OneData体系分为:
1、数据规范定义体系
2、数据模型规范设计
3、ETL规范研发以及支撑整个体系从方法到实施的工具体系。
落地实现
数据规范定义
将此前个性化的数据指标进行规范定义,抽象成:原子指标、时间周期、其他修饰词等三个要素。
例如,以往业务方提出的需求是:最近7天的成交。而实际上,这个指标在规范定义中,应该结构化分解成为:
原子指标(支付订单金额 )+修饰词-时间周期(最近7天)+修饰词-卖家类型(淘宝)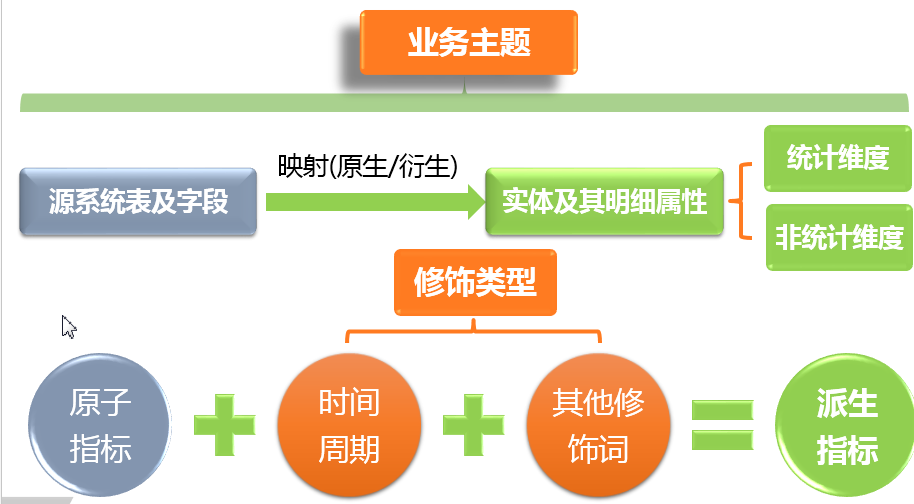
上文只有抽象指标的方法,应该还包括字段规范,表名规范
派生指标的定义也很重要,因为数据运营人员经常会查最近7,最近一月的指标,每次都从基础事实表中,查询的量会很大。
数据模型架构
理解为dw的分层设计
将数据分为ODS(操作数据)层、CDM(公共维度模型)层、ADS(应用数据)层。
其中:
ODS层主要功能
这里先介绍一下阿里云数加大数据计算服务MaxCompute,是一种快速、完全托管的TB/PB级dw解决方案,适用于多种数据处理场景,如日志分析,dw,机器学习,个性化推荐和生物信息等。
同步:结构化数据增量或全量同步到数加MaxCompute(原ODPS);
结构化:非结构化(日志)结构化处理并存储到MaxCompute(原ODPS);
累积历史、清洗:根据数据业务需求及稽核和审计要求保存历史数据、数据清洗;
CDM层主要功能
CDM层又细分为DWD层和DWS层,分别是明细宽表层和公共汇总数据层,采取维度模型方法基础,更多采用一些维度退化手法,减少事实表和维度表的关联,容易维度到事实表强化明细事实表的易用性;同时在汇总数据层,加强指标的维度退化,采取更多宽表化的手段构建公共指标数据层,提升公共指标的复用性,减少重复的加工。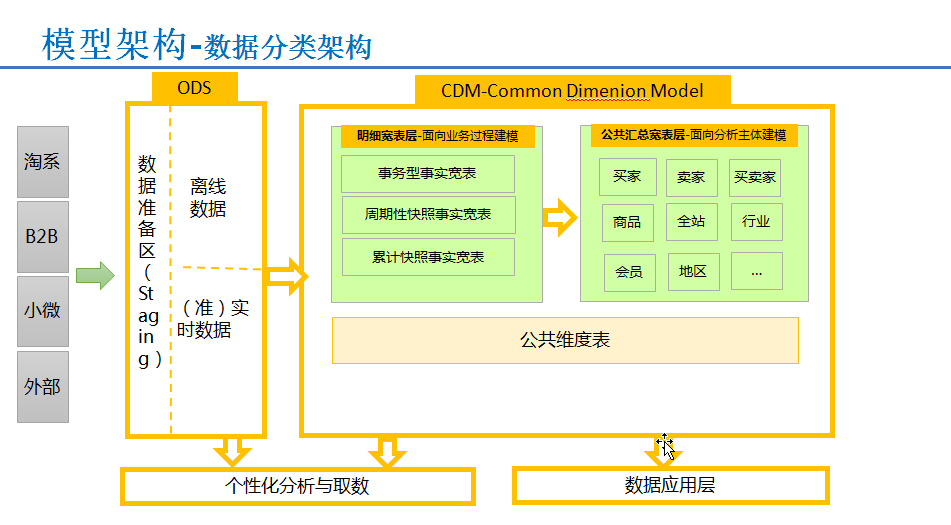
ADS层主要功能
个性化指标加工:不公用性;复杂性(指数型、比值型、排名型指标)
基于应用的数据组装:大宽表集市、横表转纵表、趋势指标串
其模型架构图如上图,阿里通过构建全域的公共层数据,极大的控制了数据规模的增长趋势,同时在整体的数据研发效率,成本节约、性能改进方面都有不错的结果。
研发流程和工具落地实现
将OneData体系贯穿于整个研发流程的每个环节中,并通过研发工具来进行保障。
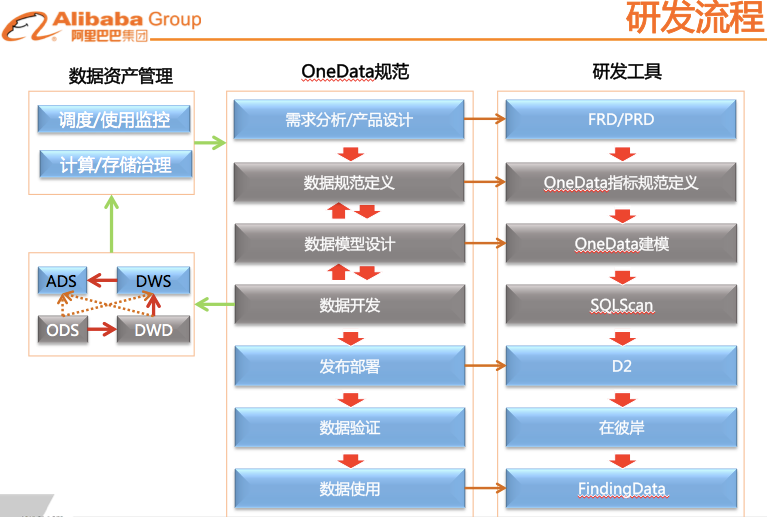
实施效果
1、数据标准统一:数据指标口径一致,各种场景下看到的数据一致性得到保障
2、支撑多个业务,极大扩展性:服务了集团内部45个BU的业务,满足不同业务的个性化需求
3、统一数据服务:建立了统一的数据服务层,其中离线数据日均调用次数超过22亿;实时数据调用日均超过11亿
4、计算、存储成本:指标口径复用性强,将原本30000多个指标精简到3000个;模型分层、粒度清晰,数据表从之前的25000张精简到不超过3000张。
5、研发成本:通过数据分域、模型分层,强调工程师之间的分工和协作,不再需要从头到尾每个细节都了解一遍,节省了工程师的时间和精力。
参考:
https://yq.aliyun.com/articles/67011
明细宽表层-面向业务建模过程:
事务型事实宽表,周期性快照事实宽表,累计快照事实宽表
公共汇总款表层-面向分析主题建模:
流量,订单,商品,用户
上面两层都是基于公共维度表的基础上
维度退化手法
指标维度退化
大宽表集市、横表转纵表、趋势指标串
个性化指标加工:不公用性;复杂性(指数型、比值型、排名型指标)