缓存
首先我们要知道什么是查询缓存?查询缓存又有什么作用?
功能:mybatis提供查询缓存,用于减轻数据压力,提高数据库性能。
用图来表示如下图:
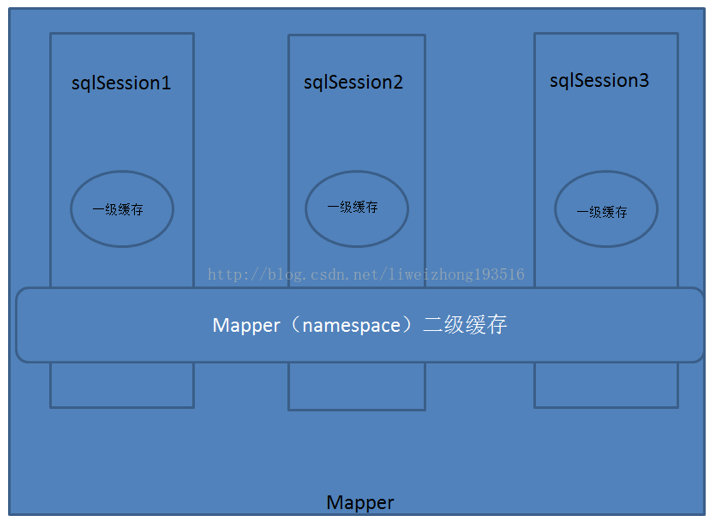
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造 sqlSession对象,在对象中有一个数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。所以在这种情况下,是不能实现跨表的session共享的
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是横跨跨SqlSession的。相信不用我再给大家去解释什么事Mapper了吧!
一级缓存
Mybatis对缓存提供支持,但是在没有配置的默认情况下,它只开启一级缓存,一级缓存只是相对于同一个SqlSession而言。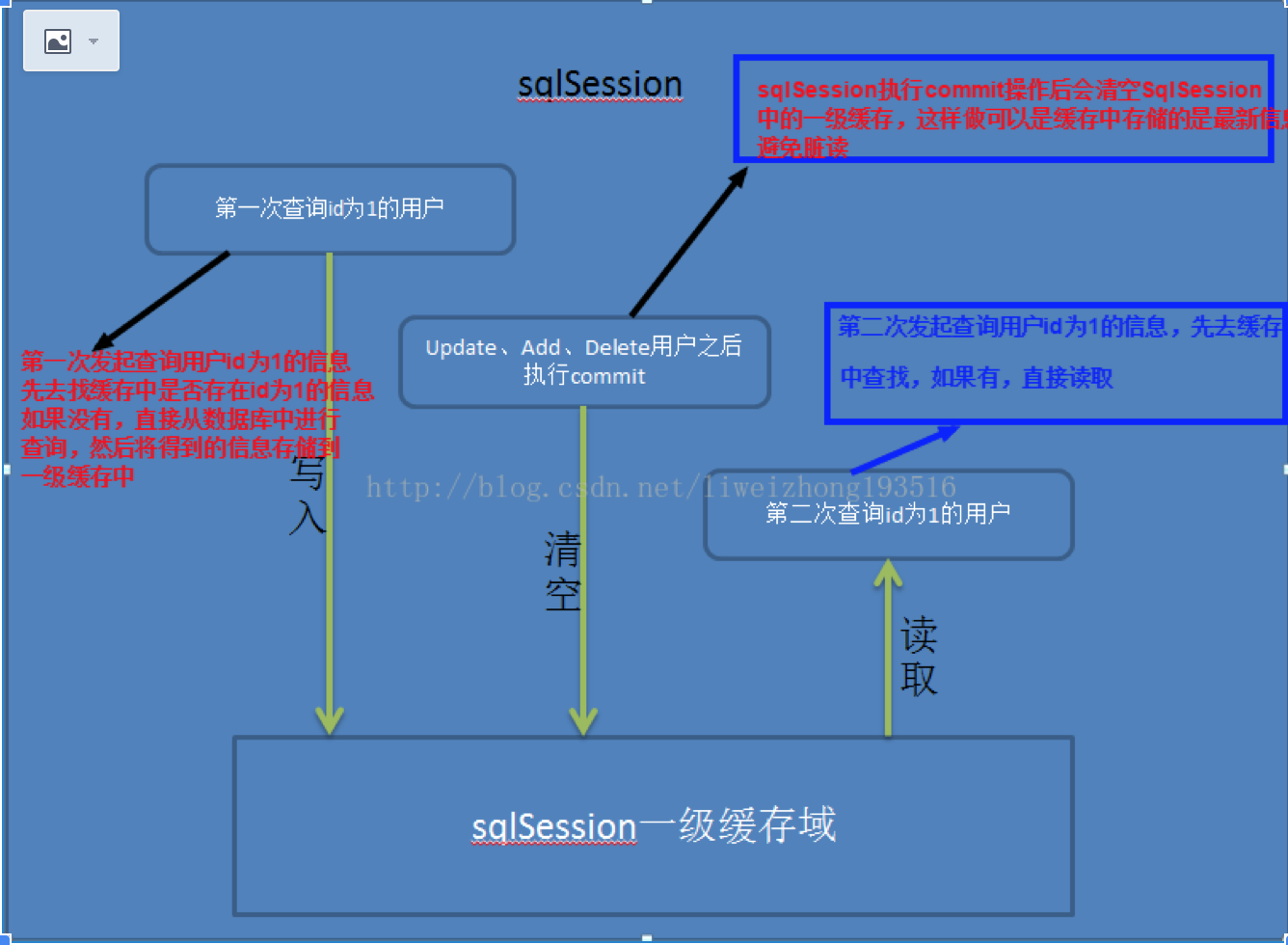
首先从图上,我们可以看出,一级缓存区域是根据SqlSession为单位划分的。每次查询都会先从缓存区与找,如果找不到就会从数据库查询数据,然后将查询到的数据写入一级缓存中。Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+sql语句。而value值就是从查询出来映射生成的java对象。而为了保证缓存里面的数据肯定是准确数据避免脏读,每次我们进行数据修改后(增删改)就会执行commit操作,清空缓存区域。
说到这里,我们来做一下测试:1
2
3
4
5
6
7
8
9
10
11
12//获取session
SqlSession session = sqlSessionFactory.openSession();
//获限mapper接口实例
UserMapper userMapper = session.getMapper(UserMapper.class);
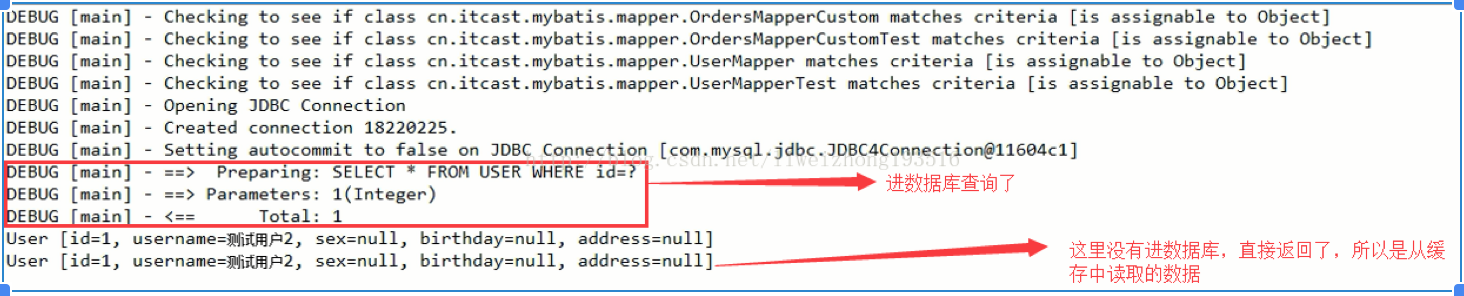
//第一次查询
User user1 = userMapper.findUserById(1);
System.out.println(user1);
//第二次查询,由于是同一个session则不再向数据发出语句直接从缓存取出
User user2 = userMapper.findUserById(1);
System.out.println(user2);
//关闭session
session.close();
而当我们提交Commit之后呢?1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16//获取session
SqlSession session = sqlSessionFactory.openSession();
//获限mapper接口实例
UserMapper userMapper = session.getMapper(UserMapper.class);
//第一次查询
User user1 = userMapper.findUserById(1);
System.out.println(user1);
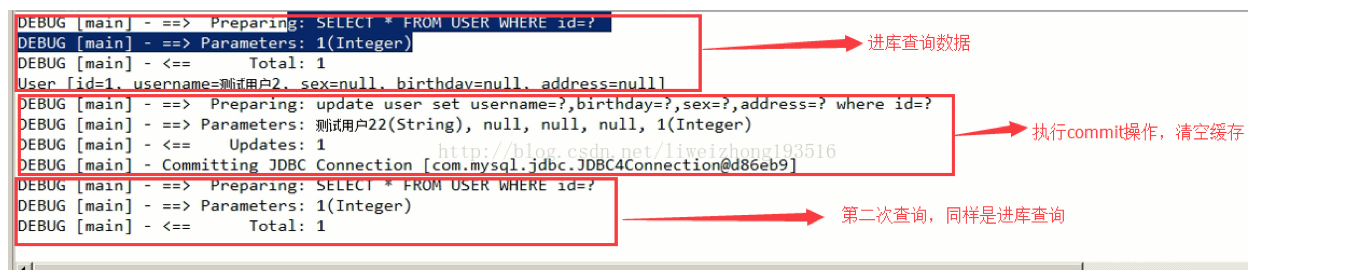
//在同一个session执行更新
User user_update = new User();
user_update.setId(1);
user_update.setUsername("张三");
userMapper.updateUser(user_update);
session.commit();
//第二次查询,虽然是同一个session但是由于执行了更新操作session的缓存被清空,这里重新发出sql操作
User user2 = userMapper.findUserById(1);
System.out.println(user2);
由此可见,Mybatis的一级缓存是存在与SqlSession中,可以提高我们的查询性能,但是不能实现多sql的session的共享。
二级缓存
二级缓存区域是根据mapper的namespace划分的,相同namespace的mapper查询数据放在同一个区域,如果使用mapper代理方法每个mapper的namespace都不同,此时可以理解为二级缓存区域是根据mapper划分,也就是根据命名空间来划分的,如果两个mapper文件的命名空间一样,那样,他们就可以共享一个mapper缓存。
每次查询会先从缓存区域找,如果找不到从数据库查询,查询到数据将数据写入缓存。
Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+Sql语句。value为从查询出来映射生成的Java对象
sqlSession执行insert、update、delete等操作commit提交后会清空缓存区域。

开启二级缓存
然后还要在Mapper映射文件中添加一行:1
<cache/> <!--<span >表示此mapper开启二级缓存-->
假如说,已开启二级缓存的Mapper中有个statement要求禁用怎么办,那也不难,只需要在statement中设置useCache=false就可以禁用当前select语句的二级缓存,也就是每次都会生成sql去查询
ps:默认情况下默认是true,也就是默认使用二级缓存1
<select id="findOrderListResultMap" resultMap="ordersUserMap" useCache="false">
刷新缓存:
在mapper的同一个namespace中,如果有其他insert、update、delete操作后都需要执行刷新缓存操作,来避免脏读。这时我们只需要设置statement配置中的flushCache=“true“属性,就会默认刷新缓存,相反如果是false就不会了。当然,不管开不开缓存刷新功能,你要是手动更改数据库表,那都肯定不能避免脏读的发生,那就属于手贱了。1
<insert id="insertUser" parameterType="cn.ssm.mybatis.po.User" flushCache="true">
那既然能够刷新缓存,能定时刷新吗?也就是设置时间间隔来刷新缓存,答案是肯定的。我们在mapper映射文件中添加1
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
而这个例子更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此在不同线程中的调用者之间修改它们会导致冲突。可用的收回策略有, 默认的是 LRU:
- LRU – 最近最少使用的:移除最长时间不被使用的对象。
- FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
- SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
- WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
Mybatis这么好,如何应用呢?
因为这是一种缓存机制嘛,只有相对于实时性要求不高的需求才会使用缓存机制,它也一样。对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度
业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
可是,好归好,Mybatis也有它一定的局限性。那就是Mybatis对于细粒度的数据级别的缓存实现的不是太好,也就是如果同Mapper下的商品类别繁多的话,他不能实现只刷新某固定商品的信息,而只能全盘刷新。当时将这块的时候我想过让Mapper水平分区不就行了,可是后来说到Mybatis的二级缓存是以命名空间划分的或者说是以Mapper划分,不管我们怎么水平划分,只要命名空间一样,那就只共享一个二级缓存域,当刷新的时候还是会全Mapper更新一遍。
参考
https://blog.csdn.net/liweizhong193516/article/details/53639350
https://www.cnblogs.com/DoubleEggs/p/6243223.html
https://www.cnblogs.com/happyflyingpig/p/7739749.html