本文主要是基于HBase的0.98.8版本的实现。
HBase能提供实时计算服务主要原因是由其架构和底层的数据结构决定的,即由LSM-Tree(Log-Structured Merge-Tree) + HTable(region分区) + Cache决定——客户端可以直接定位到要查数据所在的HRegion server服务器,然后直接在服务器的一个region上查找要匹配的数据,并且这些数据部分是经过cache缓存的。
客户端读请求
HBase为客户端提供了的读请求API主要有两个,get和scan。其中,get是通过指定单个的rowKey,获取其对应的value值。而scan是指定startRow和stopRow两个边界rowKey来指定范围rowKey值,获取它们对应的value值。
首先我们知道HBase会根据算法把一个表划分为多个Region,然后HMaster会把这几个Region分配到不同的节点中去,因此,当我们查找一个表的数据时,有可能要把请求发送到不同的节点,再获取其查询结果。但是要如何根据get指定的rowKey到指定的节点上查询呢(scan的流程相差不大)?HBase依靠hbase:meta这个系统表实现,事实上hbase:meta表和普通的HBase表一样,都是要分配到某个节点上,如果这个节点出现故障就会转移到另外可用的节点上,这样就可以防止某个节点出现故障导致整个HBase服务不可用。
HBase要求客户端的读请求需要自行定位到所属的Region的节点上,然后把请求的rowKey以及Region一并发送到这个节点。
我们来看看客户端的读请求执行过程:
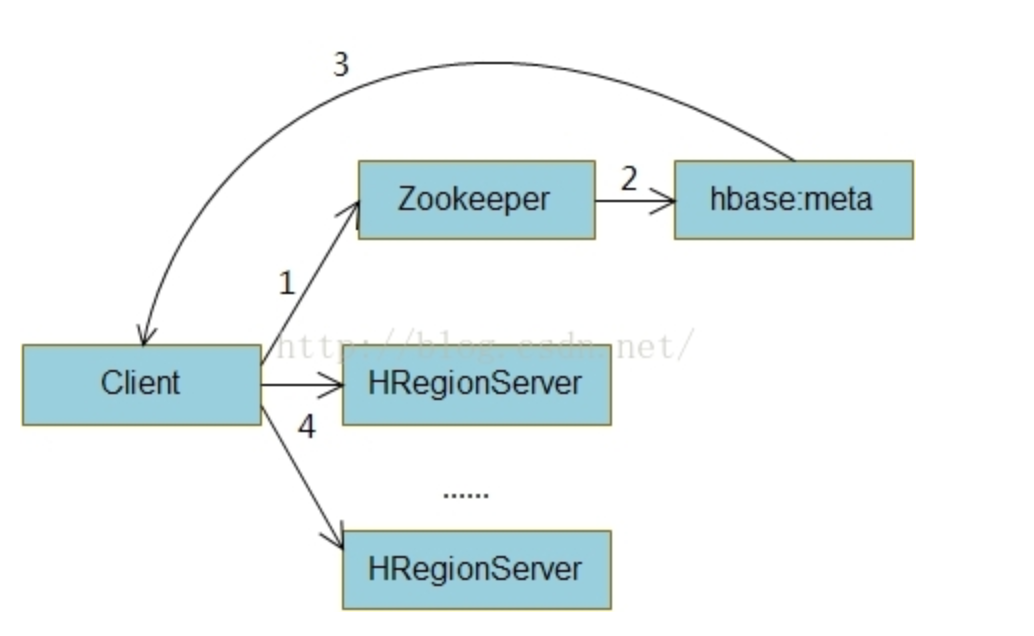
get
由于hbase:meta表在存放在某台可用的节点机器上,因此我们需要定位究竟是哪台节点。这个过程步骤如下:
HBase使用zookeeper来存放hbase:meta表的位置,这样客户端就需要先到zookeeper查询hbase:meta表在哪个节点上,如图中的1。
然后在根据读请求的rowKey发送请求到这个节点上,节点根据hbase:meta表查找到rowKey所属Region的节点,然后返回给客户端,即图中的2,3。
客户端再真正把读请求发送到指定的HRegionServer上,如图中的4,然后HRegionServer再执行具体读请求的查询操作,最后把结果返回到客户端上
要注意的是,客户端会缓存每次hbase:meta表返回的结果缓存到本地上,这样就可以防止每次查询都要经过步骤1,2进行查询,导致过多的网络I/O操作。在上面的第2个过程中,节点是如何根据rowKey通过查询hbase:meta表得到所属的Region呢?hbase:meta表中保存了每个Region的startRow,这样可以查找小于rowKey里的最大startRow值即可确定Region,这个过程在HRegion.getClosestRowBefore()代码实现。
scan
对于scan来说,其实流程和get的查询相差不大,由于scan请求包含startRow和stopRow两个范围,因此可能需要查询多个Region。具体步骤如下:
会先发送startRow作为指定rowKey到hbase:meta表上请求Region信息,返回的Region信息会包含这个Region的startKey和endKey
然后客户端再根据Regioin的范围判断。即如果stopRow<=endKey,则只需要查询这个Region即可。
否则,需要首先把startRow和endKey作为一次的请求发送到这个Region的节点上,然后再把endKey作为新的startRow去查询hbase:meta,然后重复步骤1
这样经过多次的迭代,即可把scan请求对应为多个Region的查询。
服务端读请求
当客户端把读请求发送到对应的HRegionServer上时,服务端就会开始具体的查询了。实际上,客户端发送的读请求会包含Region信息,以及rowKey范围(如果是get,则只有一个rowKey),另外还有客户端指定的其它查询参数,包括columnFamily,timestamp,filter过滤器等。因此HRegionServer首先会简单地找出对应的HRegion对象来执行具体的读请求。另外,无论是get或者scan请求,HRegionServer都会转化成scan请求来对待,其实get请求就是一个特殊的scan请求,它的范围只有一个指定的rowKey。
对于HRegion是如何执行读请求的查询,首先要对HRegionServer内部有一个了解。
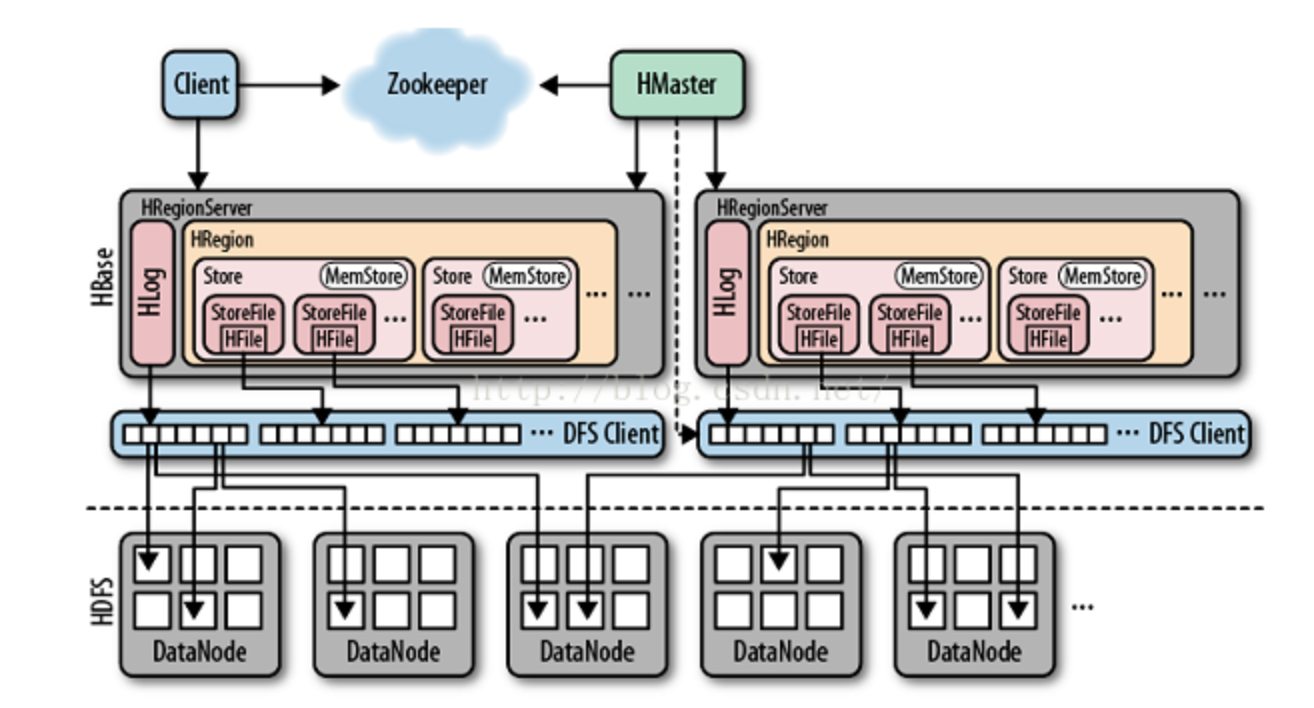
集中关注一下HRegionServer的内部结构。HRegion是HBase表经过Sharding后的一部分,每个HRegion里面可能有多个Store,每个Store就是一个Column Family的对象,同一Column Family允许有多个列,这些列的数据都必须存储到一个文件里(但有可能存在多个这样的文件),存储格式为HFile,因此每个Store都有多个StoreFile对象管理Column Family的列数据。另外注意到每个Store内部都有一个MemStore对象。MemStore是HBase用来缓存写请求数据的内存结构,由于HBase的写请求都会写MemStore,然后再写HLog(HBase的WriteAheadLog的实现,存储在HDFS里),这样写请求才算提交状态,才对读请求为可见。MemStore可以让我们从内存中读取最近写请求提交的数据,而不必从HLog中读取,因此避免了I/O操作。另外,图里没有画出的是BlockCache,这个是HRegionServer内部的单例,主要用于HFile读取时缓存HBlock,后面将会继续详述。
弄清楚HRegion的结构之后,可以知道,在某个存在读写请求的时刻里,HRegion包含表数据的地方有MemStore、HLog、HFile、BlockCache。由于MemStore的数据与HLog是等同的,因此对于每个读请求,HRegion需要查询MemStore、BlockCache和HFile这三个部分。
KeyValue
还有一个要注意的是,HBase对于数据KeyValue的定义,来看看下图KeyValue的二进制格式:

一个KeyValue只包含一个rowKey和一个对应的Value值,也就是说,如果一个rowKey在有多个列值,则会有多个KeyValue与其对应。上图的绿色部分中,第二个空格Row就是用于定义的rowKey,在HBase的内部里,对于整个KeyValue来说,包含Column Family、Column Qualifier、TimeStamp和KeyType的整个绿色Key部分才是KeyValue的key值。黄色的Value部分就是保存的列值。在查询流程里,可能会出现对比用于定义的rowKey,或者对比整个绿色部分的key值。
查询流程
为了提高查询速度,MemStore和HFile内部都是经过排序的数据,因此,在实际查询的过程中可以使用多路归并的方法进行查询。整个查询过程如下图所示:
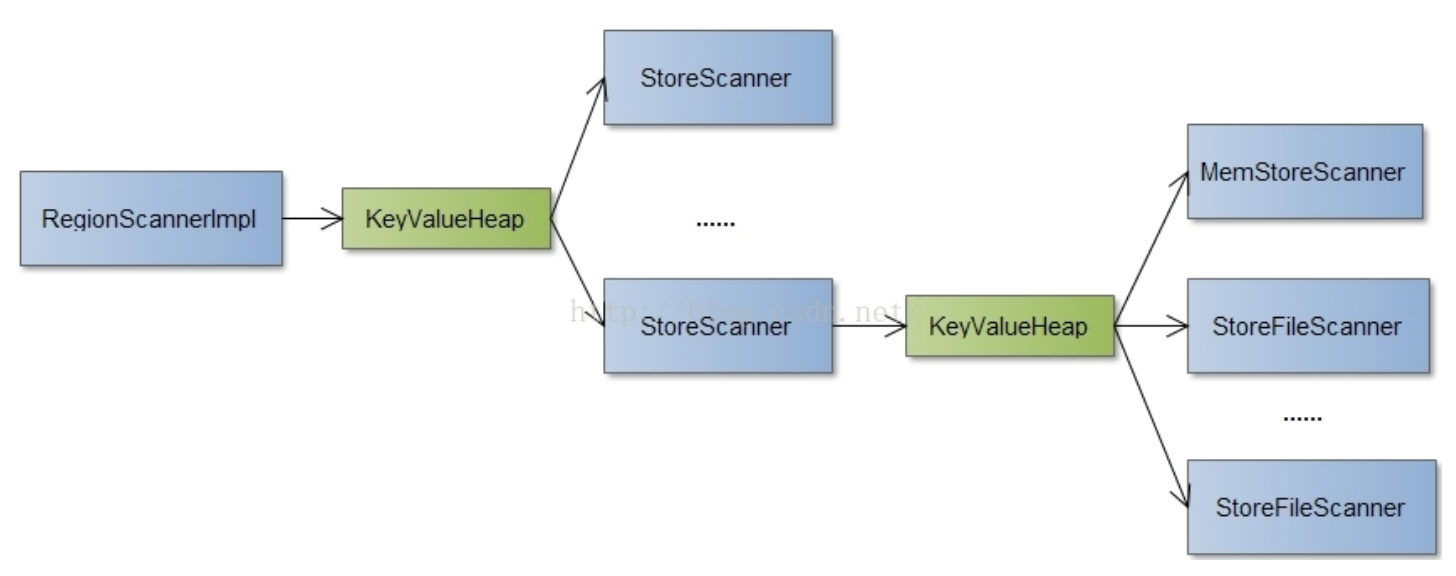
HRegion提供了Scanner接口方便解耦HRegion与MemStore、BlockCache和HFile这三个部分的查询过程。其中RegionScannerImpl负责HRegion内部查询的过程,StoreScanner则是负责HStore内部查询的过程,由于可能有多个HStore,则会有对应多个StoreScanner,MemStoreScanner则负责HStore内部的MemStore数据结构查询,StoreFileScanner则负责HStore内部多个HFile的查询。这几个部分分别用KeyValueHeap连接起来,KeyValueHeap实现了多路归并的查询逻辑。
多路归并的逻辑大致如下:首先初始化各个Scanner,这个过程需要Scanner根据要查询的KeyValue数据kv,进行一次seek查询,seek查询的结果是一个大于或等于查询值kv的peek值,然后KeyValueHeap使用优先级队列PriorityQueue保存各个Scanner,这个优先级队列会通过比较各个Scanner的peek值来进行排序,这个优先级队列的第一个元素就是这些scanner里查询kv的结果,如果这个值刚好等于kv,即成功找到,如果大于则表明不存在。如果需要查询多个值则重新进行一次seek查询,再获取优先级队列的第一个元素。可以类别优先级队列里的scanner就是多路归并的各个有序队列,这样就很容易理解算法。
另外,在StoreScanner的初始化过程中,为了减少进行多路归并的Scanner数,提高查询速度,会对Scanner进行一次简单的过滤。MemStoreScanner,会根据查询kv值的时间戳判断是否在TimeRange,以及TTL来判断。而StoreFileScanner则会利用TimeRange(包括TTL)、KeyRange、BloomFilter判断kv值是否在HFile中。BloomFilter特性通过计算kv的哈希值来快速判断是否存在,但有一定的失败几率。
从KeyValueHeap的多路归并算法逻辑可以看到,Scanner关键是如何通过seek查询更新对应的peek值。接下来主要分析一下MemStoreScanner和StoreFileScanner是如何通过seek查询来更新peek值的。
MemStoreScanner
MemStoreScanner直接引用MemStore内部的两个主要的数据结构:kvset和snapshot。这两个数据结构都是保存KeyValue数据的KeyValueSkipListSet。KeyValueSkipListSet是HBase单独实现的一个专门保存KeyValue的SkipList,内部用ConcurrentNavigableMap封装实现了高效并发的有序队列。kvset是当HBase写入数据KeyValue的缓存,而snapshot则是指快照,这是MemStore大小超过阀值,需要把kvset数据写入HFile的时候生成的副本,这样当flush这份副本到HFile里的时候,减少对写请求的影响。
MemStoreScanner的seek过程比较简单,代码流程如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27public synchronized KeyValue peek() {
//DebugPrint.println(" MS@" + hashCode() + " peek = " + getLowest());
return theNext;
}
public synchronized boolean seek(KeyValue key) {
if (key == null) {
close();
return false;
}
//tailSet返回的是大于等于key的集合
kvsetIt = kvsetAtCreation.tailSet(key).iterator();
snapshotIt = snapshotAtCreation.tailSet(key).iterator();
kvsetItRow = null;
snapshotItRow = null;
return seekInSubLists(key);
}
private synchronized boolean seekInSubLists(KeyValue key){
//getNext从迭代器获取符合的KeyValue值
kvsetNextRow = getNext(kvsetIt);
snapshotNextRow = getNext(snapshotIt);
// Calculate the next value
theNext = getLowest(kvsetNextRow, snapshotNextRow);
// has data
return (theNext != null);
}
上面代码主要实现逻辑比较简单,kvsetAtCreation和snapshotAtCreation两个数据结构(引用MemStore的kvset和snapshot),通过比较KeyValue的绿色key部分,来查找大于等于的集合,然后getNext需要通过比较MVCC版本号以及rowKey部分找出集合里符合KeyValue的值,最后再从两个集合里面找出最小的那个KeyValue,同样也是类似多路合并的思想,这样的结果就是theNext的值,也就是peek返回的值。
这里的MVCC版本号是HBase提高读写并发事务,并维持一致性的实现。
StoreFileScanner
StoreFileScanner由于涉及到BlockCache缓存,HFile读写,Bloom filter等特性,逻辑实现较为复杂。StoreFileScanner会首先利用HFile记录的时间戳范围、rowKey范围、Bloom filter来判断给定的KeyValue是否存在HFile中,如果不存在则直接跳过HFile的查找。然后会StoreFileScanner的seek操作就要涉及到HFile的查找过程。HFile采用HBlock作为文件操作的基本单位,有不同类型的HBlock,包括DataBlock(保存KeyValue),IndexBlock(保存索引以及对应的rowKey)、BloomMeta(Bloom filter相关)等。HFile采用类似B+树的多级索引算法,优化在数据量大的情况下查找一个指定的KeyValue的速度。在多级索引查找过程中,读取HBlock都会尝试从BlockCache缓存读取指定Block,尽量避免I/O操作;由于所有的Block的rowKey都是有序的,IndexBlock都是采用二分查找算法来得到下一个Block的offset,有助于提高查找速度。接下来是较为详细的实现解析。
HFile
HBase的HFile目前有三个不同的版本,本文主要研究HFile v2的布局。首先来看看它的文件布局格式:
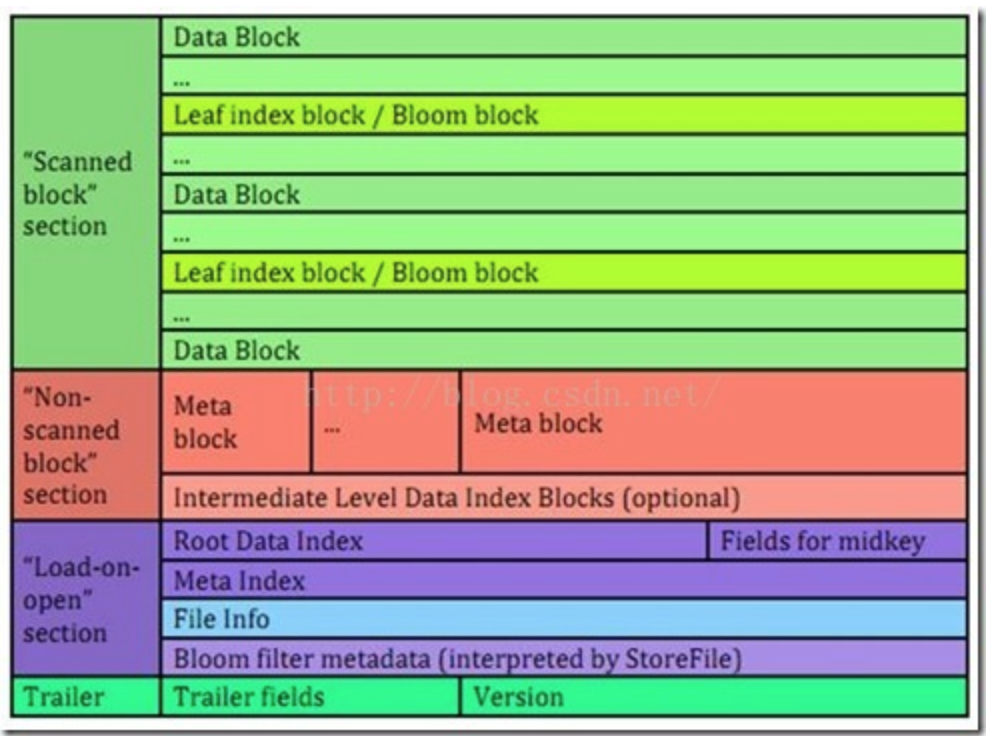
HFile V2有四部分:”Scanned block”、”Non-scanned block”、”Load-on-open”和Trailer部分(详细请参考这里)。HFile的初始化记载过程中,默认把Trailer和”Load-on-open”部分加载到内存中。首先会加载位于文件末尾的Trailer,包含着HFile的版本、索引数、压缩/非压缩大小、”Load-on-open”部分的偏移等文件信息。从Trailer获得”Load-on-open”部分的偏移开始加载”Load-on-open”部分,这部分主要包括RootDataIndex、midkey、MetaIndex(V2起不再存储Bloom信息,但仍支持)、FileInfo以及Bloom filter metadata。RootDataIndex就是根索引Block,midKey是用于HFile在split的时候快速找到处于中间Key的值。FileInfo包括了LastKey、平均Key长度等信息,BloomFilterMetaData就是Bloom filter的rootIndexBlock。
对于多级索引的算法,是按照数据量大小来确定究竟需要查找多少个IndexBlock的。
- 在数据量较少的情况下,可以直接从RootDataIndex直接定位DataBlock,也就是RootDataIndex->DataBlock;
- 当数据量较大时,索引的数量超过RootDataIndex的大小,因此就要建立多级索引,索引的级数与数据量大小有关,其路径为Root->Intermediate(0…N)->Leaf(0…1)->DataBlock,除了Root和DataBlock必定会有之外,Intermediate会有0到N个(取决于数据量大小),Leaf会有0到1个;
Bloom filter只采用一级索引,也就是只会有BloomFilterMetaData->BloomBlock这样的路径。
HFile保证在IndexBlock中的rowKey有序,这样在查找rowKey对应的索引中,采用的是二分查找算法,稍微有点不同的是,这里的二分查找并不是一定要找到对应的rowKey,而是要找到刚好小于等于这个rowKey的索引,这是由于这个rowKey都是IndexBlock或者DataBlock里最小值。
二分查找到最后确定DataBlock的时候,就需要顺序遍历DataBlock里的KeyValue值,由于每个DataBlock大小约为64kb(这里大约是由于DataBlock是按照KeyValue顺序写入,当超过64KB的时候才会停止写这个DataBlock,另外压缩也会有影响),因此遍历比较的时候不会有太大性能影响。
BlockCache
在以上的HFile查找过程中,需要大量I/O读取HBlock,因此HBase提供了BlockCache缓存机制,专门优化读性能。BlockCache是以HBlock为基本单位进行缓存的内存结构,经过多次的改进与性能测试,HBase官方推荐的一种做法是按照HBlock的类型进行分类缓存。事实上,由于在读请求里,对于IndexBlock的请求命中率几乎可以达到100%,而DataBlock由于业务的不确定性,可能会有巨大的命中率差距,因此把这两种类型的Block进行分类缓存,其中IndexBlock会缓存到LruBlockCache中,而DataBlock则缓存到BucketCache中。
LruBlockCache是利用LRU算法+优先级比重对HBlock进行缓存。优先级比重是HBase对HBlock进行优先级划分,分为SINGLE、MULTI、MEMORY三个等级,刚开始缓存为SINGLE等级,如果后面有读请求命中则升级到MULTI等级,MEMORY等级是用户指定HBase表设置的。进行淘汰的时候,会尽可能地按照SINGLE、MULTI、MEMORY的优先级来进行淘汰。在我们的线上集群中,几台HRegionServer的LruBlockCache命中率几乎为100%。
BucketCache同样也是利用LRU算法对HBlock进行缓存。但不同的是,由于它是针对DataBlock进行缓存,如果在随机读较多的情景下,很容易造成大量GC,这个在我们集群中曾经造成过严重的问题,因此可以把它缓存的介质指定为offheap(也支持SSD的File方式),这样可以有效减轻GC带来的影响。BucketCache还有一个优点,就是它把缓存大小分为很多个尺寸,每个尺寸都有对应一个槽,这些槽可以互相转换,这对于经过压缩的DataBlock来说能够大大提高内存利用率。
多级索引+二分查找的做法不但有助于提高读性能,允许动态读取索引Block,减轻读取HFile内存初始化时的压力。BlockCache的使用也能够尽可能地利用好内存进行缓存,避免产生I/O。另外,由于多个HFile是并行查找的,如果对多个小的HFile进行compact操作,可以避免减少多个HFile的读操作。
总结
HBase使用了多种不同的内存结构、多级索引、二分查找等各种方法提高读请求性能,另外把HFile以HBlock为基本单位进行读写,减轻I/O的同时,也能够动态按照需要进行Block读取,减轻内存压力。
参考:
https://blog.csdn.net/pun_c/article/details/46841625
https://www.cnblogs.com/ulysses-you/p/10072883.html#_label2