hive执行引擎会将HQL“翻译”成为map-reduce任务,如果多张表使用同一列做join则将被翻译成一个reduce,否则将被翻译成多个map-reduce任务。
一般来说(map side join除外),map过程负责分发数据,具体的join操作在reduce完成,因此,如果多表基于不同的列做join,则无法在一轮map-reduce任务中将所有相关数据shuffle到统一个reducer
对于多表join,hive会将前面的表缓存在reducer的内存中,然后后面的表会流式的进入reducer和reducer内存中其它的表做join.
为了防止数据量过大导致oom,将数据量最大的表放到最后,或者通过“STREAMTABLE”显示指定reducer流式读入的表
common join
1 | SELECT a.uid,a.name,b.age FROM logs a JOIN users b ON (a.uid=b.uid); |
Map阶段
读取源表的数据,Map输出时候以Join on条件中的列为key,如果Join有多个关联键,则以这些关联键的组合作为key;
Map输出的value为join之后所关心的(select或者where中需要用到的)列;同时在value中还会包含表的Tag信息,用于标明此value对应哪个表;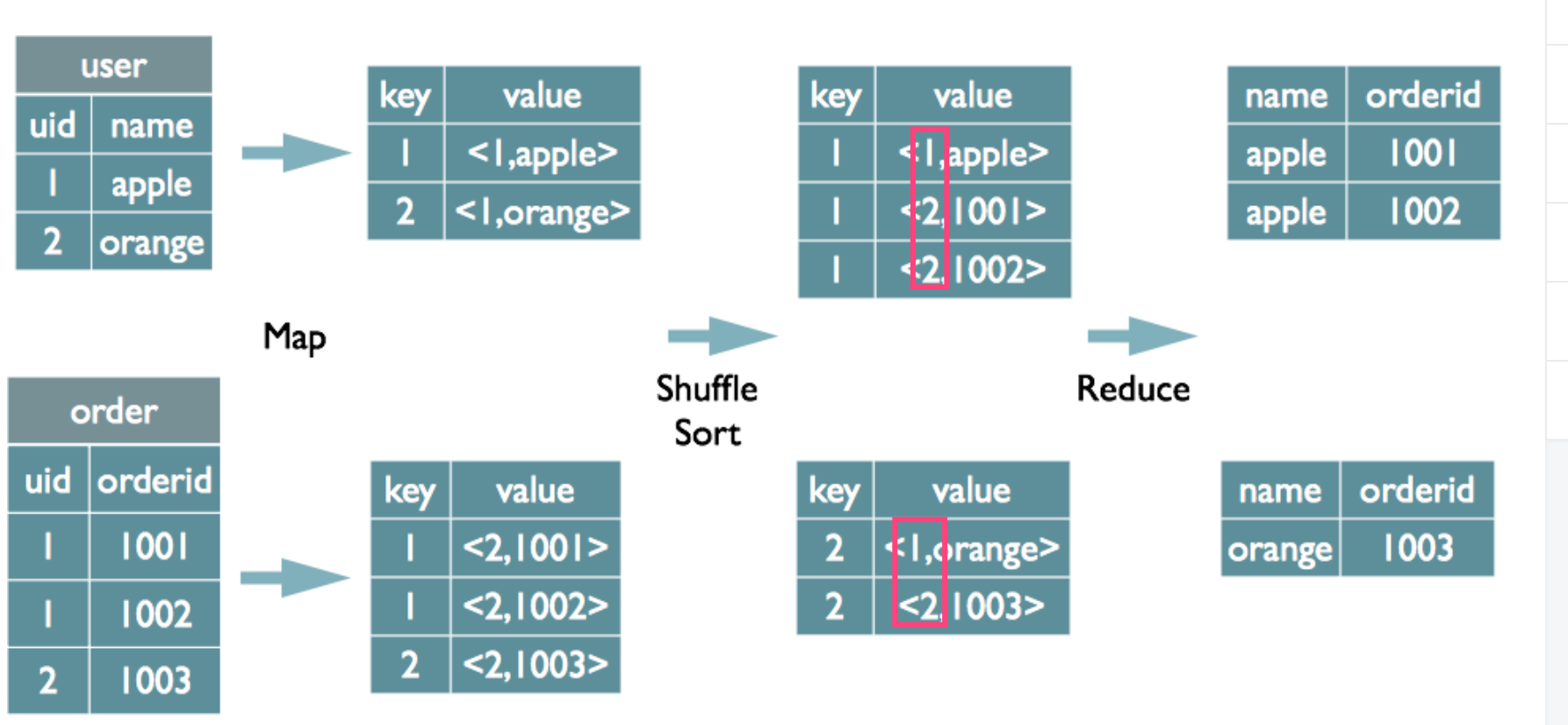
该图中tag在value中
按照key进行排序Shuffle阶段
根据key的值进行hash,并将key/value按照hash值推送至不同的reduce中,这样确保两个表中相同的key位于同一个reduce中Reduce阶段
reduce阶段主要看它是如何把它合并起来了,从图上可以直观的看到,其实就是把tag=1的内容,都加到tag=0的后面,就是这么简单。
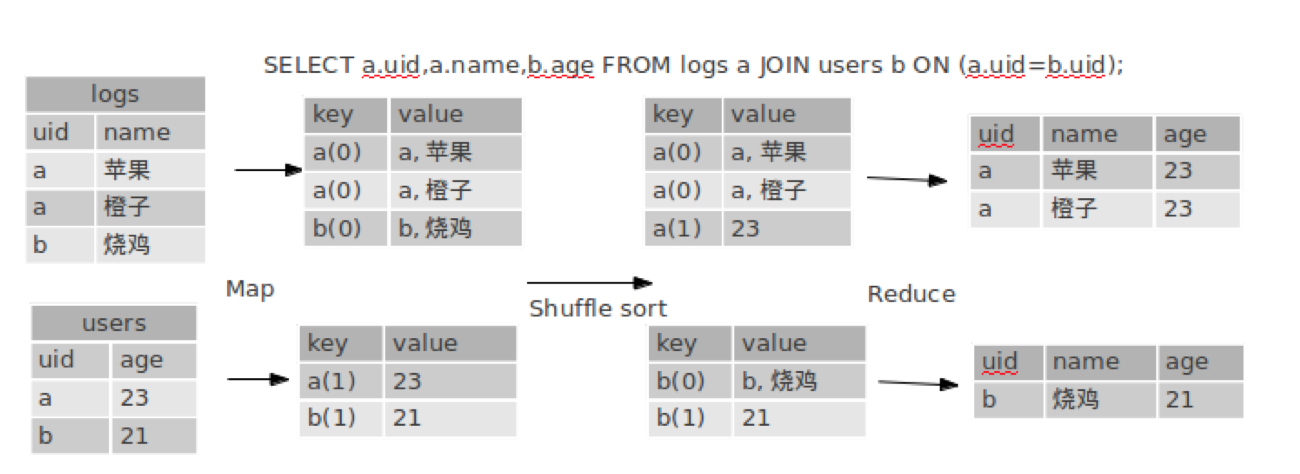
该图中tag在key.key这里后面的数字是tag,后面在reduce阶段用来区分来自于那个表的数据。tag是附属在key后面的。那为什么会把a(0)和a(1)汇集在一起了呢,是因为对先对a求了hashcode,设在了HiveKey上,所以同一个key还是在一起的。该方式虽然可以解释通过,但不是真的具体实现。1
2
3
4
5
6
7
8
9
10在reduce阶段join。
map阶段标记数据来自哪个文件,比如来自file1标记tag=1,来自file2标记tag=2。
reduce阶段把key相同的file1的数据和file2的数据通过笛卡尔乘积join在一起。
个人理解:举个例子
file1 有{1:'a', 2:'b', 3:'c'}
file2 有{1:'A', 2:'B'}
可以join成{1:['a','A'], 2:['b', 'B']}
operator
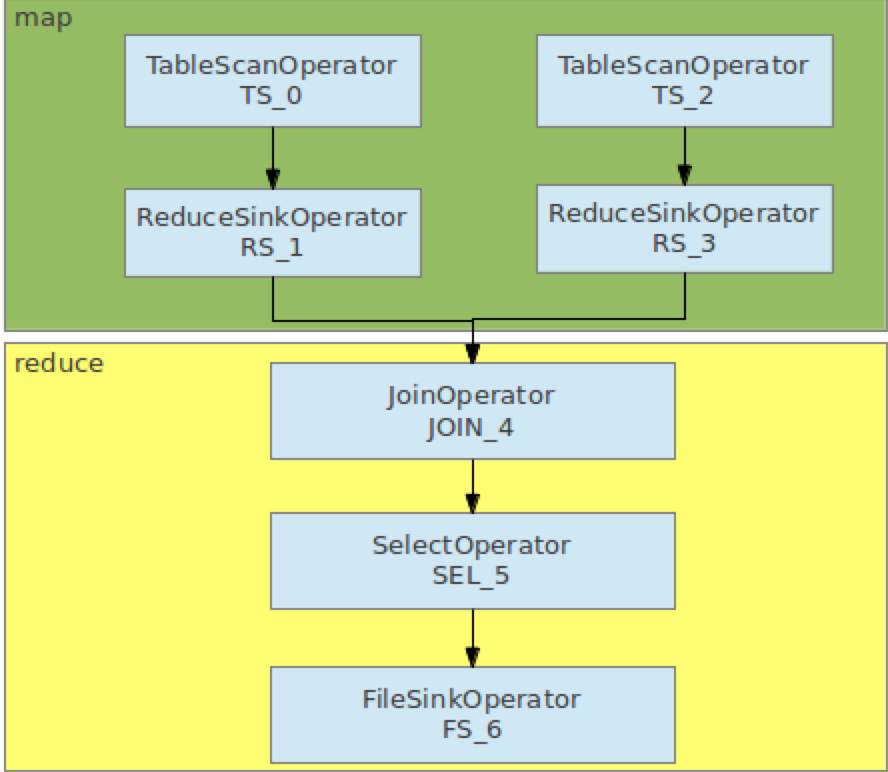
explain
1 | hive> explain SELECT a.uid,a.name,b.age FROM logs a JOIN users b ON (a.uid=b.uid); |
可以看到里面都是一个个Operator顺序的执行下来
map join
MapJoin通常用于一个很小的表和一个大表进行join的场景,具体小表有多小,由参数hive.mapjoin.smalltable.filesize来决定,该参数表示小表的总大小,默认值为25000000字节,即25M。
Hive0.7之前,需要使用hint提示 /+ mapjoin(table) /才会执行MapJoin,否则执行Common Join,但在0.7版本之后,默认自动会转换Map Join,由参数hive.auto.convert.join来控制,默认为true.
假设a表为一张大表,b为小表,并且hive.auto.convert.join=true,那么Hive在执行时候会自动转化为MapJoin。
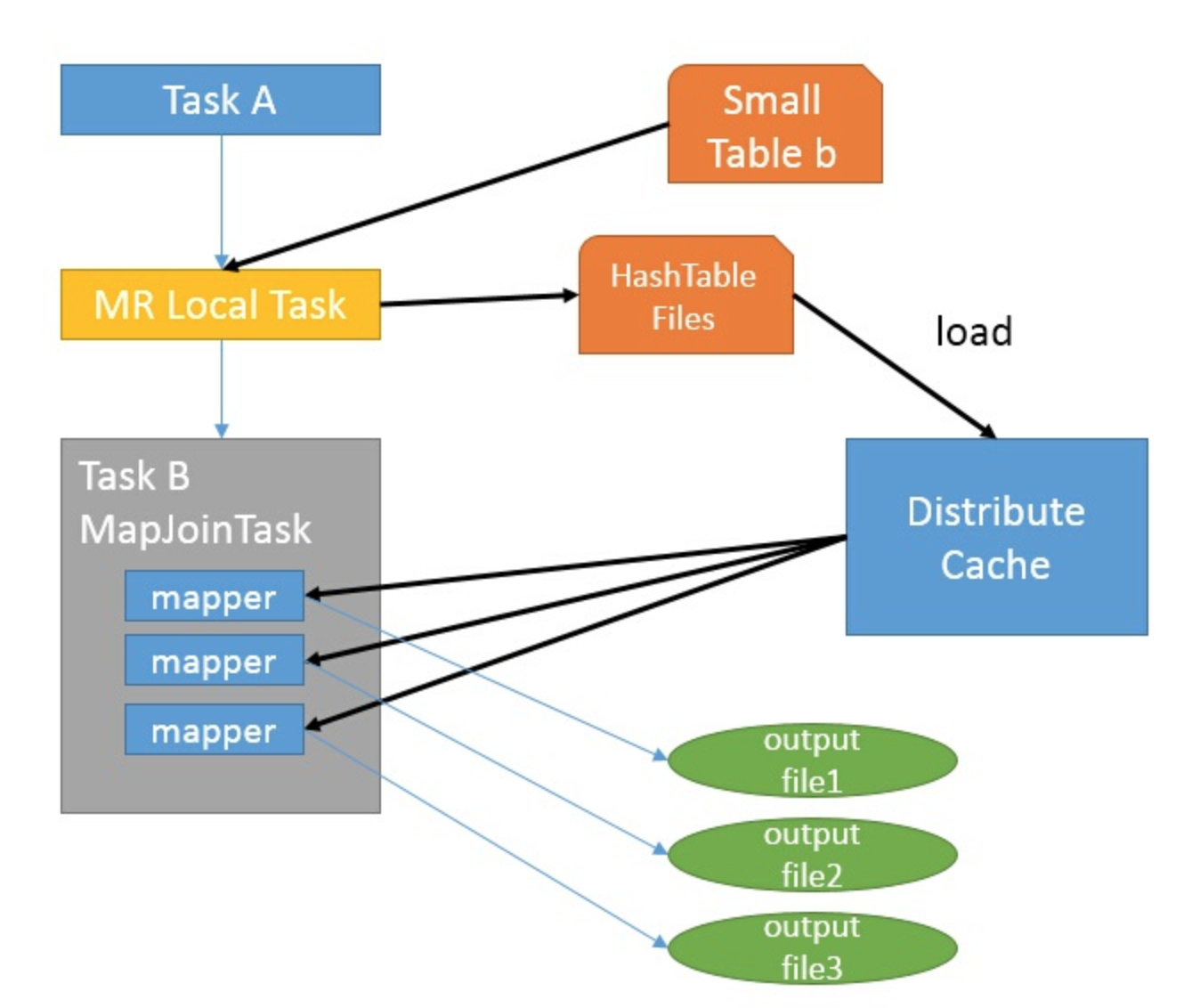
如图中的流程,首先是Task A,它是一个Local Task(在客户端本地执行的Task),负责扫描小表b的数据,将其转换成一个HashTable的数据结构,并写入本地的文件中,之后将该文件加载到DistributeCache中,该HashTable的数据结构可以抽象为:
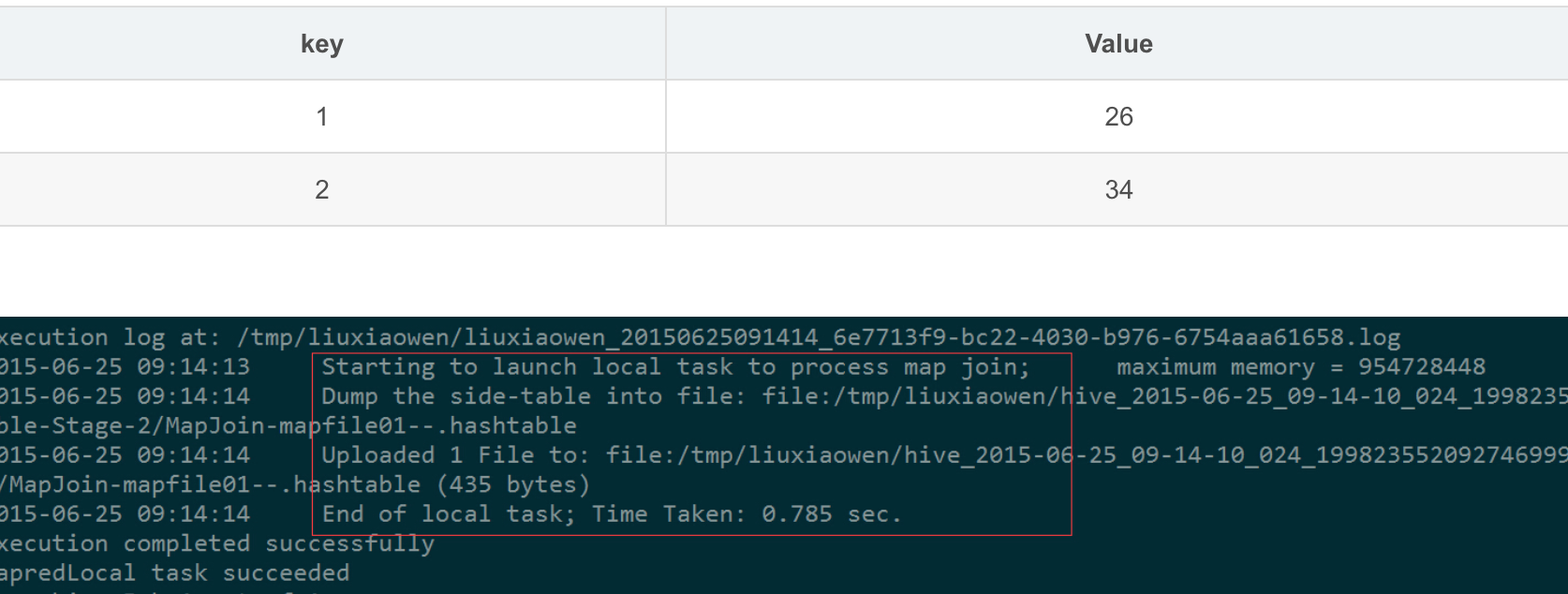
图中红框圈出了执行Local Task的信息。
接下来是Task B,该任务是一个没有Reduce的MR,启动MapTasks扫描大表a,在Map阶段,根据a的每一条记录去和DistributeCache中b表对应的HashTable关联,并直接输出结果。
由于MapJoin没有Reduce,所以由Map直接输出结果文件,有多少个Map Task,就有多少个结果文件。
总的来说,因为小表的存在,可以在Map阶段直接完成Join的操作,为了优化小表的查找速度,将其转化为HashTable的结构,并加载进分布式缓存中。
Auto Map Join
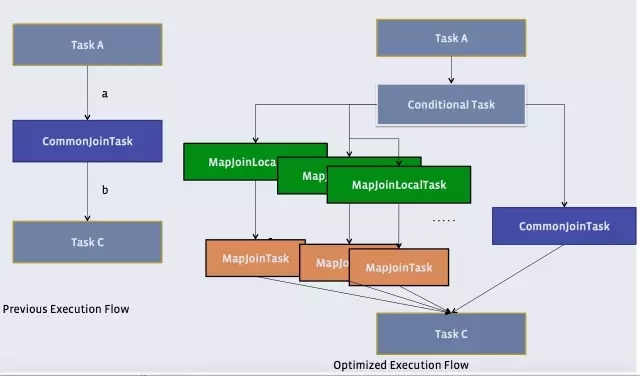
还记得原理中提到的物理优化器?Physical Optimizer么?它的其中一个功能就是把Join优化成Auto Map Join
图上左边是优化前的,右边是优化后的
优化过程是把Join作业前面加上一个条件选择器ConditionalTask和一个分支。左边的分支是MapJoin,右边的分支是Common Join(Reduce Join)
看看左边的分支是不是和我们上上一张图很像?
这个时候,我们在执行的时候,就由这个Conditional Task 进行实时路径选择,遇到小于25兆走左边,大于25兆走右边。所谓,男的走左边,女的走右边,人妖走中间。
在比较新版的Hive中,Auto Mapjoin是默认开启的。如果没有开启,可以使用一个开关, set hive.auto.convert.join=true 开启。
当然,Join也会遇到和上面的Group By一样的倾斜问题。
Hive 也可以通过像Group By一样两道作业的模式单独处理一行或者多行倾斜的数据。即采用下面的方式。
semi join半连接
这个是要改进reduce side join。建立一个小表file3,把file1的所有要参加join的数据的key复制进去,然后把file3复制到每一个map task中去,然后找出不在file2中的key,过滤掉这些数据后再进行reduce side join,减少跨机器数据传输。
个人理解:举个例子
file1 有{1:’a’, 2:’b’, 3:’c’}
file2 有{1:’A’, 2:’B’}
建立一个小表file3,所有要参加join的数据的key复制进去也就是
[1, 2, 3],然后发现file2中没有key=3的,所以可以过滤掉key=3的数据后再进行reduce join,来减少跨机器数据传输。
加入bloom filter
继续改进3。引入bloom filter。这种数据结构的特点是,存在false positive。如果使用它判断一个元素在集合中(positive),那其实有可能不在(false)。但是如果使用它判断一个元素不在集合中,那这个元素就真的不在这个集合中了。(没有false negative)
利用这个特点可以怎么改进3呢?在3中的file3我们可以用bloom filter来实现,要判断file2的key是否存在于file3中的时候直接使用bloom filter来判断。这样,如果判断说file2的某个key存在于file3中(positive),但是实际不在(false),那也无所谓,只是少过滤了一些key而已,还是可以正确地join。但是bloom filter可以保证没有false negative,如果判断file2的某个key不在file3中,那就真的不在file3中,这样可以保证join的正确性(不会少join了一些数据)。
hive.optimize.skewjoin
hive 中设定1
2set hive.optimize.skewjoin = true;
set hive.skewjoin.key = skew_key_threshold (default = 100000)
可以就按官方默认的1个reduce 只处理1G 的算法,那么skew_key_threshold= 1G/平均行长.或者默认直接设成250000000 (差不多算平均行长4个字节)
其原理是就在Reduce Join过程,把超过十万条的倾斜键的行写到文件里,回头再起一道Join单行的Map Join作业来单独收拾它们。最后把结果取并集就是了
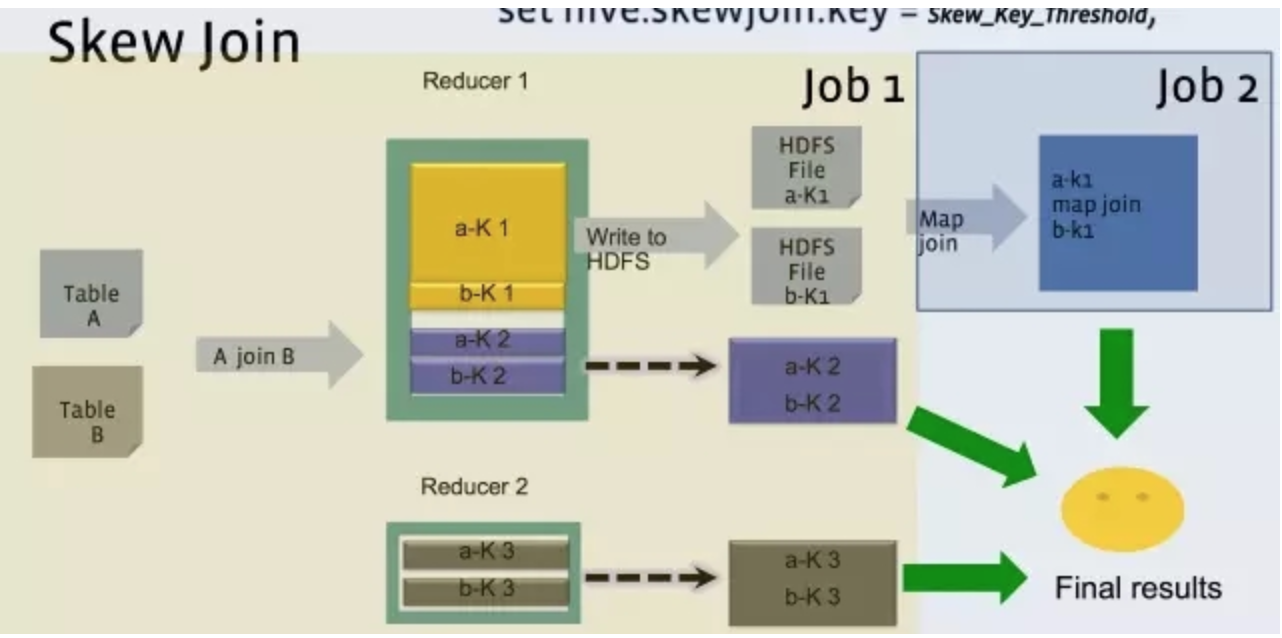
对full outer join无效。
其他方法
- null或者某个无效字符太多导致数据倾斜。
null=null结果是null,即false,在join时关联不上,join之前去掉不影响结果;
‘’关联得上,但是不需要时产生不必要的脏数据,可以在join之前把key为null/‘’的值去掉。
因为null关联不上如果null有用不能去掉,可以用下面两种方法。
办法(1)用union all1
2
3
4
5Select * From log a
Join users b
On a.user_id is not null And a.user_id = b.user_id
Union all
Select * from log a where a.user_id is null;
办法(2)赋予null值新的随机值1
2
3
4
5
6Select *
from log a
left Join
bmw_users b
on case when a.user_id is null then concat('dp_hive',rand())
else a.user_id end = b.user_id;
方法1的log读取两次,jobs是2。方法2的job数是1。这个优化适合无效id(比如-99,’’,null等)产生的倾斜问题。
把空值的key变成一个字符串加上随机数,就能把倾斜的数据分到不同的reduce上 ,解决数据倾斜问题。
不同数据类型关联也会产生数据倾斜。
场景:一张表s8的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题,s8的日志中有字符串商品id,也有数字的商品id,类型是string的,但商品中的数字id是bigint的。
问题原因:把s8的商品id转成数字id做hash来分配reduce,所以字符串id的s8日志,都到一个reduce上了,解决的方法验证了这个猜测。
解决方法:把数字类型转换成字符串类型1
2
3Select * from s8_log a
Left outer join r_auction_auctions b
On a.auction_id = cast(b.auction_id as string);大表Join的数据偏斜
MapReduce编程模型下开发代码需要考虑数据偏斜的问题,Hive代码也是一样。数据偏斜的原因包括以下两点:
1. Map输出key数量极少,导致reduce端退化为单机作业。
2. Map输出key分布不均,少量key对应大量value,导致reduce端单机瓶颈。
Hive中我们使用MapJoin解决数据偏斜的问题,即将其中的某个小表(全量)分发到所有Map端的内存进行Join,从而避免了reduce。这要求分发的表可以被全量载入内存。
极限情况下,Join两边的表都是大表,就无法使用MapJoin。这种问题最为棘手,目前已知的解决思路有两种:如果是上述情况1,考虑先对Join中的一个表去重,以此结果过滤无用信息。
这样一般会将其中一个大表转化为小表,再使用MapJoin 。一个实例是广告投放效果分析,
例如将广告投放者信息表i中的信息填充到广告曝光日志表w中,使用投放者id关联。因为实际广告投放者数量很少(但是投放者信息表i很大),因此可以考虑先在w表中去重查询所有实际广告投放者id列表,以此Join过滤表i,这一结果必然是一个小表,就可以使用MapJoin。1
2
3
4
5select /*+mapjoin(x)*/* from log a left outer join (
select /*+mapjoin(c)*/d.*
from ( select distinct user_id from log ) c
join users d on c.user_id = d.user_id
) x on a.user_id = b.user_id;如果是上述情况2,考虑切分Join中的一个表为多片,以便将切片全部载入内存,然后采用多次MapJoin得到结果。
1
2
3
4
5
6
7
8
9
10
11select * from
(
select w.id, w.time, w.amount, i1.name, i1.loc, i1.cat
from w left outer join i sampletable(1 out of 2 on id) i1
)
union all
(
select w.id, w.time, w.amount, i2.name, i2.loc, i2.cat
from w left outer join i sampletable(1 out of 2 on id) i2
)
);
以下语句实现了left outer join逻辑:1
2
3
4
5
6
7
8select t1.id, t1.time, t1.amount,
coalease(t1.name, t2.name),
coalease(t1.loc, t2.loc),
coalease(t1.cat, t2.cat)
from (
select w.id, w.time, w.amount, i1.name, i1.loc, i1.cat
from w left outer join i sampletable(1 out of 2 on id) i1
) t1 left outer join i sampletable(2 out of 2 on id) t2;
上述语句使用Hive的sample table特性对表做切分。
- 如果A表关联B表在某个key上倾斜,B是码表,那么可以将B表放大1000倍,然后对A表的key字段加上一个1000以内hash后缀,然后和放大后的b表关联,可以解决问题。
参考:
https://blog.csdn.net/lw_ghy/article/details/51469753
https://www.cnblogs.com/skyl/p/4855099.html
https://cwiki.apache.org/confluence/display/Hive/Skewed+Join+Optimization
https://blog.csdn.net/u013668852/article/details/79768266