spark流计算的数据是以窗口的形式,源源不断的流过来的。如果每个窗口之间的数据都有联系的话,那么就需要对前一个窗口的数据做状态管理。spark有提供了两种模型来达到这样的功能,一个是updateStateByKey,另一个是mapWithState ,后者属于Spark1.6之后的版本特性,性能是前者的数十倍。
基本的wordcount1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36package com.scala.test
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WC {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//程序在运行时receiver会独占一个线程,所以streaming程序至少要两个线程,防止starvation scenario
conf.setAppName("WordCount").setMaster("local[2]")
val sc = new SparkContext(conf)
//所有流功能的主要入口
val smc : StreamingContext = new StreamingContext(sc, Seconds(5))
//指定从TCP源数据流的离散流,接收到的每一行数据都是一行文本
val lines : ReceiverInputDStream[String] = smc.socketTextStream("localhost",6666)
//将接收到的文本压平,转换,聚合
val dStream : DStream[(String, Int)] = lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
dStream.print()
// Spark Streaming 只有建立在启动时才会执行计算,在它已经开始之后,并没有真正地处理
// --------------------------
//启动计算
smc.start();
//等待计算终止
smc.awaitTermination();
//true 会把内部的sparkcontext同时停止
//false 只会停止streamingcontext 不会停sparkcontext
smc.stop(true);
}
}
updateStateByKey
1 | package com.scala.test |
mapWithState
1 | package com.scala.test |
使用Redis管理状态
我们不使用Spark自身的缓存机制来存储状态,而是使用Redis来存储状态。来一批新数据,先去redis上读取它们的上一个状态,然后更新写回Redis,逻辑非常简单,如下图所示
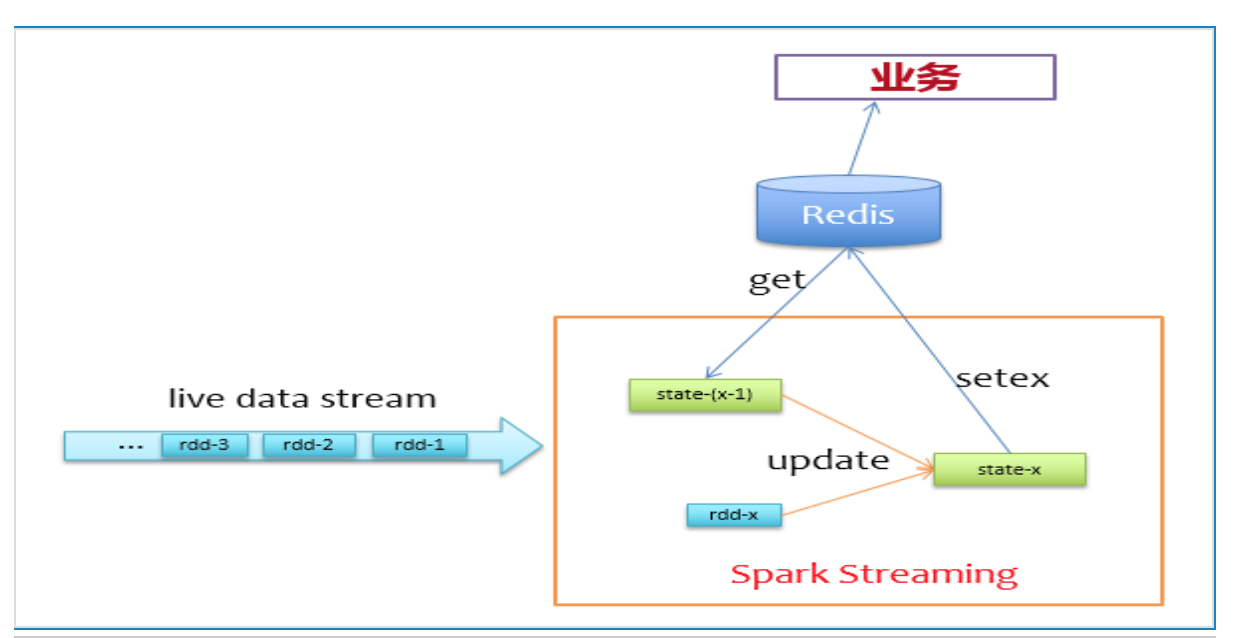
在实际实现过程中,为了避免对同一个key有多次get/set请求,所以在更新状态前,使用groupByKey对相同key的记录做个归并,对于前面描述的问题,我们可以先这样做:1
2val liveDStream = ... // (userId, clickId)
liveDStream.groupByKey().mapPartitions(...)
为了减少访问Redis的次数,我们使用pipeline的方式批量访问,即在一个分区内,一个一个批次的get/set,以提高Redis的访问性能,那么我们的更新逻辑就可以做到mapPartitions里面,如下代码所示。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43val updateAndflush = (
records: Seq[(Long, Set(Int))],
states: Seq[Response[String]],
pipeline: Pipeline) => {
pipeline.sync() // wait for getting
var i = 0
while (i < records.size) {
val (userId, values) = records(i)
// 从字符串中解析出上一个状态中的点击列表
val oldValues: Set[Int] = parseFrom(states(i).get())
val newValues = values ++ oldValues
// toString函数将Set[Int]编码为字符串
pipeline.setex(userId.toString, 3600, toString(newValues))
i += 1
}
pipeline.sync() // wait for setting
}
val mappingFunc = (iter: Iterator[(Long, Iterable[Int])]) => {
val jedis = ConnectionPool.getConnection()
val pipeline = jedis.pipelined()
val records = ArrayBuffer.empty[(Long, Set(Int))]
val states = ArrayBuffer.empty[Response[String]]
while (iter.hasNext) {
val (userId, values) = iter.next()
records += ((userId, values.toSet))
states += pipeline.get(userId.toString)
if (records.size == batchSize) {
updateAndflush(records, states, pipeline)
records.clear()
states.clear()
}
}
updateAndflush(records, states, pipeline)
Iterator[Int]()
}
liveDStream.groupByKey()
.mapPartitions(mappingFunc)
.foreachRDD { rdd =>
rdd.foreach(_ => Unit) // force action
}
上述代码没有加容错等操作,仅描述实现逻辑,可以看到,函数mappingFunc会对每个分区的数据处理,实际计算时,会累计到batchSize才去访问Redis并更新,以降低访问Redis的频率。这样就不再需要cache和checkpoint了,程序挂了,快速拉起来即可,不需要从checkpoint处恢复状态,同时可以节省相当大的计算资源。1
2
3
4
5
6spark.streaming.blockInterval=10000
spark.streaming.backpressure.enabled=true
spark.streaming.receiver.maxRate=5000
spark.yarn.maxAppAttempts=4
spark.speculation=true
spark.task.maxFailures=8
参考:
https://blog.csdn.net/struggle3014/article/details/79792695