题意
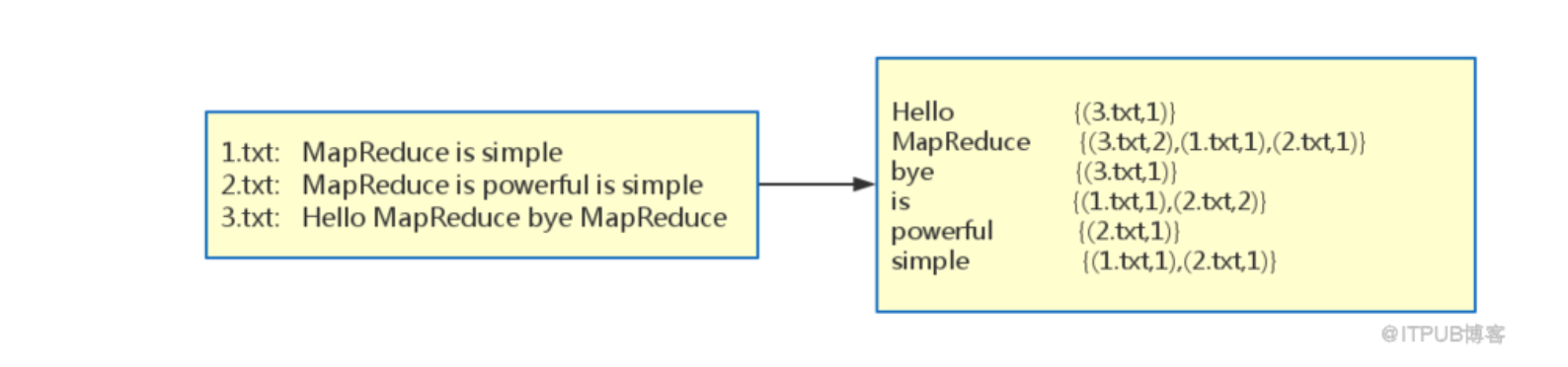
hdfs 上有三个文件,内容下上面左面框中所示。右框中为处理完成后的结果文件。
倒排索引(Inverted index),也常被称为反向索引、置入档案或反向档案,是一种索引方法,被用来存储在全文搜索下某个单词在一个文档或者一组文档中的存储位置的映射。它是文档检索系统中最常用的数据结构。通过倒排索引,可以根据单词快速获取包含这个单词的文档列表。倒排索引主要由两个部分组成:“单词词典”和“倒排文件”
这个任务与传统的倒排索引任务不同的地方是加上了每个文件中的频数。
实现思路
首先关注结果中有文件名称,这个我们有两种方式处理:
1、自定义InputFormat,在其中的自定义RecordReader中,直接通过InputSplit得到Path,继而得到FileName;
2、在Mapper中,通过上下文可以取到Split,也可以得到fileName。这个任务中我们使用第二种方式,得到filename.
在mapper中,得到filename 及 word,封装到一个自定义keu中。value 使用IntWritable。在map 中直接输出值为1的IntWritable对象。
对进入reduce函数中的key进行分组控制,要求按word相同的进入同一次reduce调用。所以需要自定义GroupingComparator。
代码
1 | package com.qr.mr.invertedsort; |