ZooKeeper:协调者
ZooKeeper为HBase集群提供协调服务
- 它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster,从而HMaster可以实现HMaster之间的failover
- 对宕机的HRegionServer中的HRegion集合的修复(将它们分配给其他的HRegionServer)。ZooKeeper集群本身使用一致性协议(PAXOS协议)保证每个节点状态的一致性。
- 通过Zoopkeeper存储元数据的统一入口地址
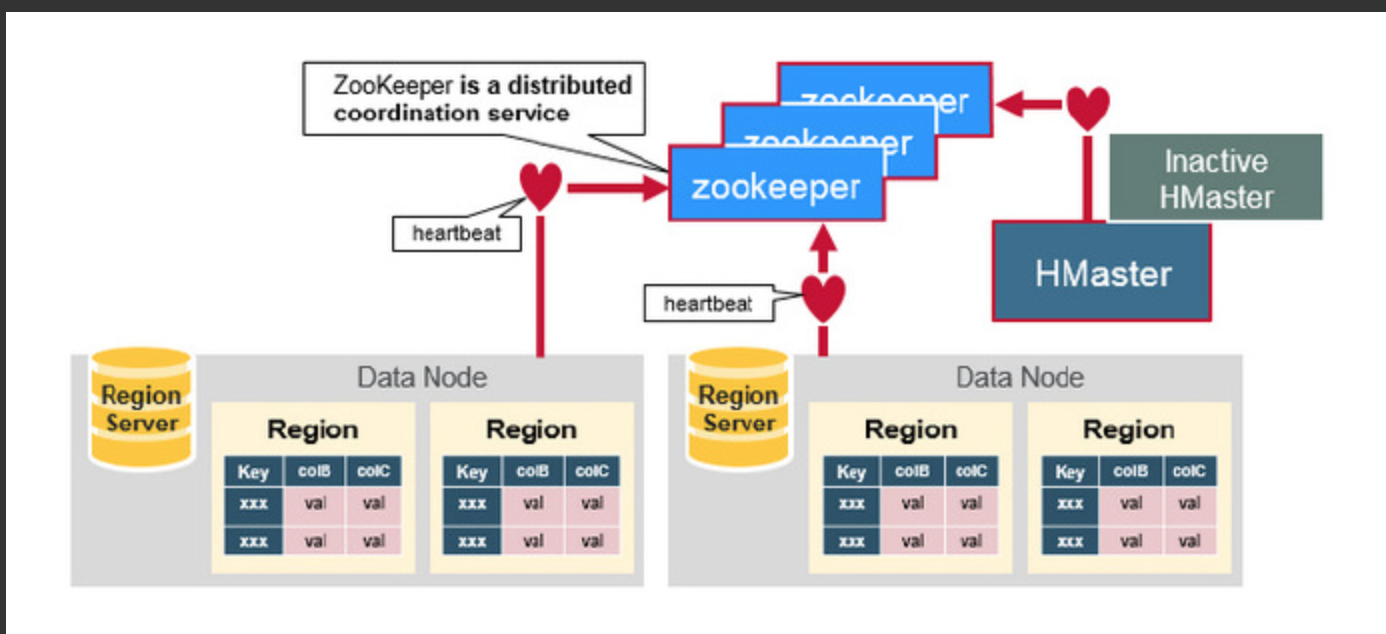
How The Components Work Together
ZooKeeper协调集群所有节点的共享信息,在HMaster和HRegionServer连接到ZooKeeper后创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节点实效,则HMaster会收到通知,并做相应的处理。
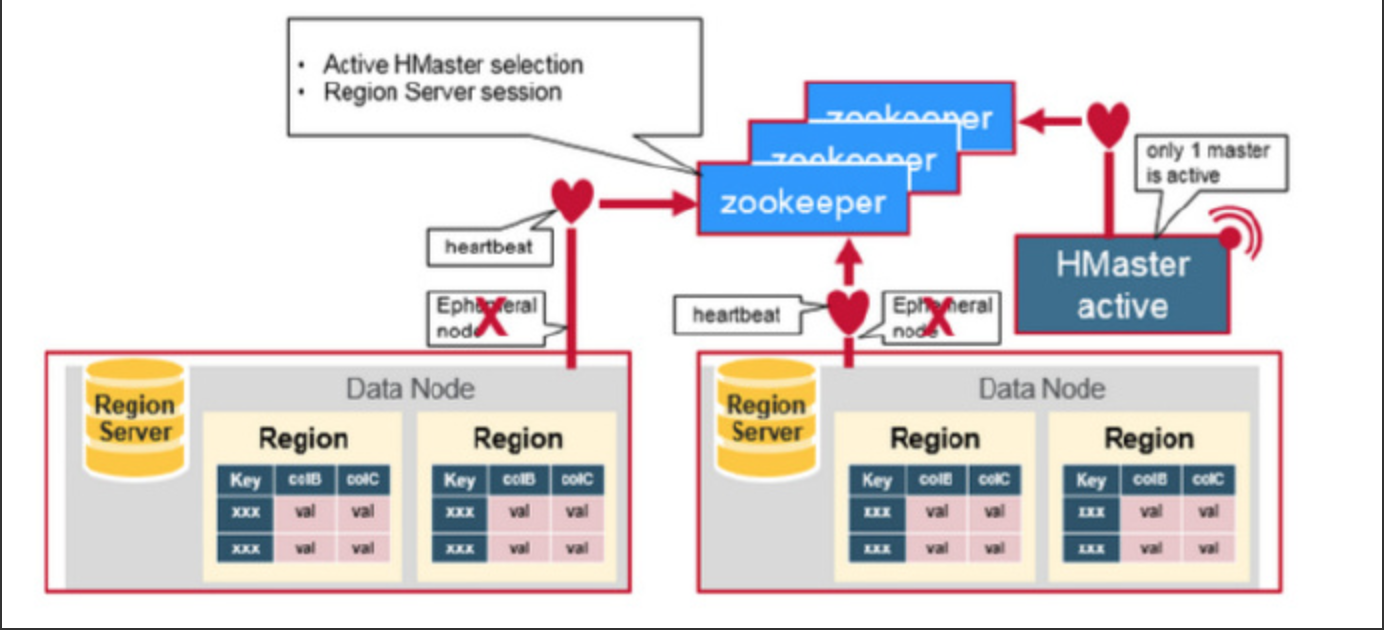
另外,HMaster通过监听ZooKeeper中的Ephemeral节点(默认:/hbase/rs/*)来监控HRegionServer的加入和宕机。在第一个HMaster连接到ZooKeeper时会创建Ephemeral节点(默认:/hbasae/master)来表示Active的HMaster,其后加进来的HMaster则监听该Ephemeral节点,如果当前Active的HMaster宕机,则该节点消失,因而其他HMaster得到通知,而将自身转换成Active的HMaster,在变为Active的HMaster之前,它会创建在/hbase/back-masters/下创建自己的Ephemeral节点。
HBase中的AssignmentManager
AssignmentManager模块是HBase中一个非常重要的模块,Assignment Manager(之后简称AM)负责了HBase中所有region的Assign,UnAssign,以及split/merge过程中region状态变化的管理等等。在HBase-0.90之前,AM的状态全部存在内存中,自从HBASE-2485之后,AM把状态持久化到了Zookeeper上。在此基础上,社区对AM又修复了大量的bug和优化(见此文章),最终形成了用在HBase-1.x版本上的这个AM。
老Assignment Mananger的问题
相信深度使用过HBase的人一般都会被Region RIT的状态困扰过,长时间的region in transition状态简直令人抓狂。
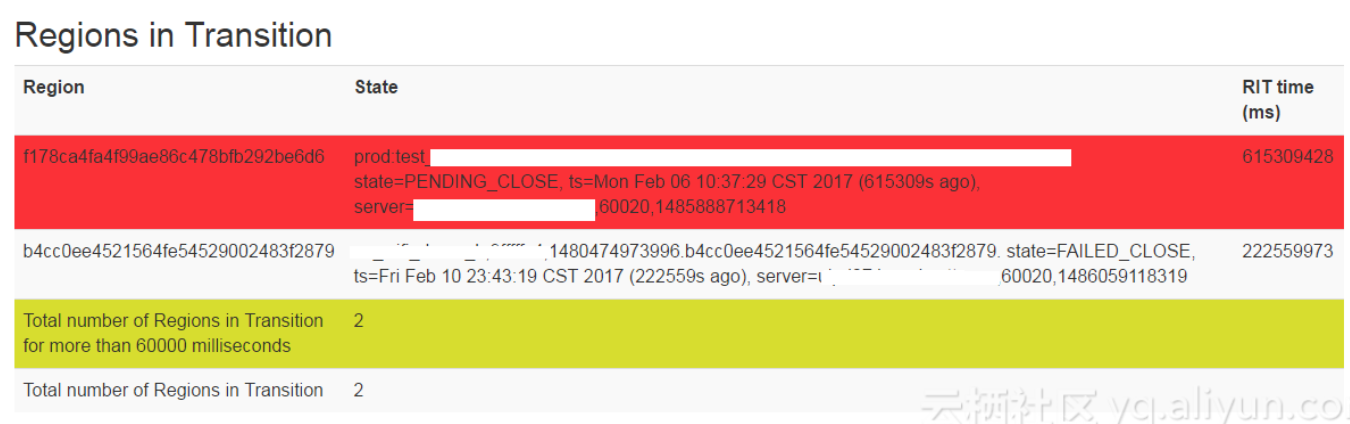
除了一些确实是由于Region无法被RegionServer open的case,大部分的RIT,都是AM本身的问题引起的。总结一下HBase-1.x版本中AM的问题,主要有以下几点:
region状态变化复杂
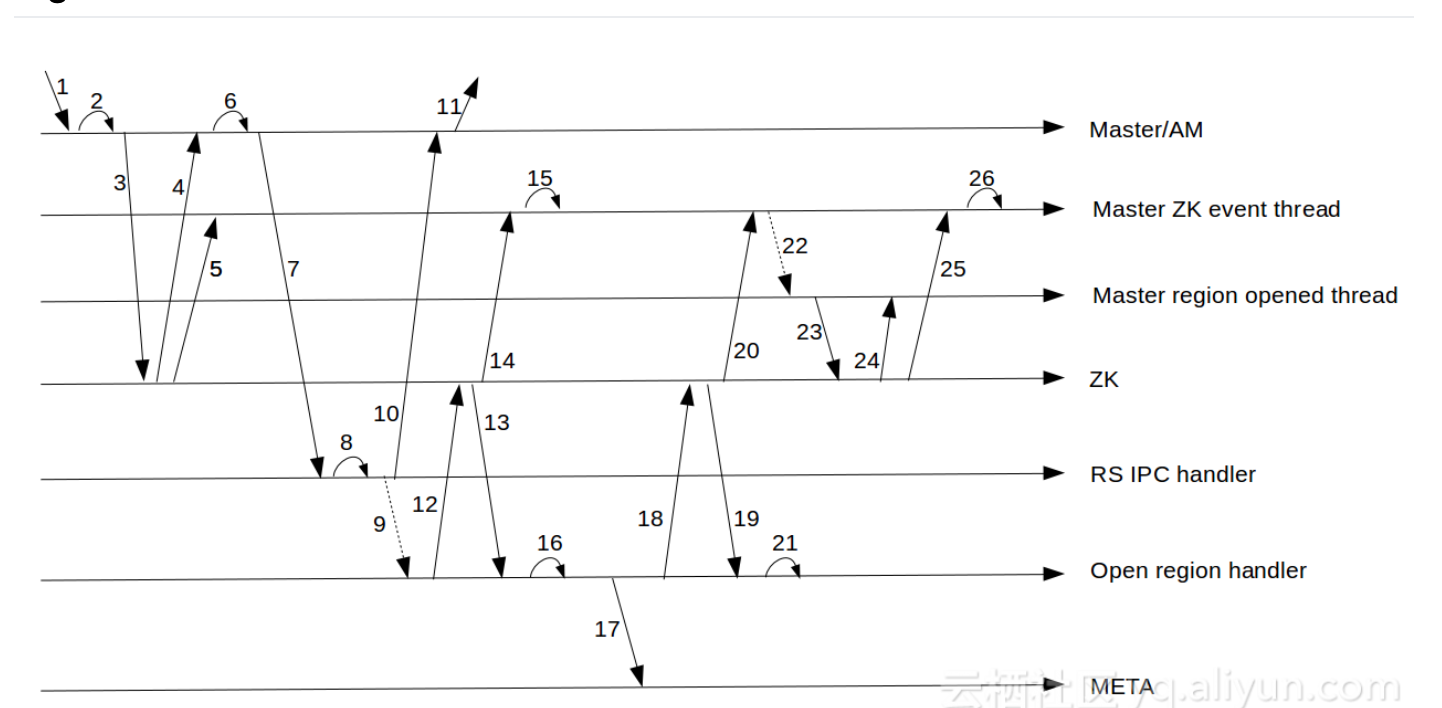
这张图很好地展示了region在open过程中参与的组件和状态变化。可以看到,多达7个组件会参与region状态的变化。并且在region open的过程中多达20多个步骤!越复杂的逻辑意味着越容易出bug
region状态多处缓存
region的状态会缓存在多个地方,Master中RegionStates会保存Region的状态,Meta表中会保存region的状态,Zookeeper上也会保存region的状态,要保持这三者完全同步是一件很困难的事情。同时,Master和RegionServer都会修改Meta表的状态和Zookeeper的状态,非常容易导致状态的混乱。如果出现不一致,到底以哪里的状态为准?每一个region的transition流程都是各自为政,各自有各自的处理方法
重度依赖Zookeeper
在老的AM中,region状态的通知完全通过Zookeeper。比如说RegionServer打开了一个region,它会在Zookeeper把这个region的RIT节点改成OPEN状态,而不去直接通知Master。Master会在Zookeeper上watch这个RIT节点,通过Zookeeper的通知机制来通知Master这个region已经发生变化。Master再根据Zookeeper上读取出来的新状态进行一定的操作。严重依赖Zookeeper的通知机制导致了region的上线/下线的速度存在了一定的瓶颈。特别是在region比较多的时候,Zookeeper的通知会出现严重的滞后现象。
正是这些问题的存在,导致AM的问题频发。
Assignment Mananger V2
在这个设计中,它摒弃了Zookeeper这个持久化的存储,一些region transition过程中的中间状态无法被保存。因此,在此基础上,社区又更进了一步,提出了Assignment Mananger V2在这个方案。在这个方案中,仍然摒弃了Zookeeper参与Assignment的整个过程。但是,它引入了ProcedureV2这个持久化存储来保存Region transition中的各个状态,保证在master重启时,之前的assing/unassign,split等任务能够从中断点重新执行。具体的来说,AMv2方案中,主要的改进有以下几点:
Procedure V2
Master中会有许多复杂的管理工作,比如说建表,region的transition。这些工作往往涉及到非常多的步骤,如果master在做中间某个步骤的时候宕机了,这个任务就会永远停留在了中间状态(RIT因为之前有Zookeeper做持久化因此会继续从某个状态开始执行)。比如说在enable/disable table时,如果master宕机了,可能表就停留在了enabling/disabling状态。需要一些外部的手段进行恢复。那么从本质上来说,ProcedureV2提供了一个持久化的手段(通过ProcedureWAL,一种类似RegionServer中WAL的日志持久化到HDFS上),使master在宕机后能够继续之前未完成的任务继续完成。同时,ProcedureV2提供了非常丰富的状态转换并支持回滚执行,即使执行到某一个步骤出错,master也可以按照用户的逻辑对之前的步骤进行回滚。比如建表到某一个步骤失败了,而之前已经在HDFS中创建了一些新region的文件夹,那么ProcedureV2在rollback的时候,可以把这些残留删除掉。
Procedure中提供了两种Procedure框架,顺序执行和状态机,同时支持在执行过程中插入subProcedure,从而能够支持非常丰富的执行流程。在AMv2中,所有的Assign,UnAssign,TableCreate等等流程,都是基于Procedure实现的。
去除Zookeeper依赖
有了Procedure V2之后,所有的状态都可以持久化在Procedure中,Procedure中每次的状态变化,都能够持久化到ProcedureWAL中,因此数据不会丢失,宕机后也能恢复。同时,AMv2中region的状态扭转(OPENING,OPEN,CLOSING,CLOSE等)都会由Master记录在Meta表中,不需要Zookeeper做持久化。再者,之前的AM使用的Zookeeper watch机制通知master region状态的改变,而现在每当RegionServer Open或者close一个region后,都会直接发送RPC给master汇报,因此也不需要Zookeeper来做状态的通知。综合以上原因,Zookeeper已经在AMv2中没有了存在的必要。
减少状态冲突的可能性
之前我说过,在之前的AM中,region的状态会同时存在于meta表,Zookeeper和master的内存状态。同时Master和regionserver都会去修改Zookeeper和meta表,维护状态统一的代价非常高,非常容易出bug。而在AMv2中,只有master才能去修改meta表。并在region整个transition中做为一个“权威”存在,如果regionserver汇报上来的region状态与master看到的不一致,则master会命令RegionServer abort。Region的状态,都以master内存中保存的RegionStates为准。
除了上述这些优化,AMv2中还有许多其他的优化。比如说AMv2依赖Procedure V2提供的一套locking机制,保证了对于一个实体,如一张表,一个region或者一个RegionServer同一时刻只有一个Procedure在执行。同时,在需要往RegionServer发送命令,如发送open,close等命令时,AMv2实现了一个RemoteProcedureDispatcher来对这些请求做batch,批量把对应服务器的指令一起发送等等。在代码结构上,之前处理相应region状态的代码散落在AssignmentManager这个类的各个地方,而在AMv2中,每个对应的操作,都有对应的Procedure实现,如AssignProcedure,DisableTableProcedure,SplitTableRegionProcedure等等。这样下来,使AssignmentManager这个之前杂乱的类变的清晰简单,代码量从之前的4000多行减到了2000行左右。
AssignProcedure
讲解一下在AMv2中,一个region是怎么assign给一个RegionServer,并在对应的RS上Open的。
REGION_TRANSITION_QUEUE
Assign开始时的状态。在这个状态时,Procedure会对region状态做一些改变和存储,并丢到AssignmentManager的assign queue中。对于单独region的assign,AssignmentManager会把他们group起来,再通过LoadBalancer分配相应的服务器。当这一步骤完成后,Procedure会把自己标为REGION_TRANSITION_DISPATCH,然后看是否已经分配服务器,如果还没有被分配服务器的话,则会停止继续执行,等待被唤醒。
REGION_TRANSITION_DISPATCH
当AssignmentManager为这个region分配好服务器时,Procedure就会被唤醒。或者Procedure在执行完REGION_TRANSITION_QUEUE状态时master宕机,Procedure被恢复后,也会进入此步骤执行。所以在此步骤下,Procedure会先检查一下是否分配好了服务器,如果没有,则把状态转移回REGION_TRANSITION_QUEUE,否则的话,则把这个region交给RemoteProcedureDispatcher,发送RPC给对应的RegionServer来open这个region。同样的,RemoteProcedureDispatcher也会对相应的指令做一个batch,批量把一批region open的命令发送给某一台服务器。当命令发送完成之后,Procedure又会进入休眠状态,等待RegionServer成功OPen这个region后,唤醒这个Procedure
REGION_TRANSITION_FINISH
当有RegionServer汇报了此region被打开后,会把Procedure的状态置为此状态,并唤醒Procedure执行。此时,AssignProcedure会做一些状态改变的工作,并修改meta表,把meta表中这个region的位置指向对应的RegionServer。至此,region assign的工作全部完成。
AMv2中提供了一个Web页面(Master页面中的‘Procedures&Locks’链接)来展示当前正在执行的Procedure和持有的锁。
其实通过log,我们也可以看到Assign的整个过程。
总结
Assignment Mananger V2依赖Procedure V2实现了一套清晰明了的region transition机制。去除了Zookeeper依赖,减少了region状态冲突的可能性。整体上来看,代码的可读性更强,出了问题也更好查错。对于解决之前AM中的一系列“顽疾”,AMv2做了很好的尝试,也是一个非常好的方向。
AMv2之所以能保持简洁高效的一个重要原因就是重度依赖了Procedure V2,把一些复杂的逻辑都转移到了Procedure V2中。但是这样做的问题是:一旦ProcedureWAL出现了损坏,或者Procedure本身存在bug,这个后果就是灾难性的。
此时并不是说zookeep在hbase中已经没用了,原数据存储,Hmaster的failover还是需要zk的。