Hbase Region的三种拆分策略
Hbase Region的拆分策略有比较多,比如除了3种默认过的策略,还有DelimitedKeyPrefixRegionSplitPolicy、KeyPrefixRegionSplitPolicy、DisableSplitPolicy等策略,这里只介绍3种默认的策略。分别是ConstantSizeRegionSplitPolicy策略、IncreasingToUpperBoundRegionSplitPolicy策略和SteppingSplitPolicy策略。
ConstantSizeRegionSplitPolicy
ConstantSizeRegionSplitPolicy策略是0.94版本之前的默认拆分策略,这个策略的拆分规则是:当region大小达到hbase.hregion.max.filesize(默认10G)后拆分。
这种拆分策略对于小表不太友好,按照默认的设置,如果1个表的Hfile小于10G就一直不会拆分。注意10G是压缩后的大小,如果使用了压缩的话。
如果1个表一直不拆分,访问量小也不会有问题,但是如果这个表访问量比较大的话,就比较容易出现性能问题。这个时候只能手工进行拆分。还是很不方便。
IncreasingToUpperBoundRegionSplitPolicy
IncreasingToUpperBoundRegionSplitPolicy策略是Hbase的0.94~2.0版本默认的拆分策略,这个策略相较于ConstantSizeRegionSplitPolicy策略做了一些优化,该策略的算法为:min(maxFileSize,r^2flushSize ),最大为maxFileSize 。
从这个算是我们可以得出maxFileSize为10G,flushsize为128M的情况下,可以计算出Region的分裂情况如下:
第一次拆分大小为:min(10G,11128M)=128M
第二次拆分大小为:min(10G,33128M)=1152M
第三次拆分大小为:min(10G,55128M)=3200M
第四次拆分大小为:min(10G,77128M)=6272M
第五次拆分大小为:min(10G,99128M)=10G
第五次拆分大小为:min(10G,1111*128M)=10G
从上面的计算我们可以看到这种策略能够自适应大表和小表,但是这种策略会导致小表产生比较多的小region,对于小表还是不是很完美。
SteppingSplitPolicy
SteppingSplitPolicy是在Hbase 2.0版本后的默认策略,,拆分规则为:If region=1 then: flush size 2 else: MaxRegionFileSize。
还是以flushsize为128M、maxFileSize为10G场景为列,计算出Region的分裂情况如下:
第一次拆分大小为:2128M=256M
第二次拆分大小为:10G
从上面的计算我们可以看出,这种策略兼顾了ConstantSizeRegionSplitPolicy策略和IncreasingToUpperBoundRegionSplitPolicy策略,对于小表也肯呢个比较好的适配。
Hbase Region拆分的详细流程
Hbase的详细拆分流程图如下:
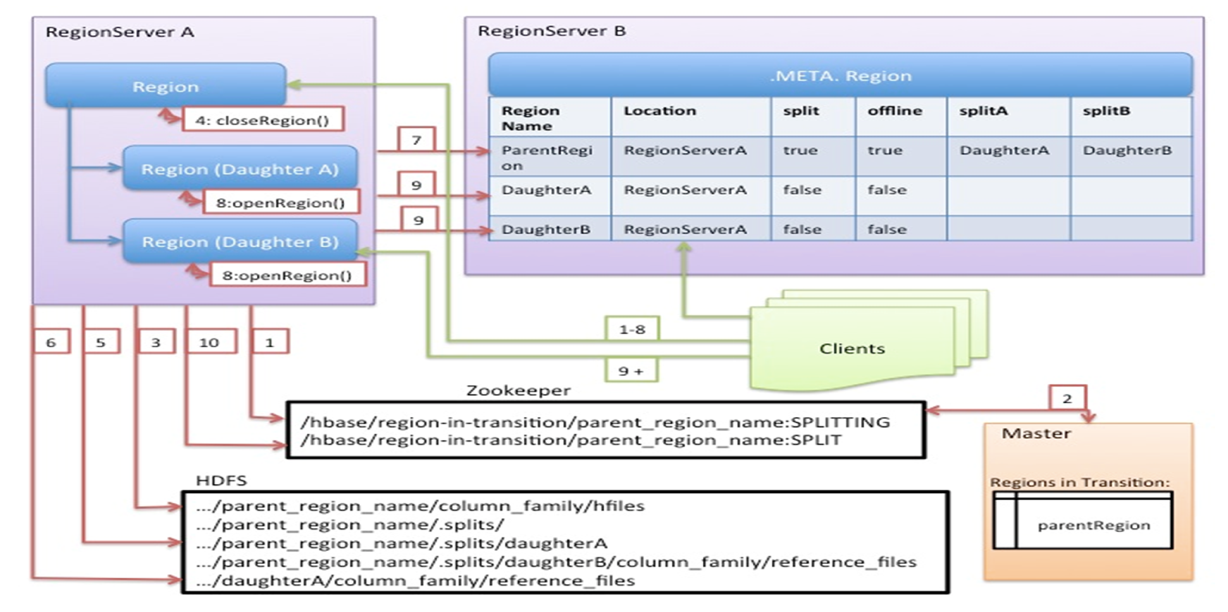
从上图我们可以看出Region切分的详细流程如下:
第1步、会在ZK的/hbase/region-in-transition/region-name下创建一个znode,并设置状态为SPLITTING
第2步、master通过watch节点检测到Region状态的变化,并修改内存中Region状态的变化
第3步、RegionServer在父Region的目录下创建一个名称 为.splits的子目录
第4步、RegionServer关闭父Region,强制将数据刷新到磁盘,并这个Region标记为offline的状态。此时,落到这个Region的请求都会返回NotServingRegionException这个错误
第5步、RegionServer在.splits创建daughterA和daughterB,并在文件夹中创建对应的reference文件,指向父Region的Region文件
第6步、RegionServer在HDFS中创建daughterA和daughterB的Region目录,并将reference文件移动到对应的Region目录中
第7步、在.META.表中设置父Region为offline状态,不再提供服务,并将父Region的daughterA和daughterB的Region添加到.META.表中,已表名父Region被拆分成了daughterA和daughterB两个Region
第8步、RegionServer并行开启两个子Region,并正式提供对外写服务
第9步、RegionSever将daughterA和daughterB添加到.META.表中,这样就可以从.META.找到子Region,并可以对子Region进行访问了
第10步、RegionServr修改/hbase/region-in-transition/region-name的znode的状态为SPLIT transition(过渡,转变,变迁)Transaction(事务)
备注:为了减少对业务的影响,Region的拆分并不涉及到数据迁移的操作,而只是创建了对父Region的指向。只有在做大合并的时候,才会将数据进行迁移。
那么通过reference文件如何才能查找到对应的数据呢?如下图所示:
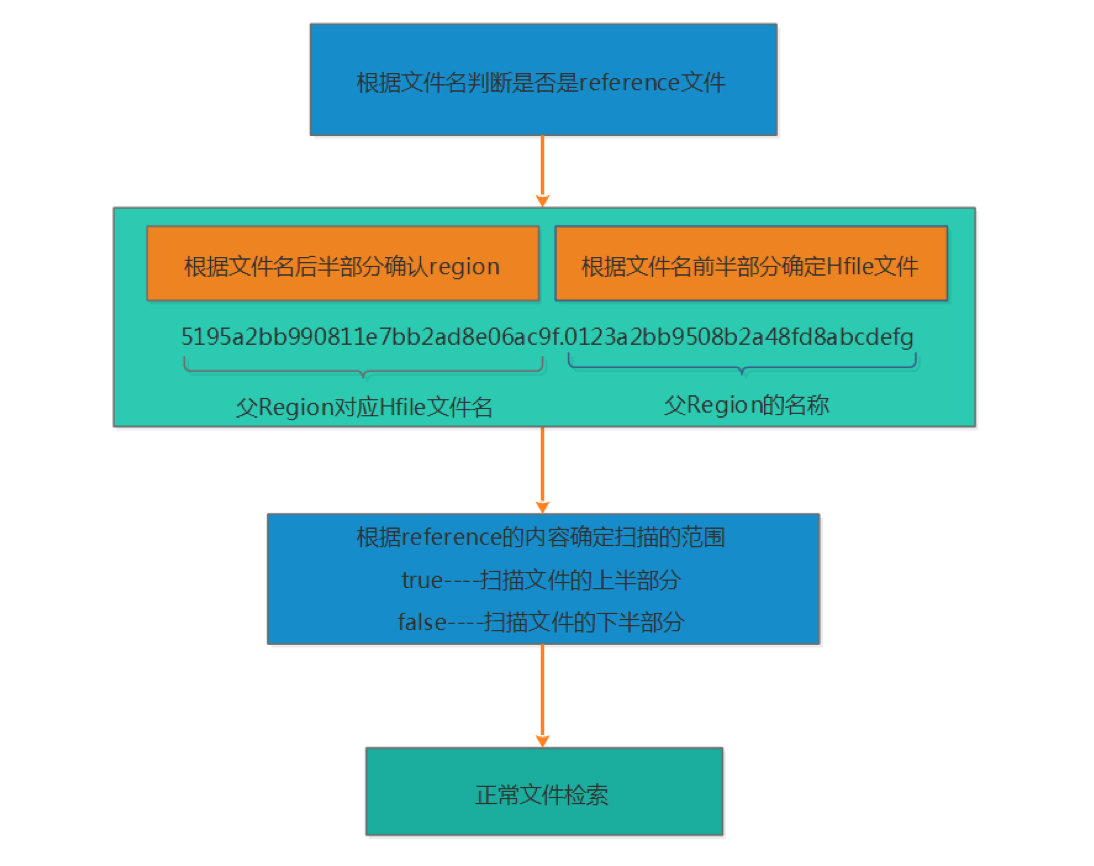
根据文件名来判断是否是reference文件
由于reference文件的命名规则为前半部分为父Region对应的File的文件名,后半部分是父Region的名称,因此读取的时候也根据前半部分和后半部分来识别
根据reference文件的内容来确定扫描的范围,reference的内容包含两部分,一部分是切分点splitkey,另一部分是boolean类型的变量(true或者false)。如果为true则扫描文件的上半部分,false则扫描文件的下半部分
接下来确定了扫描的文件,以及文件的扫描范围,那就按照正常的文件检索了