建表示例:
create ‘namespace:tablename’, {NUMREGIONS => 5, SPLITALGO => ‘HexStringSplit’}, {NAME => ‘f’, COMPRESSION=>’SNAPPY’, VERSIONS => 1}
提建表邮件时,建表语句请在测试环境测试成功后,再提交。
建表心得
hbase号称支持上亿行,上百万列数据的实时随机读写。但是拥有这样功能的前提是要有良好的表结构设计,否则使用hbase反倒会适得其反。
下面是我们的一些hbase表设计心得,供大家参考。
- rowkey的设计,尽量使用较短的family长度,最好一个字符
hbase是一个key-value数据库,大家初次使用hbase时,往往会查一些博客等资料,逻辑上看它一行可以包含多个列,列数可以不固定,这是hbase的一个优势。有一点需要注意:hbase虽然一个rowkey可以对应很多列(column),但是由于key-value数据库的性质,每存一列,rowkey就同样也要再存一次,hbase也不例外。如下表:
下面的是简略表,真正存储比这个要复杂,大致意思明白就行
逻辑视图:

物理存储格式:
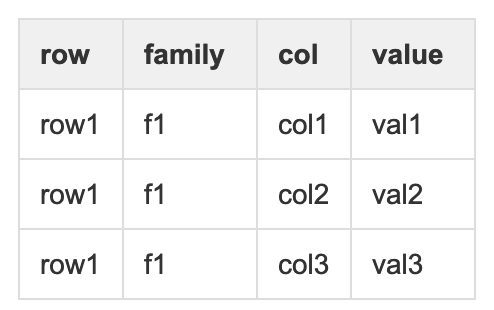
row和family会多次存放,会有数据冗余,所以只要在能够区分family的情况下,family越小越好。
而且这样的结构也表明:数据放在rowkey里面,或者放在value里面,在存储空间的占用上区别并不大,主要就是访问方式的区别,所以应该根据自己的业务需求,设计适合自己的rowkey。
设计表时,尽量避免单行过大的情况,如果单行过大的话,访问该行有可能导致regionserver卡死的情况。
数据量超过100G时,进行预分区 pre-split
为什么要预分区:hbase的rowkey是全局有序的,hbase将它的数据分散在各个regionserver中,每个regionserver的数据都存放一部分数据,而且有一个startKey和endKey,只有这个范围内的数据才会被这个regionserver存放。而且各个regionserver的startKey和endKey是没有重叠的。
- 最开始hbase的表是只有一个region的,首先数据不断的写入该region,当数据量到达一定程度后,region会进行split操作,分裂为2个region,然后各自负责各自的rowkey范围。
- 可以看到:假如要迁移到新集群,创建了一个表,默认只有一个region,往hbase中导数据时,开始的时候只会不断的往一个region里面写,这样这个region就成为一个单点问题。
- 希望最开始也能同时往多个机器中写数据:pre-split:可以预先定义region的个数,以及它们的starKey和rowKey,这样就可以均衡的将压力分散到各个机器上。
pre-split算法:
目前hbase支持两种split算法:
HexStringSplit 和 UniformSplit。
- HexStringSplit:主要针对16进制开头的rowkey,可以将这类数据均匀分散,例如采用md5等hash算法作为前缀的row。
- UniformSplit :主要针对分布均匀的二进制数组。
region个数:
目前公司的hbase单个region设置100G,如果预测表的数据量较大的话,预先分一部分region,保证能够将压力分散到各个节点,region初始设置为5个即可。
压缩
hbase的压缩效果非常好,目前有两种压缩方案:compression和Data Block EncodingCompression:这种压缩针对数据块进行压缩,压缩方式一般采用SNAPPY,压缩比例可以达到70%,而且对解压缩开销很小,大大降低了磁盘使用。
Data Block Encoding:这种是针对rowkey的压缩,比如之前提到的,列数较多的话,row会多次存放,这种方案会将rowkey中相同的前缀进行压缩,类似字典树(trie-tree)。
虽然从压缩率、CPU利用率以及性能上来看,prefix_tree编码确实会比snappy压缩更加优秀。但线上遇到了很大的坑:compaction一直卡住,详见HBASE-12959,还可能造成scan miss,详见HBASE-12817。该功能目前还属于实验性质特性-experimental feature。鉴于安全考虑,prefix_tree功能建议不要设置,即禁止使用DATA_BLOCK_ENCODING => ‘PREFIX_TREE’,使用NONE。
- 不推荐使用多版本
hbase虽然支持多版本,但是这个功能有些鸡肋,默认最大可以将版本数设置为Integer.MAX_VALUE,但是如果真的插入了接近该数量的版本,会有一些风险。比如:
compaction的时候很可能会out of memory
单个rowkey数据过多的时候,region不会进行split。