题意
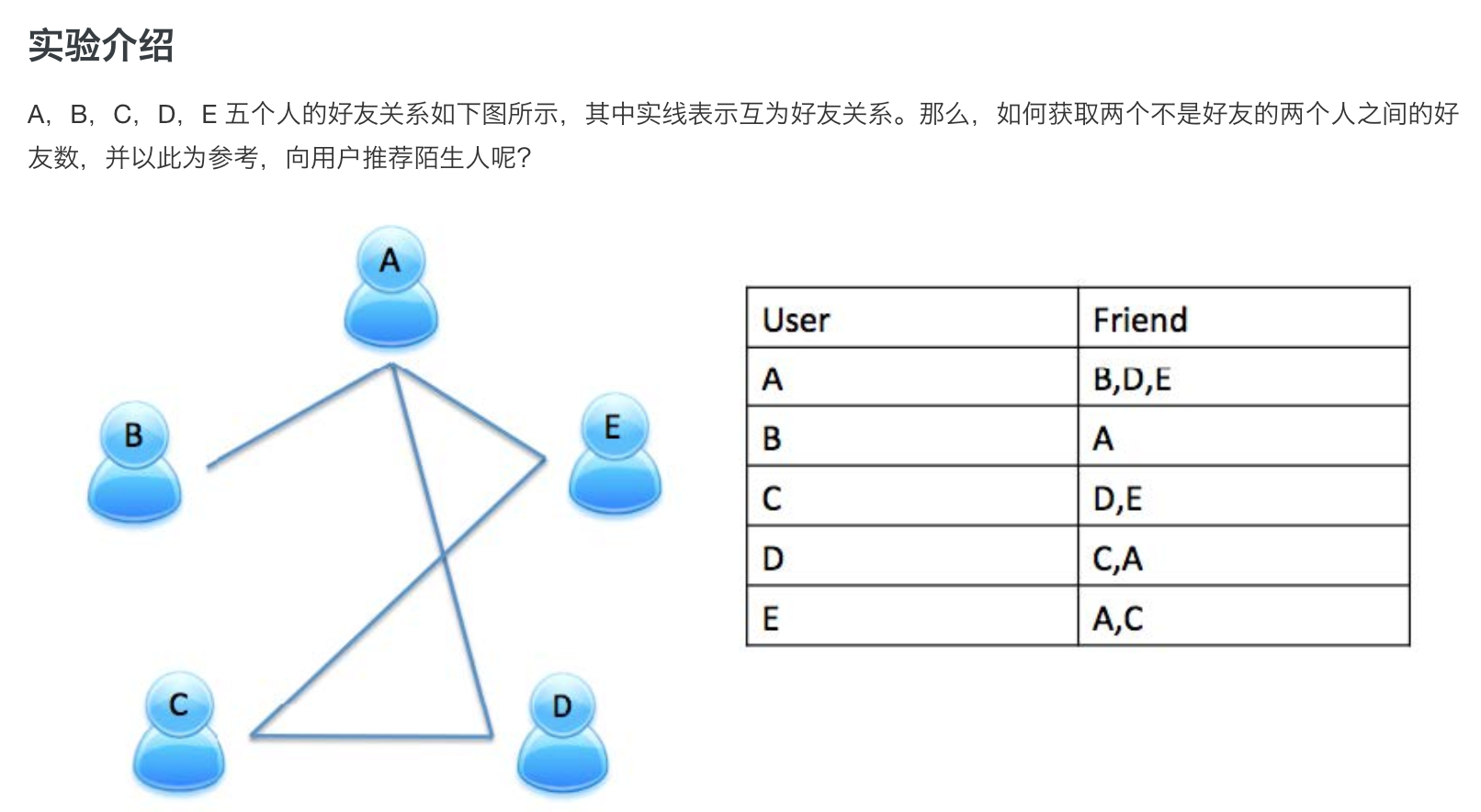
给出A-O个人中每个人的好友列表,求出哪些人两两之间有共同好友,以及他们的共同好友都有谁
原始文件:
A:B,C,D,F,E,O
B:A,C,E,K
C:F,A,D,I
D:A,E,F,L
E:B,C,D,M,L
F:A,B,C,D,E,O,M
G:A,C,D,E,F
H:A,C,D,E,O
I:A,O
J:B,O
K:A,C,D
L:D,E,F
M:E,F,G
O:A,H,I,J
输出格式:
A-B: C,E
…
解法一
此题旨在求两人之间的共同好友,原信息是<人,该人的所有好友>,因此首先以好友为键,人为值,交给reduce找出拥有此好友的所有人;再将这些人中两两配对作为键,之前的键(好友)作为值交给reduce去合并
简而言之我打算分成两个步骤,两次迭代
1)求出每一个人都是哪些人的共同好友
2)把这些人(用共同好友的人)作为key,其好友作为value输出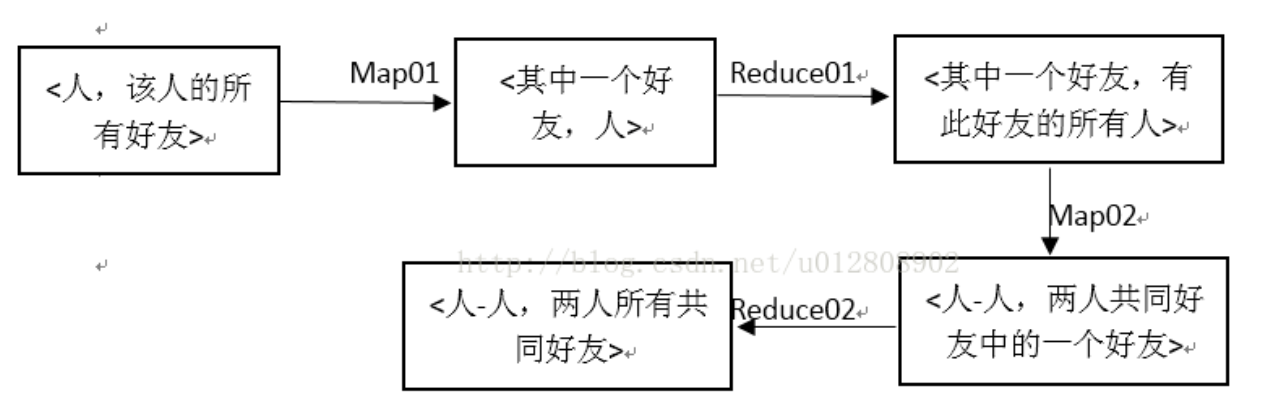
代码
1 | package com.qunar.mr.sharefriends; |
解法二
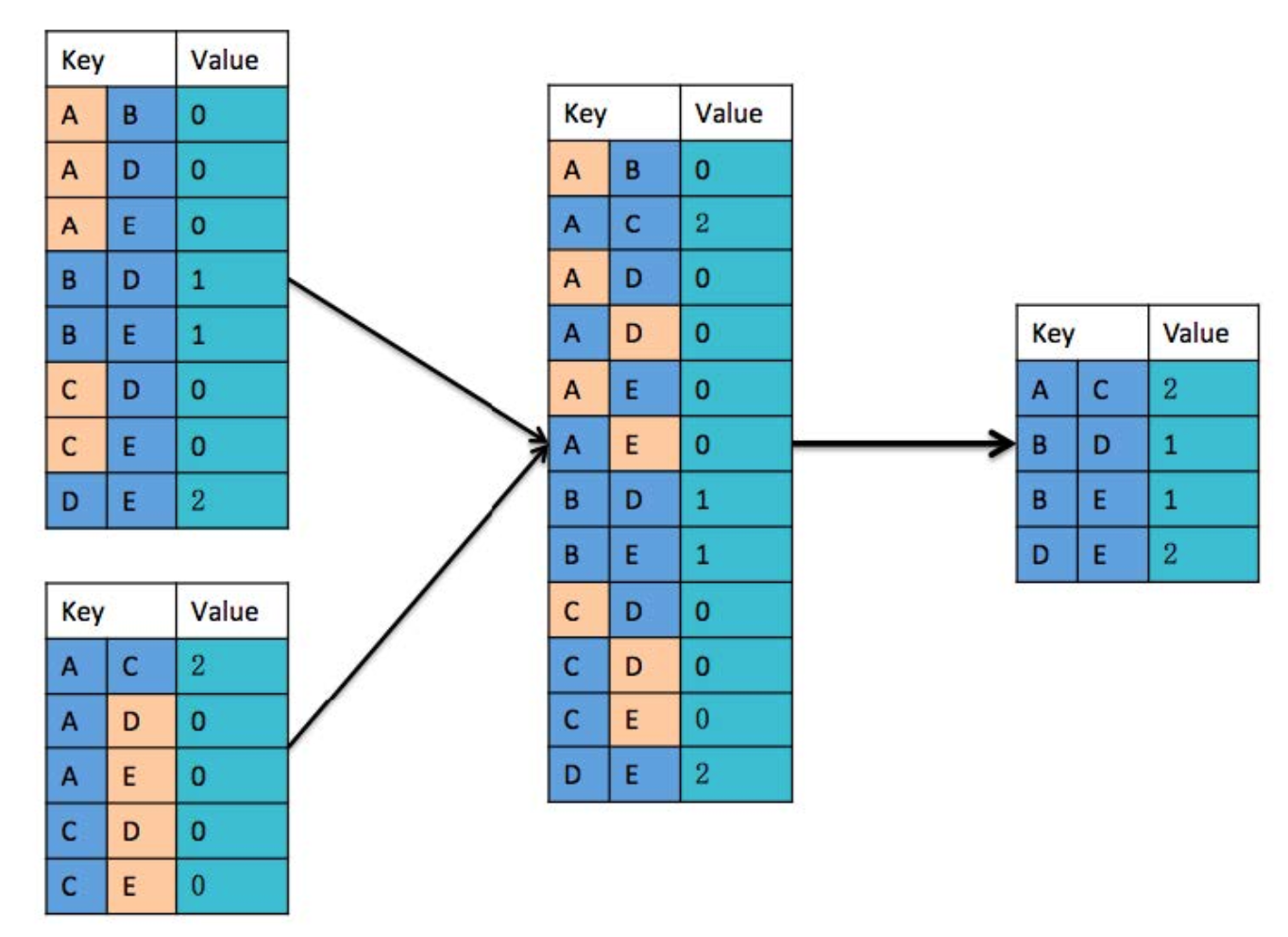
- 将好友关系分配到两个 Map 进行处理,其中每个 Map 包含 3 条好友关系。对每一条好友关系进行拆分,若 Key 中的两个人为朋友,则记录 value 值为0,否则 value 值为 1。将拆分的结果进行排序,其中(A B)和(B A)作为同一个 key(A B)。
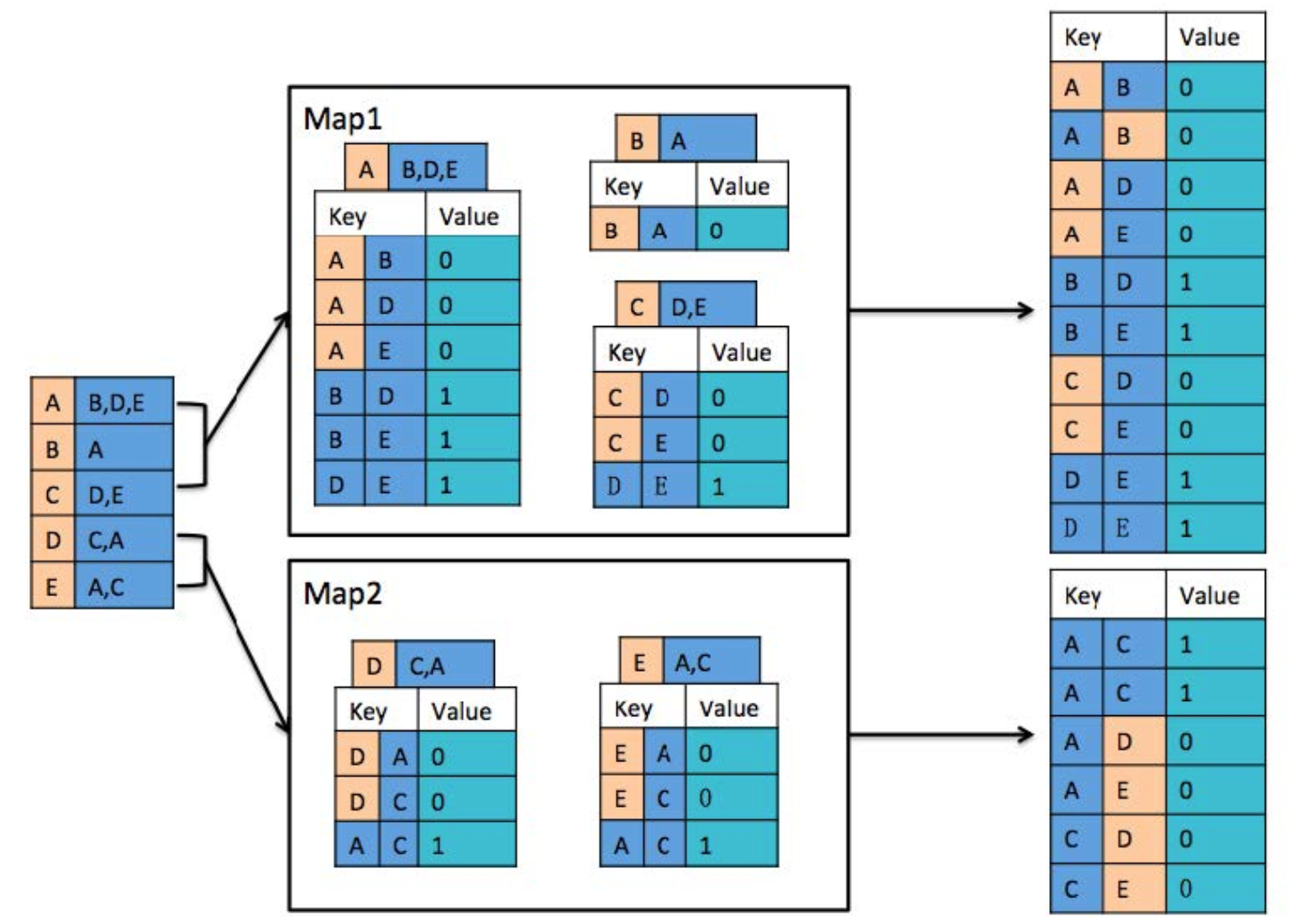
- 分别对两个 Map 处理的记录进行初步合并,若两个记录的 Key 值相同且每条记录的 Value 都不为 0,则 Value 值加 1。(都为0的说明两者本身就是好友,不需要参与推荐)
注意:
在 Combine 阶段,必须保留 Value 为 0 的记录,否则,在 Reduce 阶段,获取的结果会出错。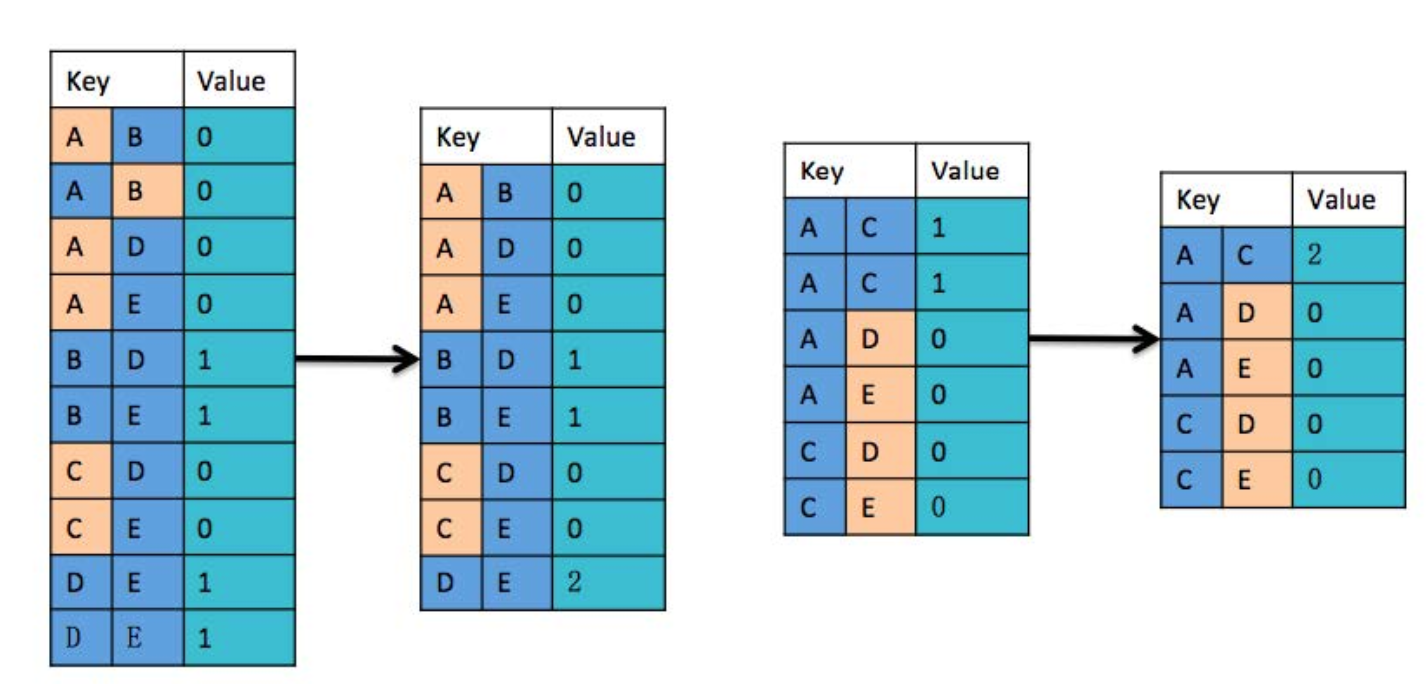
通过 Reduce 方式,合并两个 Map 处理的 Combine 结果。
- 若两个记录的 Key 值相同且每条记录的 Value 都不为 0,则 Value 值加 1。
- 将 Value 值为 0 的记录删除。(本身就是好友,不需要推荐)
- 获取不为好友的两个用户之间的公共好友数:Key 为两个不为好友的用户,Value 是两个不是好友的用户之间的共同好友数。社交网站或者 APP 可以根据这个数值对不是好友的两个用户进行推荐。
参考:
https://blog.csdn.net/u012808902/article/details/77513188
https://help.aliyun.com/document_detail/58590.html?spm=a2c4g.11186623.6.728.45e5693dRhOoRo#h2-u5B9Eu9A8Cu4ECBu7ECD