原文连接:http://blog.cloudera.com/blog/2013/11/approaches-to-backup-and-disaster-recovery-in-hbase/
下面是部分翻译:
title: hbase的备份和容灾
purpose:了解hbase现有的备份方案,以及如何在不同的场景下恢复数据
随着hbase的广泛使用,越来越多的企业使用hbase作为其数据存储,但是能够保证PB级数据的及时恢复,hadoop和hbase提供了一些内在机制来满足这些功能。
以往都是用户都是在一个比较抽象,高层的角度来操作备份,读了这篇文章,你应该能够更专业的来为你的业务定制最合适的备份策略。本文帮助你了解各个备份的优缺点和它们的使用场景。
有以下几种备份方式:
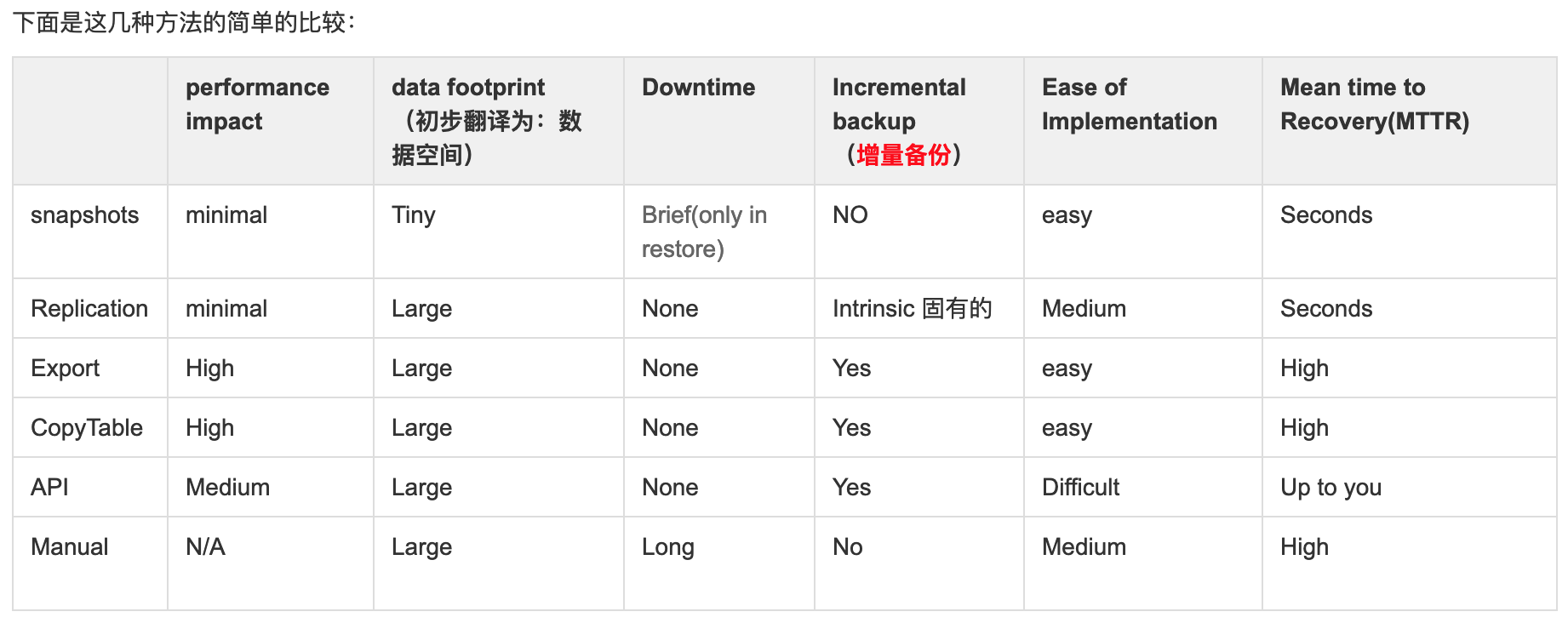
- snapshots
- replication
- export
- copytable
- Htable API
- offline backup of HDFS data
下面是这几种方法的简单的比较:
snapshots
snapshots功能齐全,而且不需要停掉集群。下面的文章有详细的解释:https://blog.cloudera.com/blog/2013/03/introduction-to-apache-hbase-snapshots/
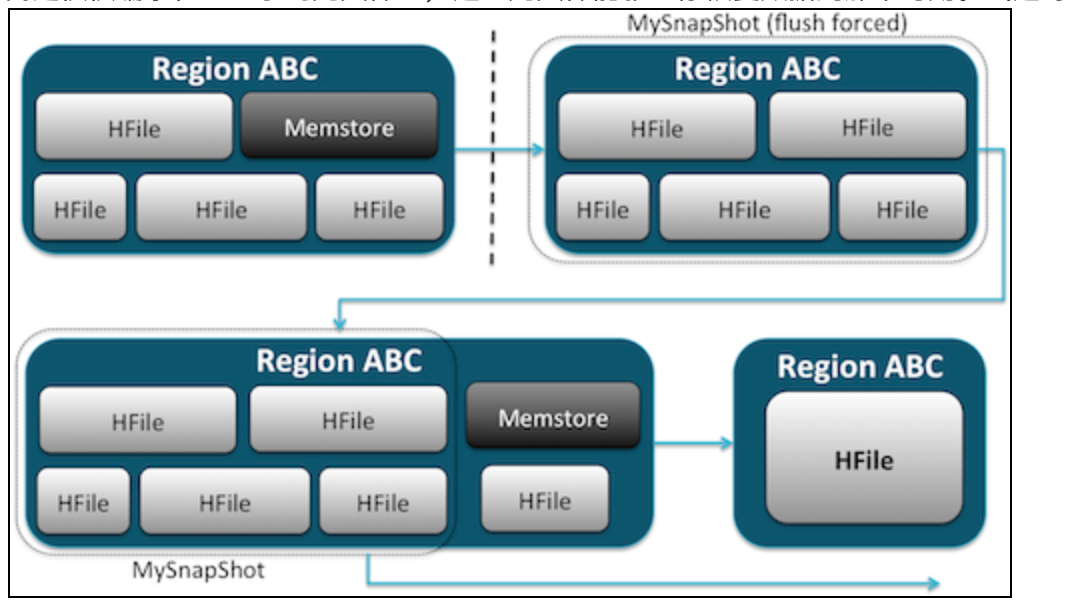
这里大致说一下:snapshot是通过创建HDFS文件系统上,某个时刻的linux硬连接来实现的。可以在秒级内完成,几乎对集群没有性能影响,占用非常小的数据空间。数据并没有存放多份,
而是仅仅编录在一些小的元文件里,这些元文件能够让你恢复数据到那个时刻。(这句翻译不大懂)
运行如下命令就可以创建snapshots:1
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
之后你会发现在/hbase/.snapshot/mytable会有很多小文件,它们就是snapshots的文件,要执行恢复操作:1
2
3hbase(main):002:0> disable 'myTable'
hbase(main):003:0> restore_snapshot 'MySnapShot'
hbase(main):004:0> enable 'myTable'
执行snapshot需要disable表,执行之后,任何在这个时间点之后的操作都会清除。所以如果需要,请使用exportSnapshot来备份你的数据。
snapshot只是记录是个时间点表的状态,并不支持增量snapshot。
Replication
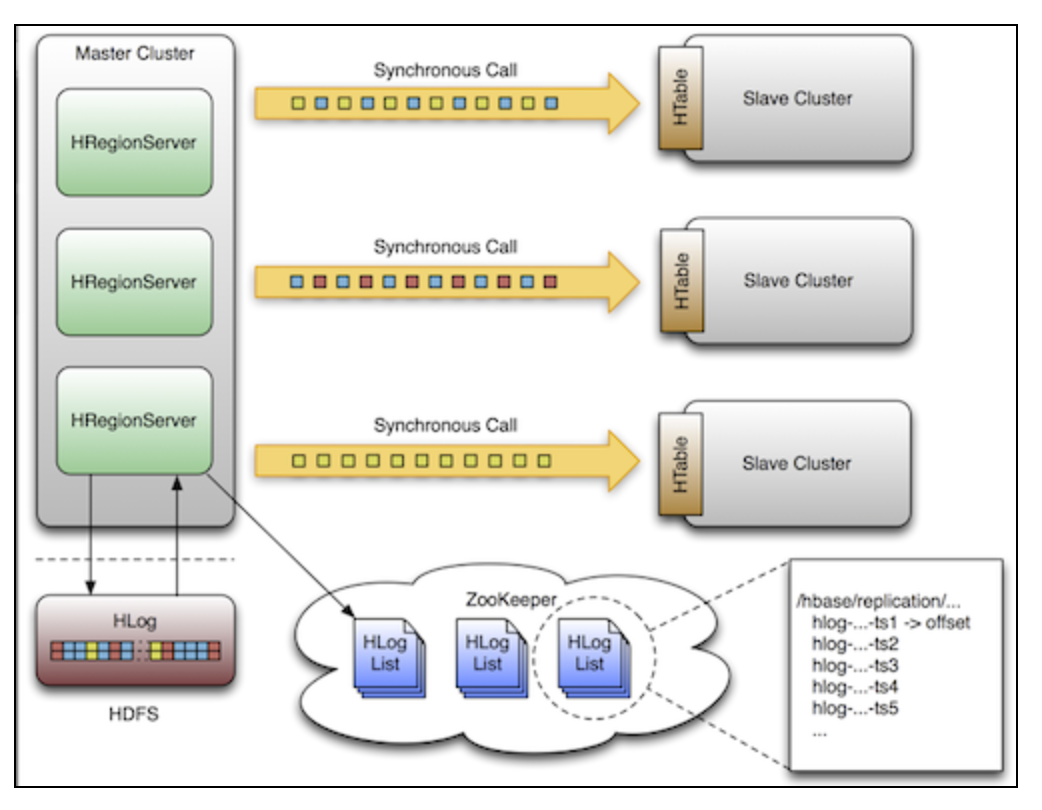
replication也是一个并不占用多少资源的备份工具,详细请看:http://blog.cloudera.com/blog/2012/07/hbase-replication-overview-2/
replication可以精细到family级别,在后台工作,并且保证主从集群之间的数据一致。
它有3种模式:主从、主主、循环(cyclic)。你可以灵活的从多个数据源来注入数据到你的数据中心,也可以确保你的数据在其他从集群上备份。
如果发生集群宕机,可以通过DNS工具来将访问重定位到从节点。
replication是强大的,保证容错的,并提供了最终一致性(eventual consistency),意味着:可能某一时刻数据并不一致,但最终会一致的。
note:对于已经存在的表,你应该首先采用上述的某一个方案来将源数据拷贝到从集群,replication只有在你启动之后才会生效。
Export
export是hbase内置的一个工具,它会启动mapreduce程序,并且使用hbase的api来逐条的读取hbase中的数据,并将它们存到你指定的HDFS的文件中。
这个工具比较占用资源,因为启动了MR,但是功能很齐全,因为可以使用hbase的api,可以指定版本和范围,因此可以支持增量备份。
简单的例子:1
hbase org.apache.hadoop.hbase.mapreduce.Export <tablename> <outputdir>
export之后,你可以把导出的文件转移到任何地方,更方便的是你可以直接指定outputdir为一个远程路径,export将直接通过网络将数据导到那。
CopyTable
详情:http://blog.cloudera.com/blog/2012/06/online-hbase-backups-with-copytable-2/
copytable 和export很像,有一个关键的不同:copytable可以直接将主集群中的表数据直接导入到backup集群中的backup表中。
简单的例子:1
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
该指令将一个名为”test“表的数据复制到同一集群中的”testCopy“表中。(也可以远程复制)
注意一下几点:它是通过put来操作,会写从节点的momstore,会flush,也会出发compaction,GC,而且主集群也是运行mapreduce,也会占用资源,
所以当要拷贝大量数据时,这种方法不是很合适。
API方式
这个不用多说了,自己写,自己调,性能好坏和程序员水准有关。
离线通过HDFS文件备份(严重不推荐)
这是最野蛮,破坏性的备份,并且会占用大量的数据空间。关闭hbase集群,它是直接将/hbase下的所有文件拷贝出来。并且这样肯定不支持增量备份。
而且在你恢复数据时,还要对META表进行修复,所以这个方法不推荐。
hbase的容灾
主要有以下需求:
1.数据中心挂了。
2.有误删操作,要恢复
3.恢复到某一个时间点,来进行审计
如果使用Replication时,采用DNS工具可以使自动切换到从集群,如果住集群好了,那么要保证在宕机之后从集群的更新数据同步到主集群,
主主方式和循环方式已经自动帮你做了,主从模式需要你自己手动来做。
若采用replication来保证备份,那么假如主节点一开始就有数据,在批量导出的过程中,如何保证这个过程的数据同步到从节点?