group by数据倾斜
倾斜原因:
select count(distinct name) from user时 使用distinct会将所有的name值都shuffle到一个reducer里面。
特别的有select uid, count(distinct name) from user group by uid; 即count distinct + (group by)的情况。
优化:
(1)主要是把count distinct改变成group by。
改变上面的sql为select uid, count(name) from (select uid, name from user group by uid, name)t group by uid.
(2)给group by 字段加随机数打散,聚合,之后把随机数去掉,再次聚合(有点类似下面的参数SET hive.groupby.skewindata=true;)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29select split(uid, '_')[0] uid, sum(names) from
(
select concat_ws('-', uid, substr(rand()*10, 1, 1)) uid, count(name) names
from
(
select uid, name ---此处去重,且不会倾斜
from user
group by uid, name
)a
group by concat_ws('-', uid, substr(rand()*10, 1, 1))
)b
group by split(uid, '_')[0]
等同于下面
select split(uid, '_')[0] uid, sum(names) from
(
select uid,count(name) names from (
select concat_ws('-', uid, substr(rand()*10, 1, 1)) uid, name
from
(
select uid, name
from user
group by uid, name
)a
) c
group by uid
)b
group by split(uid, '_')[0]
(3)SET hive.groupby.skewindata=true; 当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,该Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作.
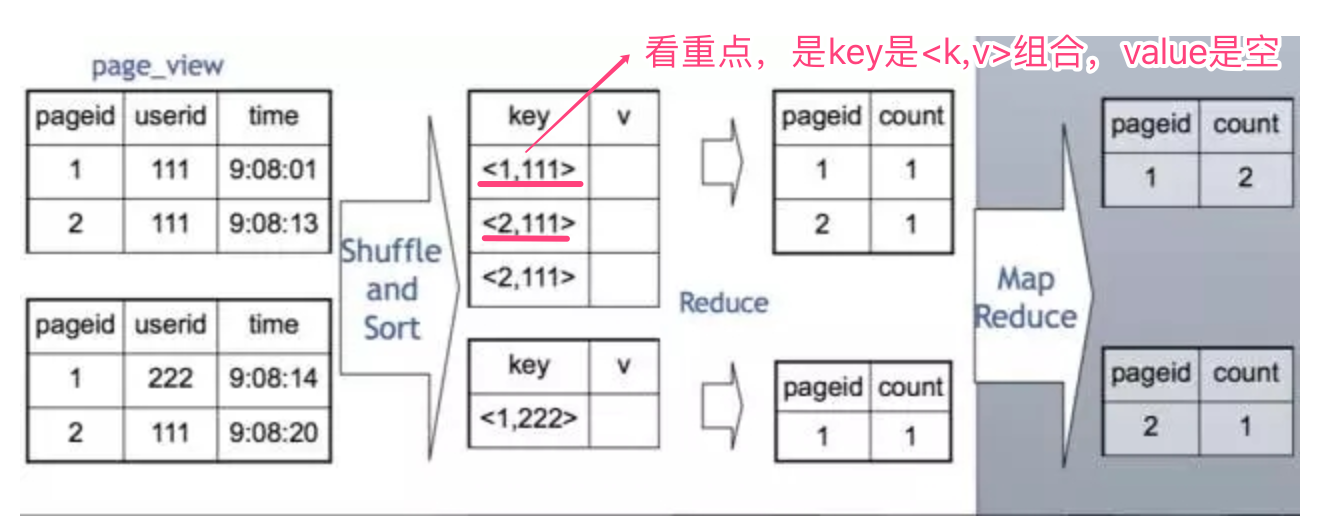
set hive.map.aggr=true; 在mapper端部分聚合,相当于Combiner 。而Map-Side聚合,一般在聚合函数sum,count时使用。
无论你使用Map端,或者两道作业。其原理都是通过部分聚合来来减少数据量。能不能部分聚合,部分聚合能不能有效减少数据量,通常与UDAF,也就是聚合函数有关。也就是只对代数聚合函数有效,对整体聚合函数无效。
所谓代数聚合函数,就是由部分结果可以汇总出整体结果的函数,如count,sum。 所谓整体聚合函数,就是无法由部分结果汇总出整体结果的函数,如avg,mean。 比如,sum, count,知道部分结果可以加和得到最终结果。 而对于,mean,avg,知道部分数据的中位数或者平均数,是求不出整体数据的中位数和平均数的。
set hive.groupby.mapaggr.checkinterval=100000;–这个是group的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置。
hive.map.aggr.hash.min.reduction=0.5(默认)预先取100000条数据聚合,如果聚合后的条数/100000>0.5,则不再聚合
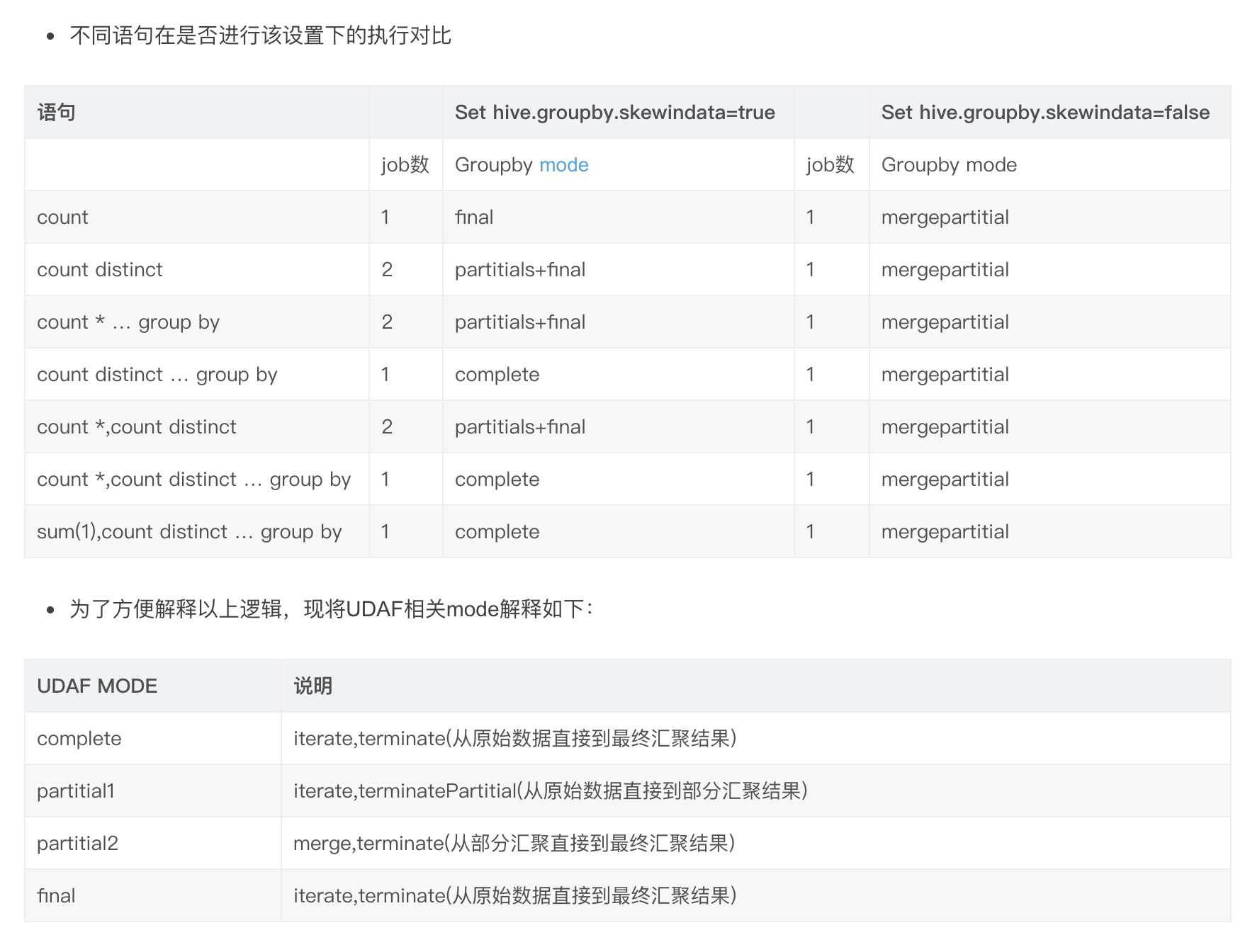
使用Hive的过程中,我们习惯性用set hive.groupby.skewindata=true来避免因数据倾斜造成的计算效率问题,但是每个设置都是把双刃剑,最近调研了下相关问题,现总结如下:
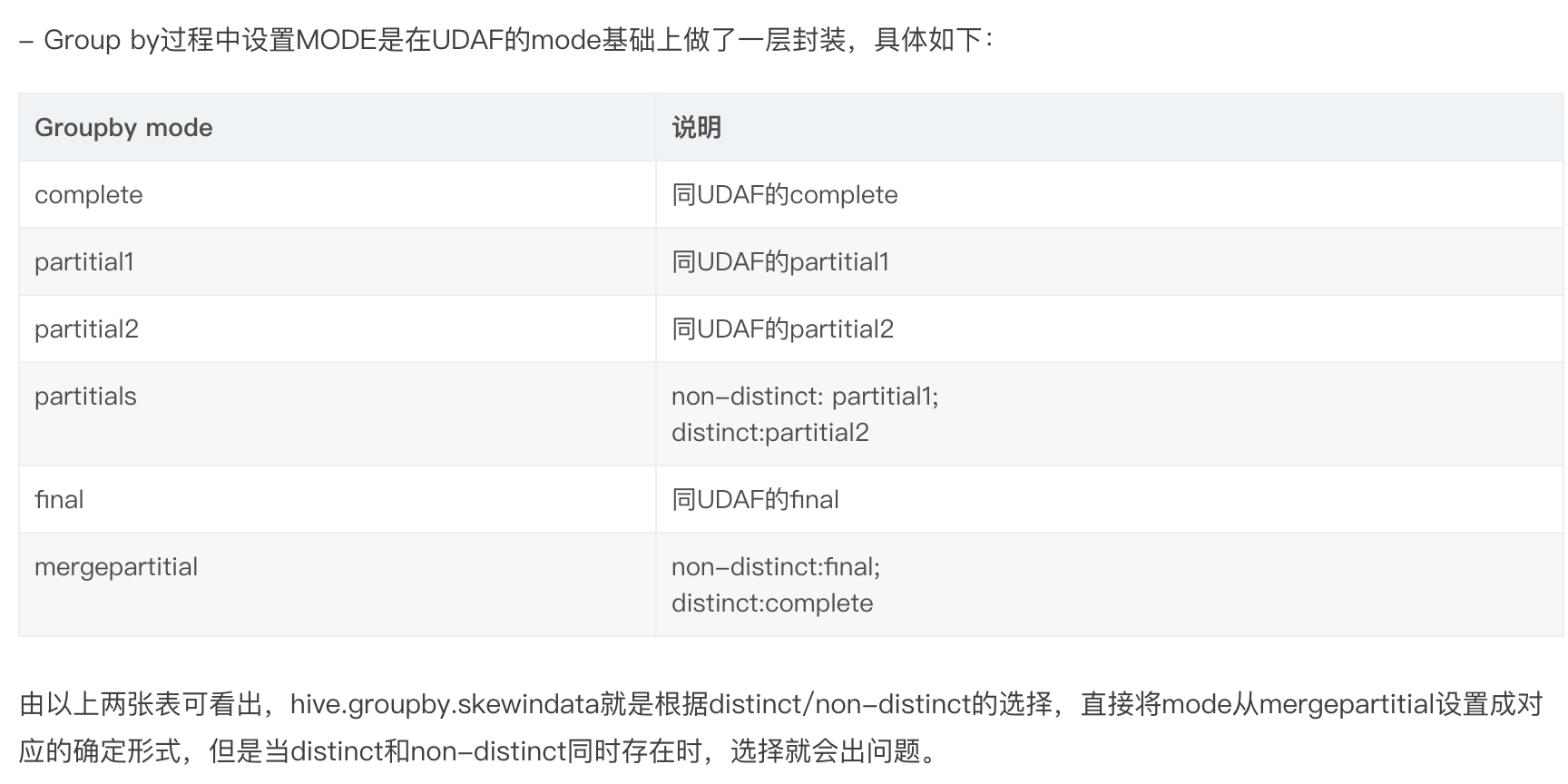
从下表可以看出,skewindata配置真正发生作用,只会在以下三种情况下,能够将1个job转化为2个job:
select count distinct … from …
select a,count() from … group by a 只针对单列有效
select count(),count(distinct …) from 此处没有group by
如下sql会报错
select count(*),count(distinct …) from … group by a 此处有group by
需要改为
select a,sum(1),count(distinct …) from … group by a
参考:
https://meihuakaile.github.io/2018/10/19/hive%E6%95%B0%E6%8D%AE%E5%80%BE%E6%96%9C/
https://blog.csdn.net/dxl342/article/details/77886577
https://blog.csdn.net/lw_ghy/article/details/51469753