写入逻辑
HBase仅仅支持行级别的事务一致性。本文主要探讨一下HBase的写请求流程。主要基于0.98.8版本号的实现
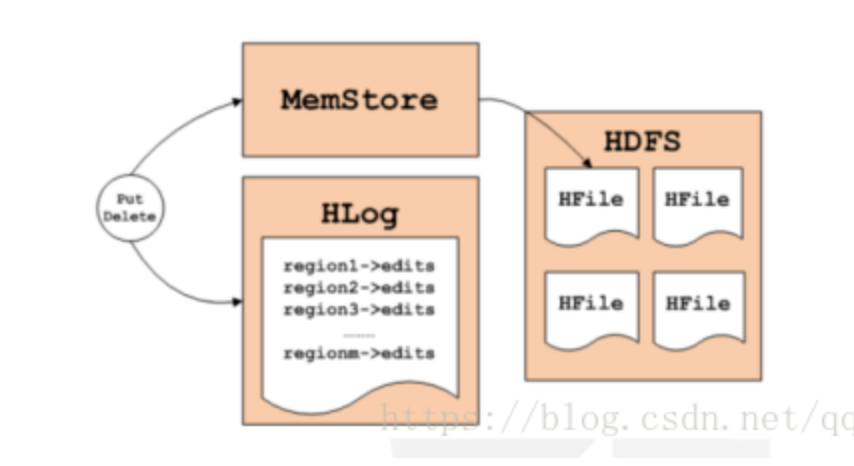
Hbase的写逻辑涉及到写内存、写log、刷盘等操作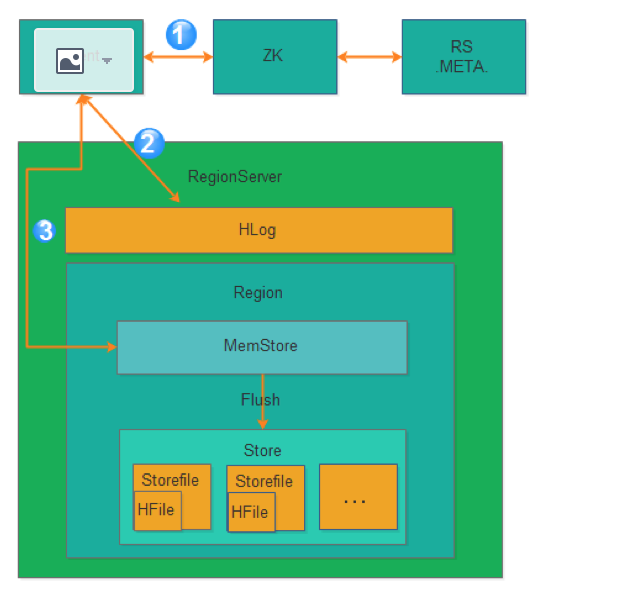
从上图可以看出氛围3步骤:
第1步:Client获取数据写入的Region所在的RegionServer
第2步:请求写Hlog
第3步:请求写MemStore
只有当写Hlog和写MemStore都成功了才算请求写入完成。MemStore后续会逐渐刷到HDFS中。
备注:Hlog存储在HDFS,当RegionServer出现异常,需要使用Hlog来恢复数据。
client写请求
HBase提供的Java client API是以HTable为主要接口,相应当中的HBase表。
写请求API主要为HTable.put(write和update)、HTable.delete等。
以HTable.put为样例,首先来看看客户端是怎么把请求发送到HRegionServer的。
每一个put请求表示一个KeyValue数据,考虑到client有大量的数据须要写入到HBase表,HTable.put默认是会把每一个put请求都放到本地缓存中去,当本地缓存大小超过阀值(默觉得2MB)的时候,就要请求刷新,即把这些put请求发送到指定的HRegionServer中去,这里是利用线程池并发发送多个put请求到不同的HRegionServer。
但假设多个请求都是同一个HRegionServer,甚至是同一个HRegion,则可能造成对服务端造成压力,为了避免发生这样的情况,clientAPI会对写请求做了并发数限制,主要是针对put请求须要发送到的HRegionServer和HRegion来进行限制。详细实如今AsyncProcess中。
主要參数设定为:1
2
3hbase.client.max.total.tasks 客户端最大并发写请求数。默觉得100
hbase.client.max.perserver.tasks 客户端每一个HRegionServer的最大并发写请求数。默觉得2
hbase.client.max.perregion.tasks 客户端每一个HRegion最大并发写请求数。默觉得1
为了提高I/O效率。AsyncProcess会合并同一个HRegion相应的put请求,然后再一次把这些同样HRegion的put请求发送到指定HRegionServer上去。另外AsyncProcess也提供了各种同步的方法,如waitUntilDone等,方便某些场景下必须对请求进行同步处理。每一个put和读请求一样。都是要通过訪问hbase:meta表来查找指定的HRegionServer和HRegion,这个流程和读请求一致。
服务端写请求
当client把写请求发送到服务端时。服务端就要開始运行写请求操作。HRegionServer把写请求转发到指定的HRegion运行,HRegion每次操作都是以批量写请求为单位进行处理的。主要流程实如今HRegion.doMiniBatchMutation,大致例如以下:
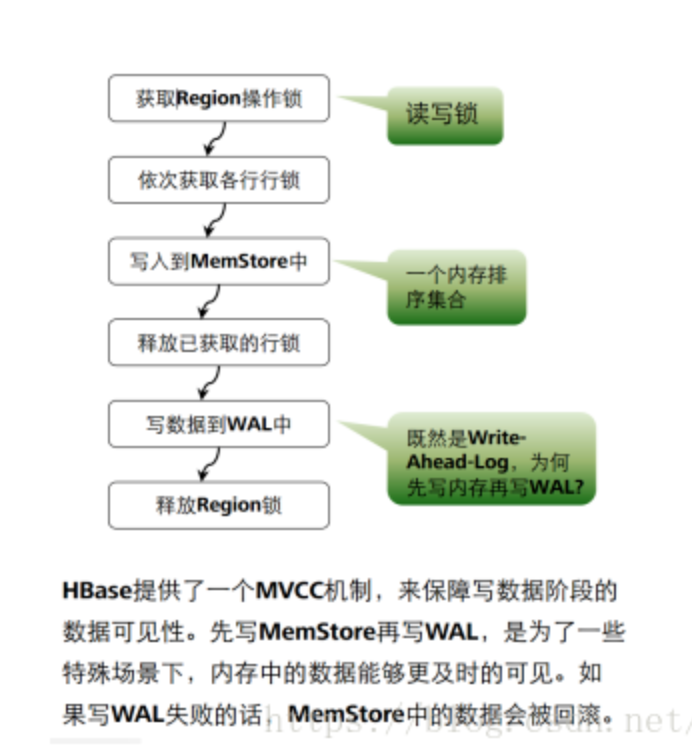
应用了zookeeper的分布式事务锁的方式:
1.获取region锁 有了这个锁的region,想要获取这个有锁的region的进程必须等待
2.依次获取各行的锁:拿到每一行的锁
3.先将拿到锁的一行数据,写入到memstore中,
4.释放写入完毕的这一行数据的行锁
5.写数据到wal中
6.Memstore和wal都写入以后,释放region锁
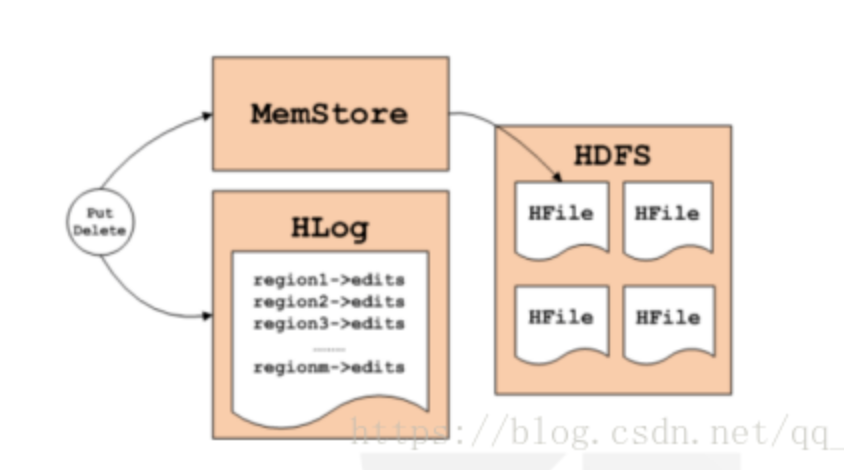
为什么数据通过wal已经写入到hdfs中了,还要通过memstore再将数据往 内存中写一次呢?
答:是为了数据的写入和读取,还有就是wal主要是为了回滚。
为什么会有回滚操作机制?
有可能写入到内存成功,但是没有成功的写入到hdfs中,比如hdfs的主机挂掉了,没有写入成功,就不能正常的释放锁,因此就会产生异常,然后启动回滚的操作,将内存的数据也删除
回滚就会可能出现脏读的情况:刷新的速度比释放锁的速度块 ,刷新了就把内存中的数据,立马写入到hdfs中 这个可能大概是千万毫秒分子1
先写memstore再写wal的优缺点?
优点:这条数据没有写入到hdfs中,用户就可以访问了====habse速度快的原因
缺点:脏读
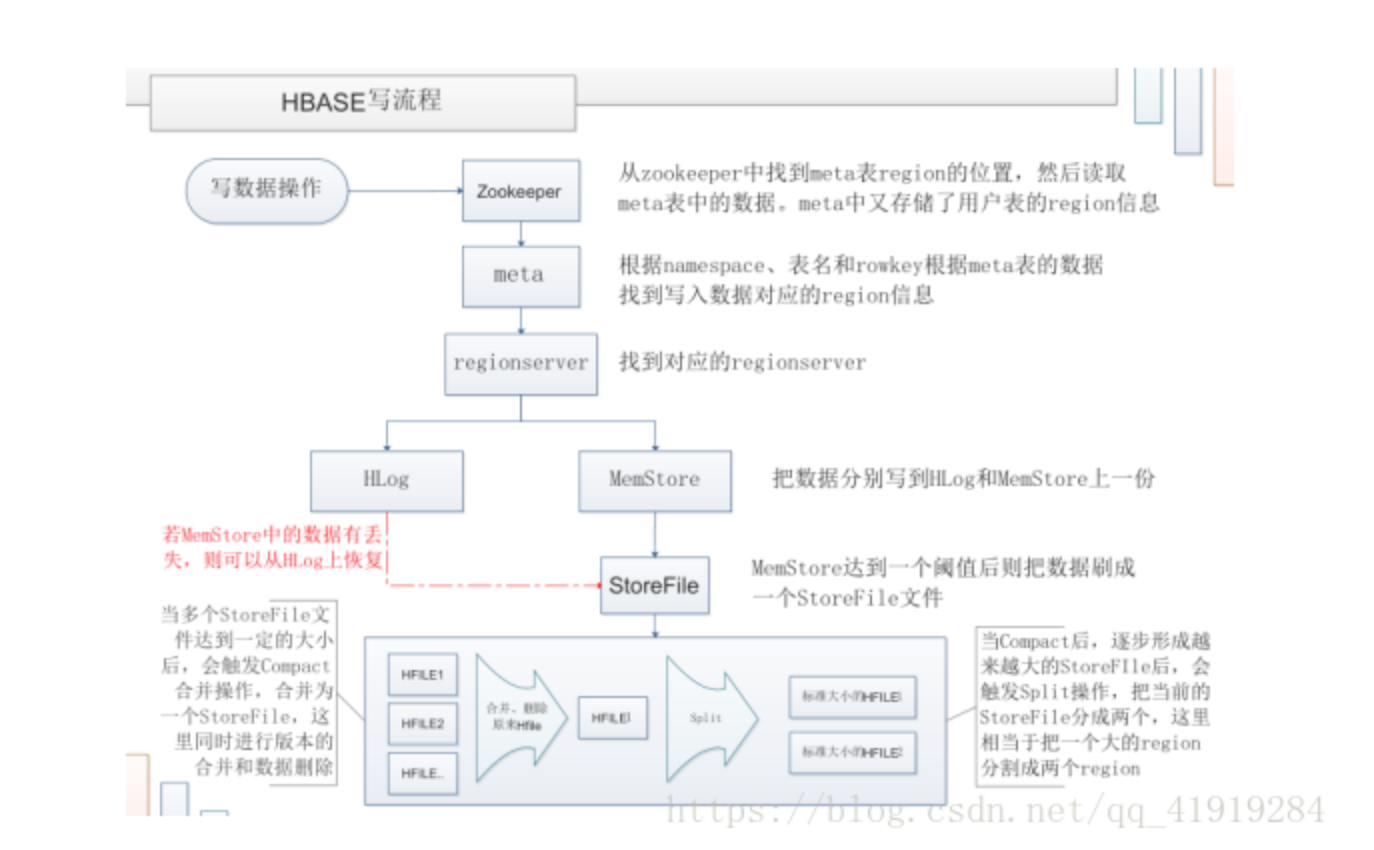
Hbase的不同版本,menstore和wal写入的顺序是有差异的
1.0以前的老版本:先写wal,写完了以后再写memstore
新版本:memstore和wal是并行同时写数据,但是由于memstore’是将数据写入内存中,而wal是将数据写入hdfs中,因此memstore写数据的速度要块,因此memstore先于wal结束,释放行锁
先写memstore再写wal的优缺点?
优点:这条数据没有写入到hdfs中,用户就可以访问了====habse速度快的原因
缺点:脏读
为什么会有回滚操作机制?
有可能写入到内存成功,但是没有成功的写入到hdfs中,比如hdfs的主机挂掉了,没有写入成功,就不能正常的释放锁,因此就会产生异常,然后启动回滚的操作,将内存的数据也删除
回滚就会可能出现脏读的情况:刷新的速度比释放锁的速度块 ,刷新了就把内存中的数据,立马写入到hdfs中 这个可能大概是千万毫秒分子1
MemStore刷盘
为了提高Hbase的写入性能,当写请求写入MemStore后,不会立即刷盘生成storefile。而是会等到一定的时候进行刷盘的操作。具体是哪些场景会触发刷盘的操作呢?总结成如下的几个场景:
全局内存控制
这个全局的参数是控制内存整体的使用情况,当所有memstore占整个heap的最大比例的时候,会触发刷盘的操作。这个参数是hbase.regionserver.global.memstore.upperLimit,默认为整个heap内存的40%。但这并不意味着全局内存触发的刷盘操作会将所有的MemStore都进行输盘,而是通过另外一个参数hbase.regionserver.global.memstore.lowerLimit来控制,默认是整个heap内存的35%。当flush到所有memstore占整个heap内存的比率为35%的时候,就停止刷盘。这么做主要是为了减少刷盘对业务带来的影响,实现平滑系统负载的目的。
MemStore达到上限
当MemStore的大小达到hbase.hregion.memstore.flush.size大小的时候会触发刷盘,默认128M大小
RegionServer的Hlog数量达到上限
前面说到Hlog为了保证Hbase数据的一致性,那么如果Hlog太多的话,会导致故障恢复的时间太长,因此Hbase会对Hlog的最大个数做限制。当达到Hlog的最大个数的时候,会强制刷盘。这个参数是hase.regionserver.max.logs,默认是32个。
手工触发
可以通过hbase shell或者java api手工触发flush的操作。
关闭RegionServer触发
在正常关闭RegionServer会触发刷盘的操作,全部数据刷盘后就不需要再使用Hlog恢复数据。
Region使用HLOG恢复完数据后触发
当RegionServer出现故障的时候,其上面的Region会迁移到其他正常的RegionServer上,在恢复完Region的数据后,会触发刷盘,当刷盘完成后才会提供给业务访问。
每一次Memstore的flush,会为每一个CF创建一个新的storeFile。。 在读方面相对来说就会简单一些:HBase首先检查请求的数据是否在Memstore,不在的话就到HFile中查找,最终返回merged的一个结果给用户。
每次Memstore Flush,会为每个CF都创建一个新的HFile(storeFile)。这样,不同CF中数据量的不均衡将会导致产生过多HFile:当其中一个CF的Memstore达到阈值flush时,所有其他CF的也会被flush。如上所述,太频繁的flush以及过多的HFile将会影响集群性能。
Compaction
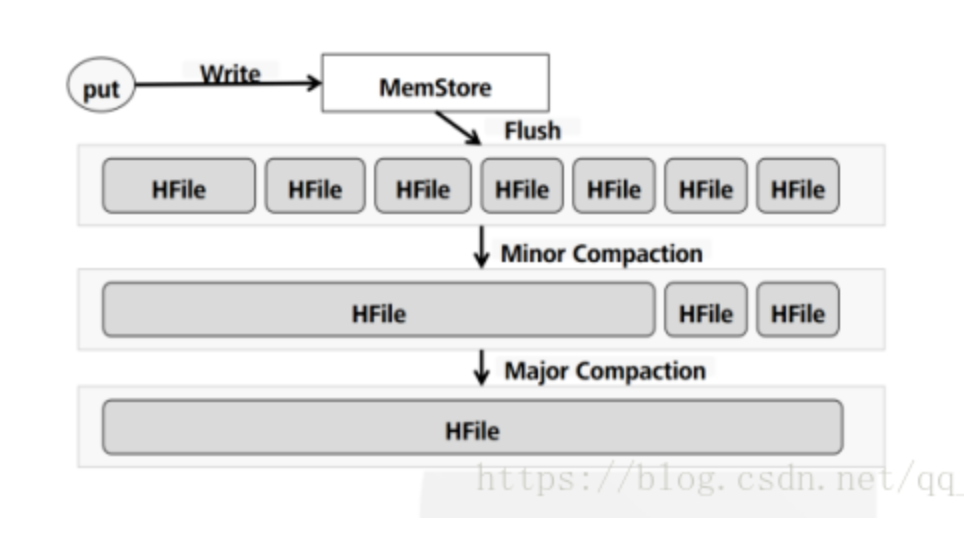
MemStore频繁的Flush就会创建大量的storeFile(Hfile)。这样HBase在检索的时候,就不得不读取大量的storeFile,读性能会受很大影响。
为预防打开过多HFile及避免读性能恶化,HBase有专门的HFile合并处理(HFile Compaction Process)。HBase会周期性的合并数个小HFile为一个大的HFile。明显的,有Memstore Flush产生的HFile越多,集群系统就要做更多的合并操作(额外负载)。更糟糕的是:Compaction处理是跟集群上的其他请求并行进行的。当HBase不能够跟上Compaction的时候(同样有阈值设置项),会在RS上出现“写阻塞”。像上面说到的,这是最最不希望的。
提示:严重关切RS上Compaction Queue 的size。要在其引起问题前,阻止其持续增大。
Compaction的主要目的,是为了减少同一个Region同一个ColumnFamily下面的小文件数目,从而提升读取的性能。
小合并(MinorCompaction)
由前面的刷盘部分的介绍,我们知道MemStore会将数据刷到磁盘,生产StoreFile,因此势必产生很多的小问题,对于Hbase的读取,如果要扫描大量的小文件,会导致性能很差,因此需要将这些小文件合并成大一点的文件。因此所谓的小合并,就是把多个小的StoreFile组合在一起,形成一个较大的StoreFile,通常是累积到3个Store File后执行。通过参数hbase.hstore,compactionThreadhold配置。小合并的大致步骤为:
- 分别读取出待合并的StoreFile文件的KeyValues,并顺序地写入到位于./tmp目录下的临时文件中
- 将临时文件移动到对应的Region目录中
- 将合并的输入文件路径和输出路径封装成KeyValues写入WAL日志,并打上compaction标记,最后强制自行sync
- 将对应region数据目录下的合并的输入文件全部删除,合并完成
这种小合并一般速度很快,对业务的影响也比较小。本质上,小合并就是使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟。
小范围的Compaction。有最少和最大文件数目限制。通常会选择一些连续时间范围的小文件进行合并====小合并,Minor Compaction选取文件时,遵循一定的算法。
大合并(MajorCompaction)
所谓的大合并,就是将一个Region下的所有StoreFile合并成一个StoreFile文件,在大合并的过程中,之前删除的行和过期的版本都会被删除,拆分的母Region的数据也会迁移到拆分后的子Region上。大合并一般一周做一次,控制参数为hbase.hregion.majorcompaction。大合并的影响一般比较大,尽量避免统一时间多个Region进行合并,因此Hbase通过一些参数来进行控制,用于防止多个Region同时进行大合并。该参数为: hbase.hregion.majorcompaction.jitter
具体算法为:1
2
3hbase.hregion.majorcompaction参数的值乘于一个随机分数,这个随机分数不能超过hbase.hregion.majorcompaction.jitter的值。hbase.hregion.majorcompaction.jitter的值默认为0.5。
通过hbase.hregion.majorcompaction参数的值加上或减去hbase.hregion.majorcompaction参数的值乘于一个随机分数的值就确定下一次大合并的时间区间。
用户如果想禁用major compaction,只需要将参数hbase.hregion.majorcompaction设为0。建议禁用。
涉及该Region该ColumnFamily下面的所有的HFile文件。删除的数据。===大合并
需要删除的数据包含哪些数据?
1.ttl 带有有效期的数据,有效期过来之后,不能被访问,但是仍然存在
2.Put数据:时间戳版本数据数量大于vsrsion可存在的数量
3.需要删除的数据,将数据标记为删除
区别
Major和minor合并的区别有哪些?
1.合并范围不同
小范围:在一定时间内,将多个小文件合并在一起,合并的是一部分发 hfile
大范围:将所有的hfile合并
2.功能不同
小范围:只进行整理
大范围:删除只会在大合并的时候执行操作,
一般情况下,不会做大合并!

1
2Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上,但并不是存储的最小单元。
Region由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile 组成。memStore存储在内存中, StoreFile存储在HDFS上。
防止误区:开启大合并,整个hbase的所有的hfile要合并,但是并不是所有的hfile合并成一个hfile,而是一个列族(store)当中的所有的storefile合并成一个storefile,所有的列族开始合并操作,major合并之后,一个store只有一个storeFile文件,会对store的所有数据进行重写,有较大的性能消耗
很少做大合并,为什么?
工程量过大
如果一定要大合并呢?
对于某一张表的某些列族,手动执行大合并,不建议开启大合并!!!
为什么不建议开启大合并?
因为在执行大合并的时候,整个hbase的hfile都在参与合并,整个hbase会锁住,此时读数据和写数据都不行
为什么可以做到不执行大合并操作来达到增加空间呢?
因为hbase的底层是hdfs,如果空间不够,可以任意的增加硬盘,增加服务器
参考:
https://www.cnblogs.com/liguangsunls/p/6792705.html
https://blog.csdn.net/qq_41919284/article/details/81676636
https://blog.csdn.net/xiao_jun_0820/article/details/26580247