我们知道,RegionServer的相关信息保存在ZK中,在RegionServer启动的时候,会在Zookeeper中创建对应的临时节点。RegionServer通过Socket和Zookeeper建立session会话,RegionServer会周期性地向Zookeeper发送ping消息包,以此说明自己还处于存活状态。而Zookeeper收到ping包后,则会更新对应session的超时时间。
当Zookeeper超过session超时时间还未收到RegionServer的ping包,则Zookeeper会认为该RegionServer出现故障,ZK会将该RegionServer对应的临时节点删除,并通知Master,Master收到RegionServer挂掉的信息后就会启动数据恢复的流程。
Master启动数据恢复流程后,其实主要的流程如下:
RegionServer宕机—》ZK检测到RegionServer异常—》Master启动数据恢复—》Hlog切分—》Region重新分配—》Hlog重放—》恢复完成并提供服务
故障恢复有3中模式,下面就一一来介绍。
Log Splitting
在最开始的恢复流程中,Hlog的整个切分过程都由于Master来执行,如下图所示:
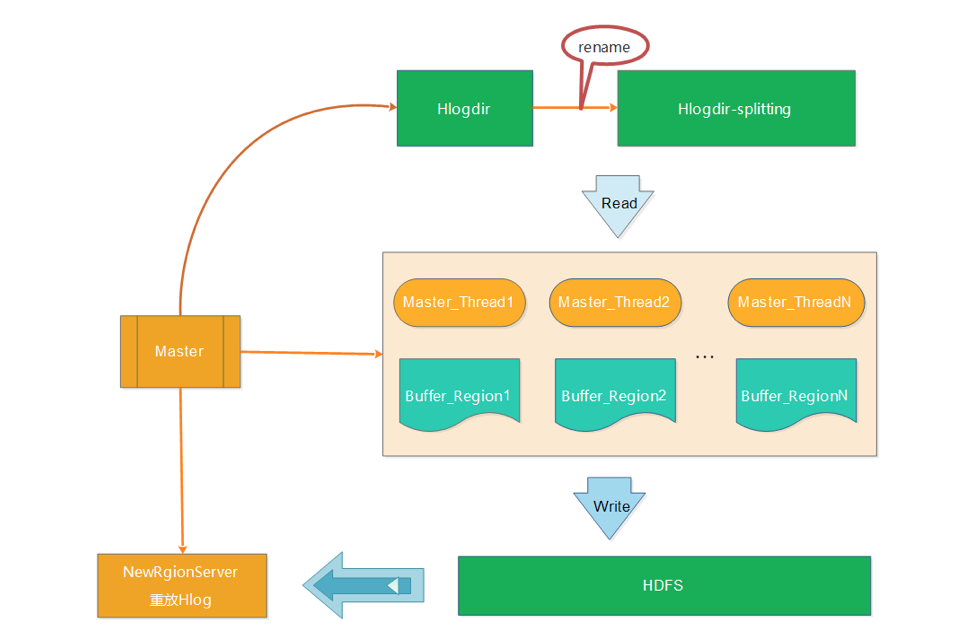
a、将待切分的日志文件夹进行重命名,防止RegionServer未真的宕机而持续写入Hlog
b、Master启动读取线程读取Hlog的数据,并将不同RegionServer的日志写入到不同的内存buffer中
c、针对每个buffer,Master会启动对应的写线程将不同Region的buffer数据写入到HDFS中,对应的路径 为/hbase/table_name/region/recoverd.edits/.tmp。
d、Master重新将宕机的RegionServer中的Rgion分配到正常的RegionServer中,对应的RegionServer读取Region的数据,会发现该region目录下的recoverd.edits目录以及相关的日志,然后RegionServer重放对应的Hlog日志,从而实现对应Region数据的恢复。
从上面的步骤中,我们可以看出Hlog的切分一直都是master在干活,效率比较低。设想,如果集群中有多台RegionServer在同一时间宕机,会是什么情况?串行修复,肯定异常慢,因为只有master一个人在干Hlog切分的活。因此,为了提高效率,开发了Distributed Log Splitting架构。
post-script:/hbase/table_name/region/为hbase表在hdfs上的实际目录
Distributed Log Splitting
顾名思义,Distributed Log Splitting是LogSplitting的分布式实现,分布式就不是master一个人在干活了,而是充分使用各个RegionServer上的资源,利用多个RegionServer来并行切分Hlog,提高切分的效率。如下图所示:
上图的操作顺序如下:
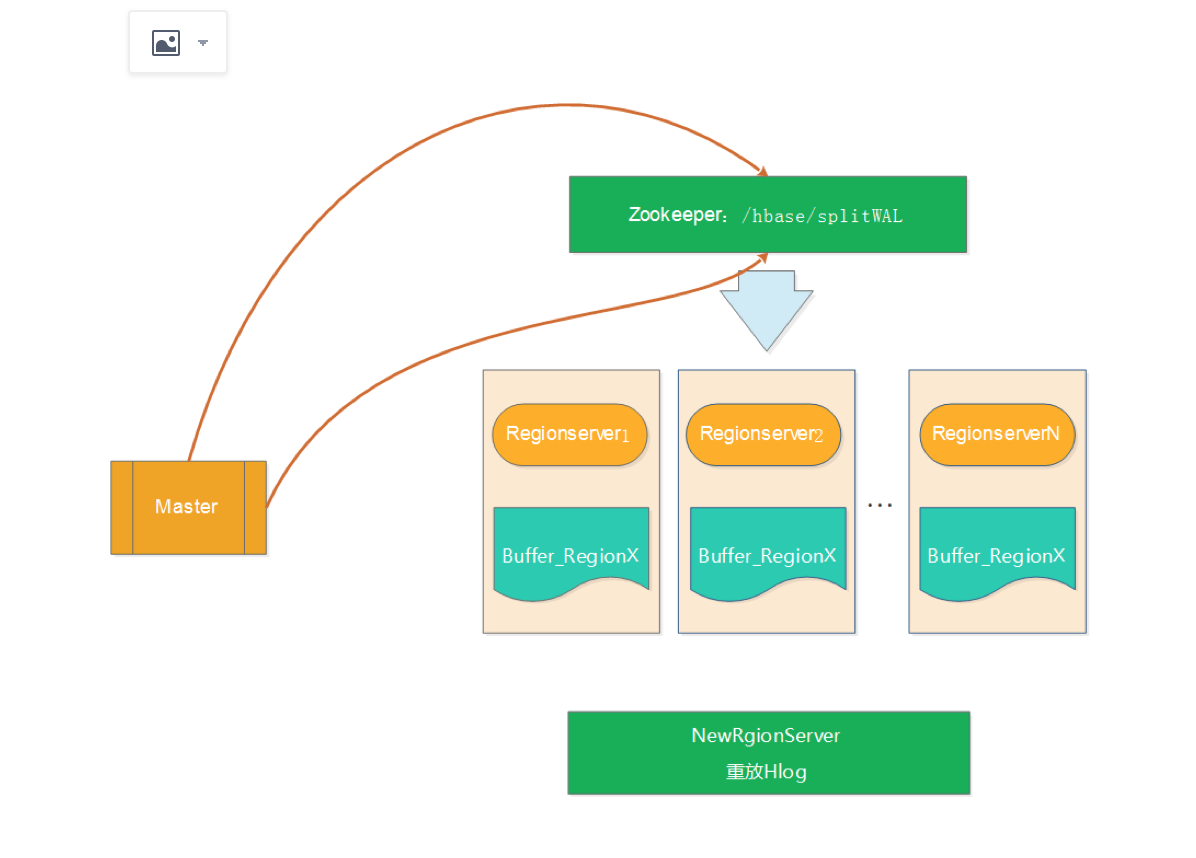
a、Master将要切分的日志发布到Zookeeper节点上(/hbase/splitWAL),每个Hlog日志一个任务,任务的初始状态为TASK_UNASSIGNED
b、在Master发布Hlog任务后,RegionServer会采用竞争方式认领对应的任务(先查看任务的状态,如果是TASK_UNASSIGNED,就将该任务状态修改为TASK_OWNED)
c、RegionServer取得任务后会让对应的HLogSplitter线程处理Hlog的切分,切分的时候读取出Hlog的对,然后写入不同的Region buffer的内存中。
d、RegionServer启动对应写线程,将Region buffer的数据写入到HDFS中,路径为/hbase/table/region/seqenceid.temp,seqenceid是一个日志中该Region对应的最大sequenceid,如果日志切分成功,而RegionServer会将对应的ZK节点的任务修改为TASK_DONE,如果切分失败,则会将任务修改为TASK_ERR。
e、如果任务是TASK_ERR状态,则Master会重新发布该任务,继续由RegionServer竞争任务,并做切分处理。
f、Master重新将宕机的RegionServer中的Rgion分配到正常的RegionServer中,对应的RegionServer读取Region的数据,将该region目录下的一系列的seqenceid.temp进行从小到大进行重放,从而实现对应Region数据的恢复。
从上面的步骤中,我们可以看出Distributed Log Splitting采用分布式的方式,使用多台RegionServer做Hlog的切分工作,确实能提高效率。正常故障恢复可以降低到分钟级别。但是这种方式有个弊端是会产生很多小文件(切分的Hlog数 宕机的RegionServer上的Region数)。比如一个RegionServer有20个Region,有50个Hlog,那么产生的小文件数量为20*50=1000个。如果集群中有多台RegionServer宕机的情况,小文件更是会成倍增加,恢复的过程还是会比较慢。由次诞生了Distributed Log Replay模式。
Distributed Log Replay
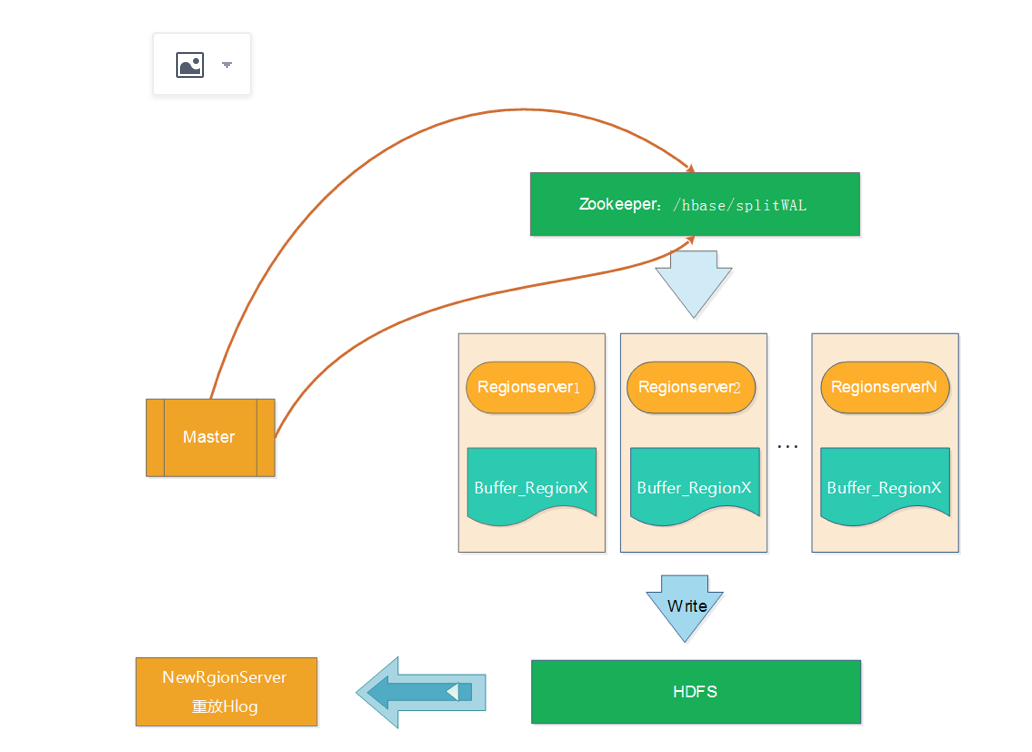
Distributed Log Replay和Distributed Log Splitting的不同是先将宕机RegionServer上的Region分配给正常的RgionServer,并将该Region标记为recovering。再使用Distributed Log Splitting类似的方式进行Hlog切分,不同的是,RegionServer将Hlog切分到对应Region buffer后,并不写HDFS,而是直接进行重放。这样可以减少将大量的文件写入HDFS中,大大减少了HDFS的IO消耗。如下图所示: