首先是有如下数据,设定左边是右边的儿子,右边是左边的父母
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma
要求输出如下所示的爷孙关系,左边是右边的孙子,右边是左边的祖父母:
Tom Jesse
Tom Alice
Jone Jesse
Jone Alice
Jone Ben
Jone Mary
Tom Ben
Tom Mary
Philip Alice
Philip Jesse
Mark Alice
Mark Jesse
要利用Mapreduce解决这个问题,主要思想如下:
1、在Map阶段,将父子关系与相反的子父关系,同时在各个value前补上前缀-与+标识此key-value中的value是正序还是逆序产生的,之后进入context。
下图通过其中的Jone-Lucy Lucy-Mary,求解出Jone-Mary来举例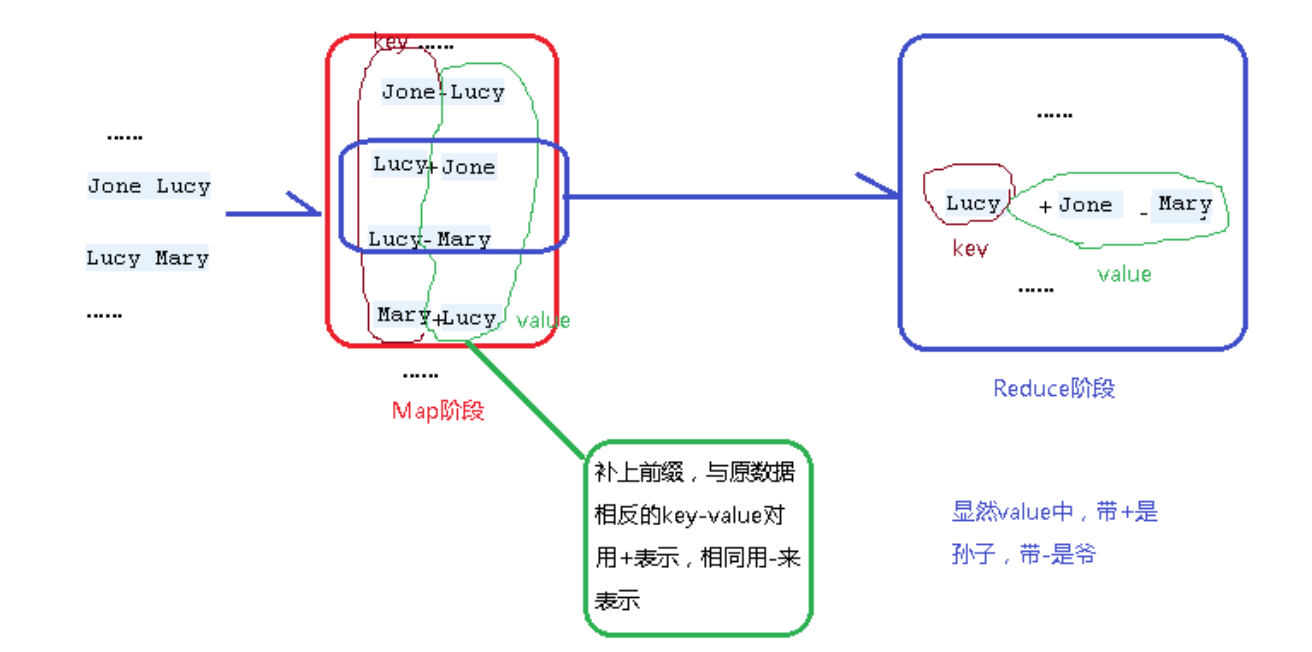
2、MapReduce会自动将同一个key的不同的value值,组合在一起,推到Reduce阶段。在value数组中,跟住前缀,我们可以轻松得知,哪个是爷,哪个是孙。
因此对各个values数组中各个项的前缀进行输出。
可以看得出,整个过程Key一直被作为连接的桥梁来用。形成一个单表关联的运算。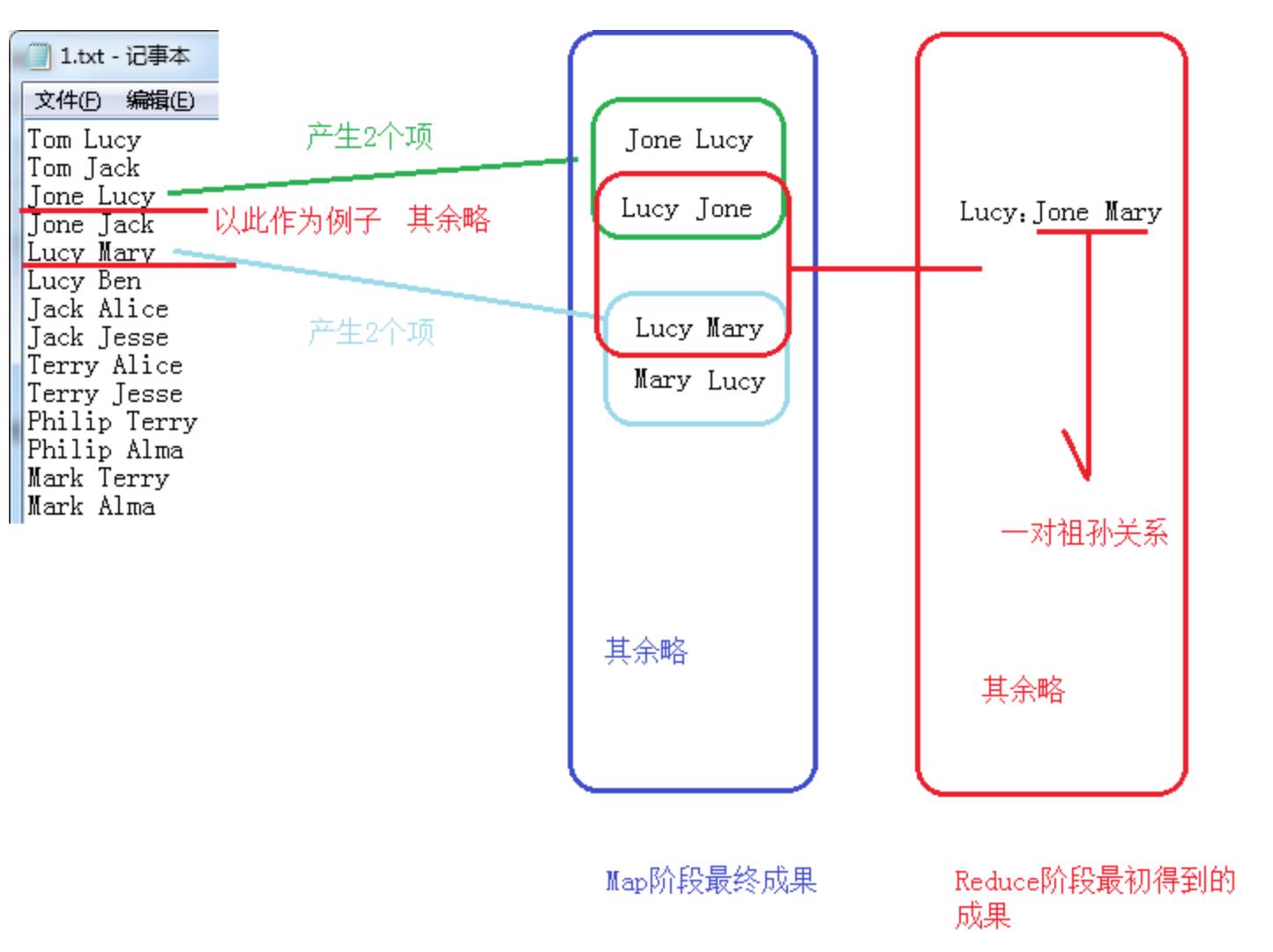
因此代码如下,根据上面的思想很容易得出如下的代码了,需要注意的是,输出流输入流都要设置成Text,因为全程都是在对Text而不是IntWritable进行操作:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60package com.qr.mr.Grandson;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/**
* 求祖父母,外祖父母四个人,或者更多人
*/
public class GrandChildren {
public static class Map extends Mapper<Object,Text,Text, Text> {
public void map(Object key,Text value,Context context) throws IOException, InterruptedException {
String[] record = value.toString().split(" ");
context.write(new Text(record[0]),new Text(record[1]+",Father"));
context.write(new Text(record[1]),new Text(record[0]+",Son"));
}
}
public static class Reduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key,Iterable<Text> values,Context context) throws IOException, InterruptedException {
List<String> grandpa = new ArrayList<>();
List<String> grandson = new ArrayList<>();
for (Text v:values) {
if (v.toString().contains("Father")){
grandpa.add(v.toString().split(",")[0]);
} else if (v.toString().contains("Son")){
grandson.add(v.toString().split(",")[0]);
}
}
for (String s:grandson) {
for (String g:grandpa) {
context.write(new Text(s),new Text(g));
}
}
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf,"Grandson");
job.setJarByClass(GrandChildren.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job,new Path("/Users/lifei/qrproject/hiveudf/src/main/java/com/qr/mr/Grandson/in"));
FileOutputFormat.setOutputPath(job,new Path("/Users/lifei/qrproject/hiveudf/src/main/java/com/qr/mr/Grandson/out"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}