老的Region寻址方式
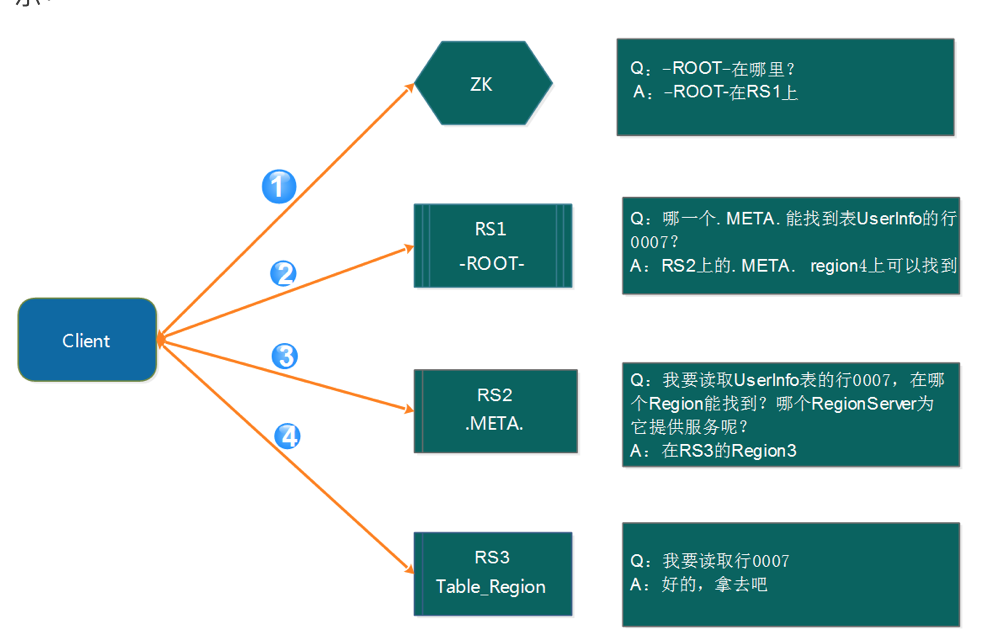
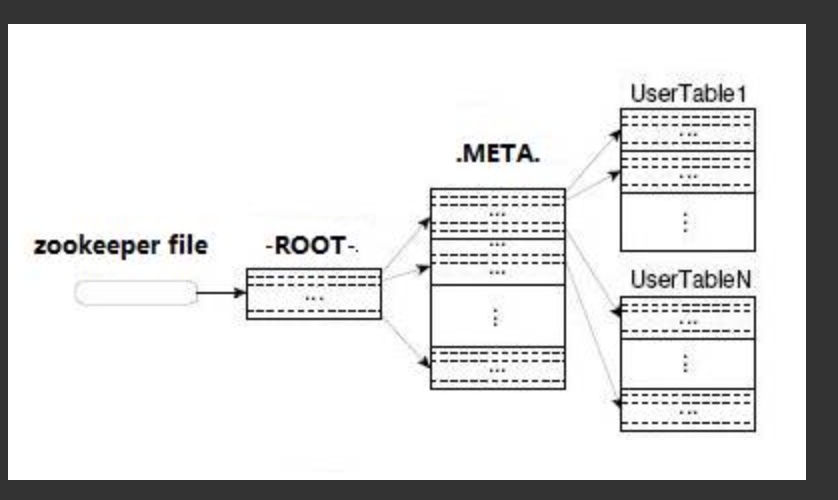
在Hbase 0.96版本以前,Hbase有两个特殊的表,分别是-ROOT-表和.META.表,其中-ROOT-的位置存储在ZooKeeper中,-ROOT-本身存储了 .META. Table的RegionInfo信息,并且-ROOT-不会分裂,只有一个region。而.META.表可以被切分成多个region 。读取的流程如下图所示:
1
2
3
4第1步:client请求ZK获得-ROOT-所在的RegionServer地址
第2步:client请求-ROOT-所在的RS地址,获取.META.表的地址,client会将-ROOT-的相关信息cache下来,以便下一次快速访问
第3步:client请求 .META.表的RS地址,获取访问数据所在RegionServer的地址,client会将.META.的相关信息cache下来,以便下一次快速访问
第4步:client请求访问数据所在RegionServer的地址,获取对应的数据
从上面的路径我们可以看出,用户需要3次请求才能直到用户Table真正的位置,然后第四次请求开始获取真正的数据,这在一定程序带来了性能的下降。在0.96之前使用3层设计的主要原因是考虑到元数据可能需要很大。但是真正集群运行,元数据的大小其实很容易计算出来。在BigTable的论文中,每行METADATA数据存储大小为1KB左右,如果按照一个Region为128M的计算,3层设计可以支持的Region个数为2^34个,采用2层设计可以支持2^17(131072)。那么2层设计的情况下一个 集群可以存储4P的数据。这仅仅是一个Region只有128M的情况下。如果是10G呢? 因此,通过计算,其实2层设计就可以满足集群的需求。因此在0.96版本以后就去掉了-ROOT-表了。
post-script:
如果一个region的大小为128m,那么就说明.META.的大小也为128M。每行METADATA数据存储大小为1KB左右,那么.META.表就可以存储
131072 KB = 128M =2^17个region. 此时按照每个region 128m大小,131072*128M = 16P,不知道为什么4P?应该是主本+三副本,16P/4=4P
3层则是-ROOT-表128M,其中每1kb的数据存储一张.META.表,总可以存128*128张.meta表即2^34张
新的Region寻址方式
如上面的计算,2层结构其实完全能满足业务的需求,因此0.96版本以后将-ROOT-表去掉了。如下图所示:
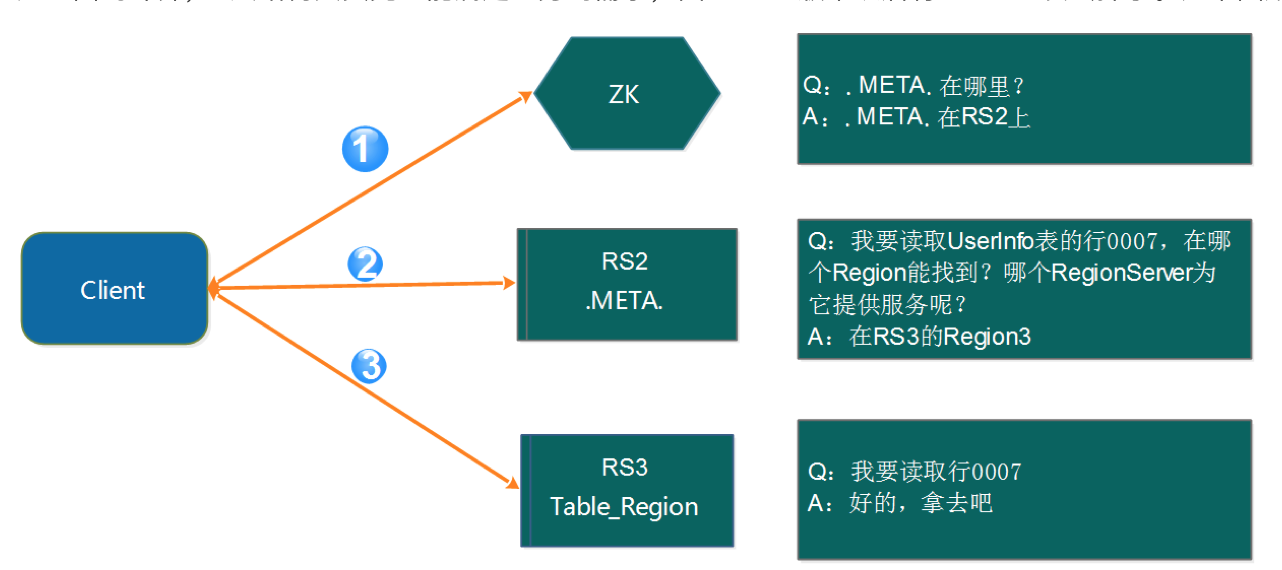
访问路径变成了3步:1
2
3第1步:Client请求ZK获取.META.所在的RegionServer的地址。
第2步:Client请求.META.所在的RegionServer获取访问数据所在的RegionServer地址,client会将.META.的相关信息cache下来,以便下一次快速访问。
第3步:Client请求数据所在的RegionServer,获取所需要的数据。
这个Meta Table如以前的-ROOT- Table一样是不可split的.
总结去掉-ROOT-的原因有如下2点:
其一:提高性能
其二:2层结构已经足以满足集群的需求
这里还有一个问题需要说明,那就是Client会缓存.META.的数据,用来加快访问,既然有缓存,那它什么时候更新?如果.META.更新了,比如Region1不在RerverServer2上了,被转移到了RerverServer3上。client的缓存没有更新会有什么情况?
其实,Client的元数据缓存不更新,当.META.的数据发生更新。如上面的例子,由于Region1的位置发生了变化,Client再次根据缓存去访问的时候,会出现错误,当出现异常达到重试次数后就会去.META.所在的RegionServer获取最新的数据,如果.META.所在的RegionServer也变了,Client就会去ZK上获取.META.所在的RegionServer的最新地址。
参考:
https://blog.csdn.net/qq_36421826/article/details/82701677
https://www.cnblogs.com/qcloud1001/p/7615526.html
https://www.cnblogs.com/ios1988/p/6266767.html
https://www.cnblogs.com/cenzhongman/p/7271761.html