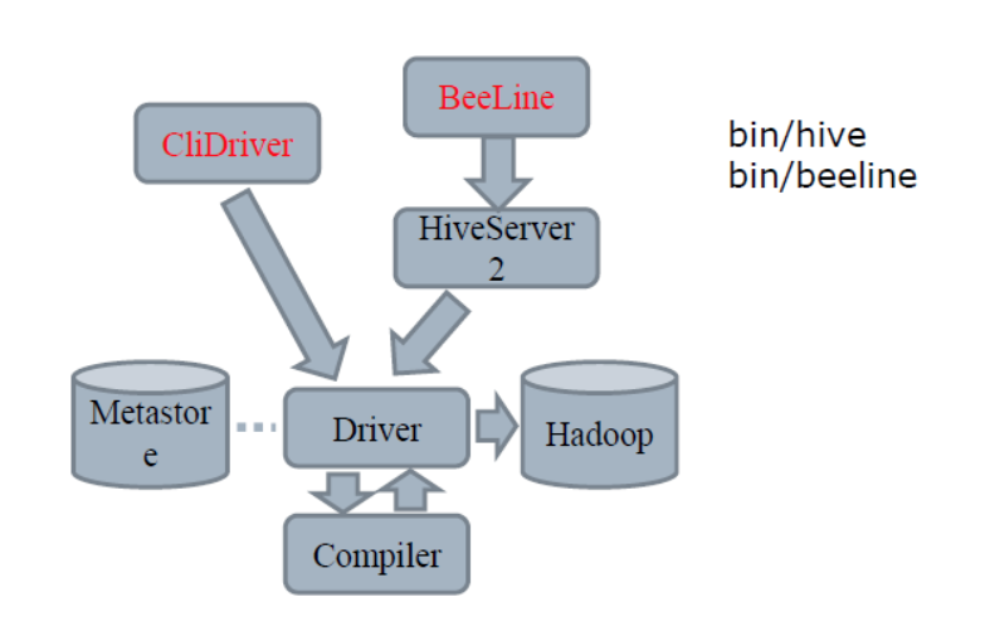
一种是cli模式,一种是hiveserver2,分别对应的启动入口
cli:hive-cli/org.apache.hadoop.hive.cli.CliDriver.java
hiveserver2:hiveservice/org.apache.hive.service.server.HiveServer2.java,直接用debug或者run运行调试
hive sql 的执行顺序
from… where…. group by… select…having … order by…
源码
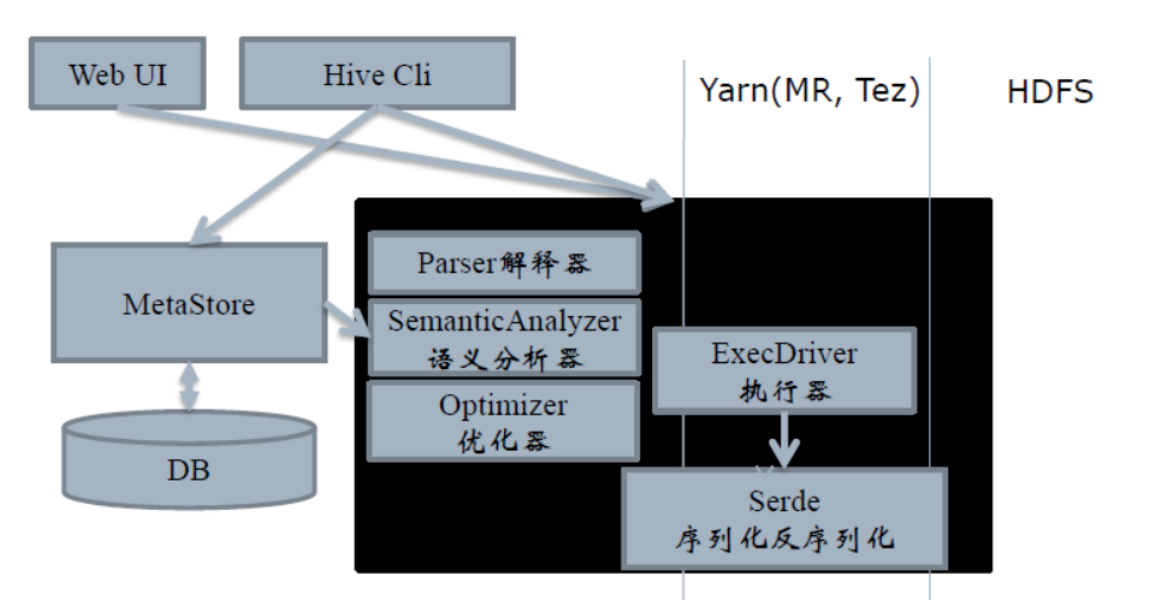
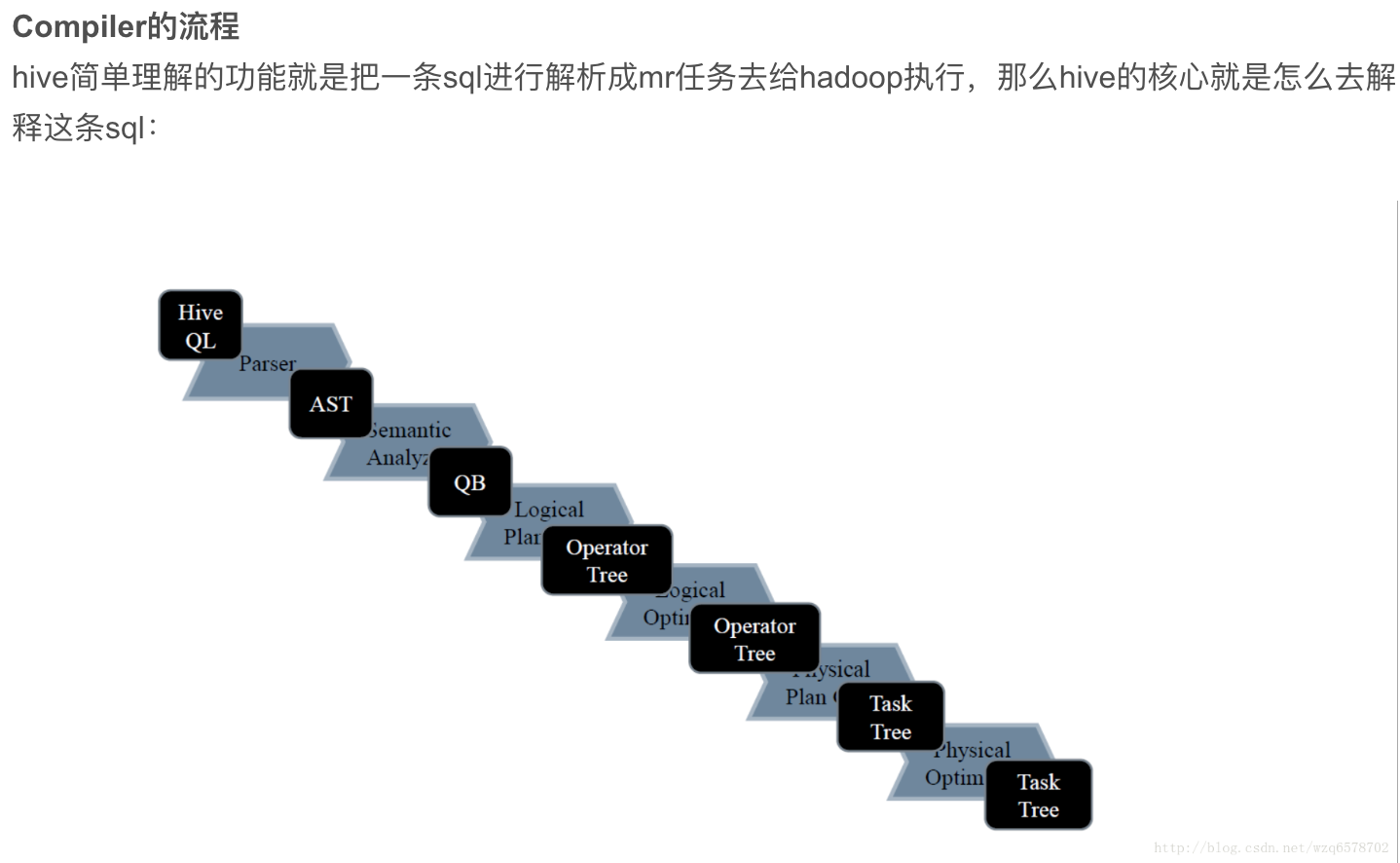
compiler包括parser解释器和SemanticAnalyzer语义解析器。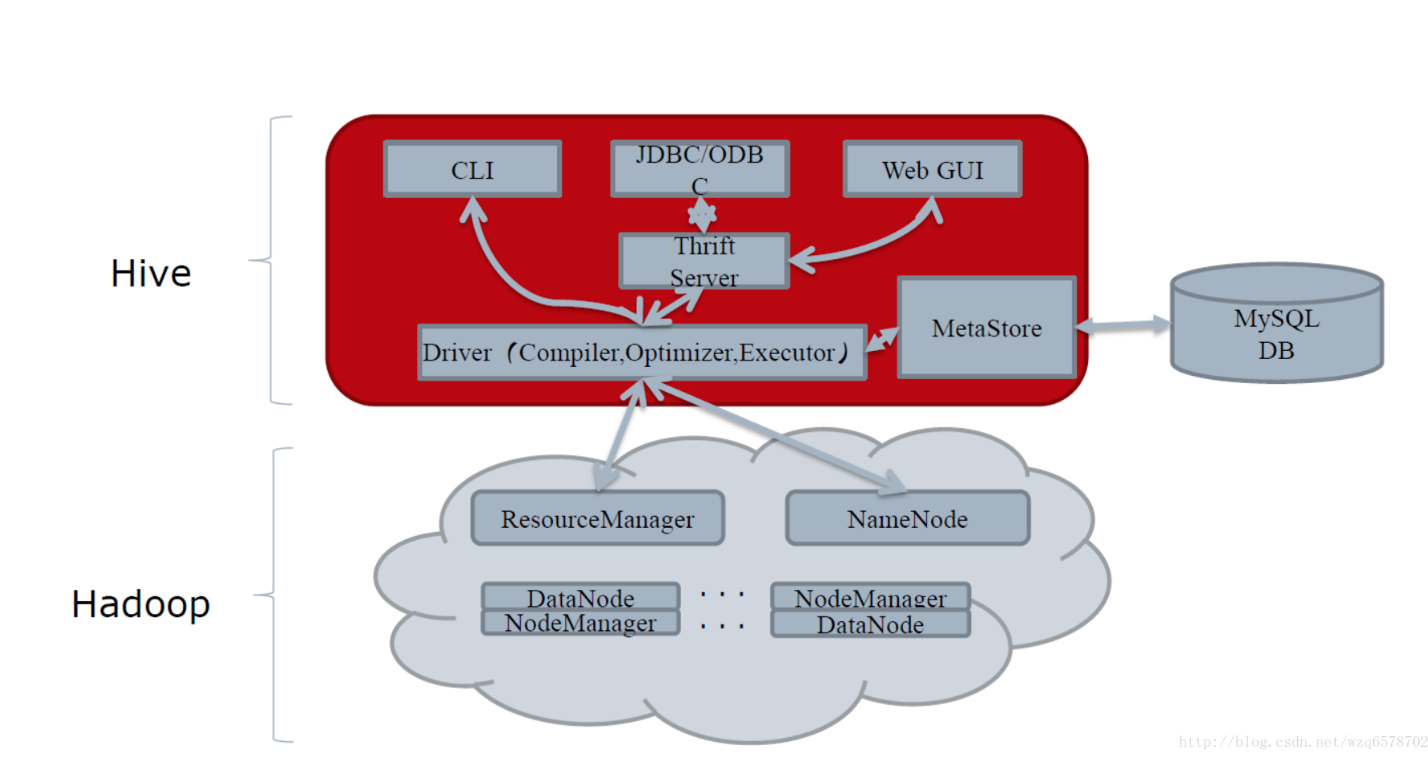
无论使用CLI、Thrift Server、JDBC还是自定义的提交工具,最终的HQL都会传给Driver实例,执行Driver.run()方法。从这种设计也可以看出,如果您要开发一套自定义的Hive作业提交工具,最好的方式是引用Driver实例,调用相关方法进行开发。
而Driver.run()方法,获得了这样一个HQL,则会执行两个重要的步骤:编译和执行,即Driver.complie()和Driver.execute()。对于Driver.comile()来说,其实就是调用parse和optimizer包中的相关模块,执行语法解析、语义分析、优化;对于Driver.run()来说,其实就是调用exec包中的相关模块,将解析后的执行计划执行,如果解析后的结果是一个查询计划,那么通常的作法就是提交一系列的MapReduce作业。
以查询的执行为例,整个Hive的流程是非常简单的一条直线,由上到下进行。

Join操作左边为小表
应该将条目少的表/子查询放在 Join 操作符的左边
原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率
参考:
https://blog.csdn.net/dante_003/article/details/73789910
https://www.jianshu.com/p/892cc8985c9c
https://blog.csdn.net/wf1982/article/details/9122543
https://blog.csdn.net/wzq6578702/article/details/71250081