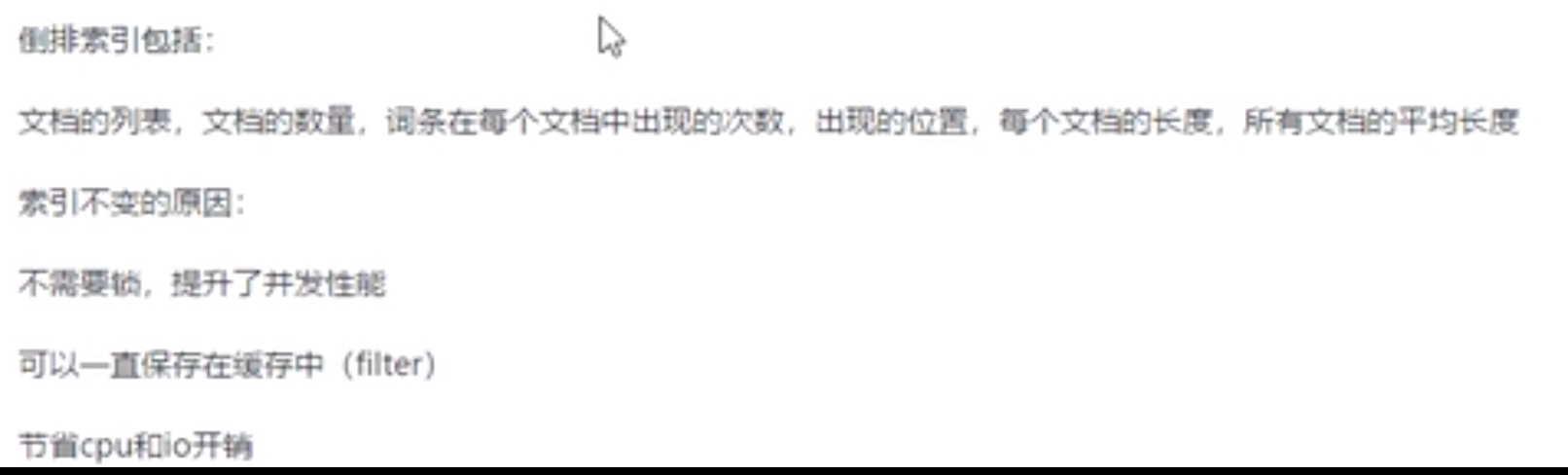
建立倒排索引
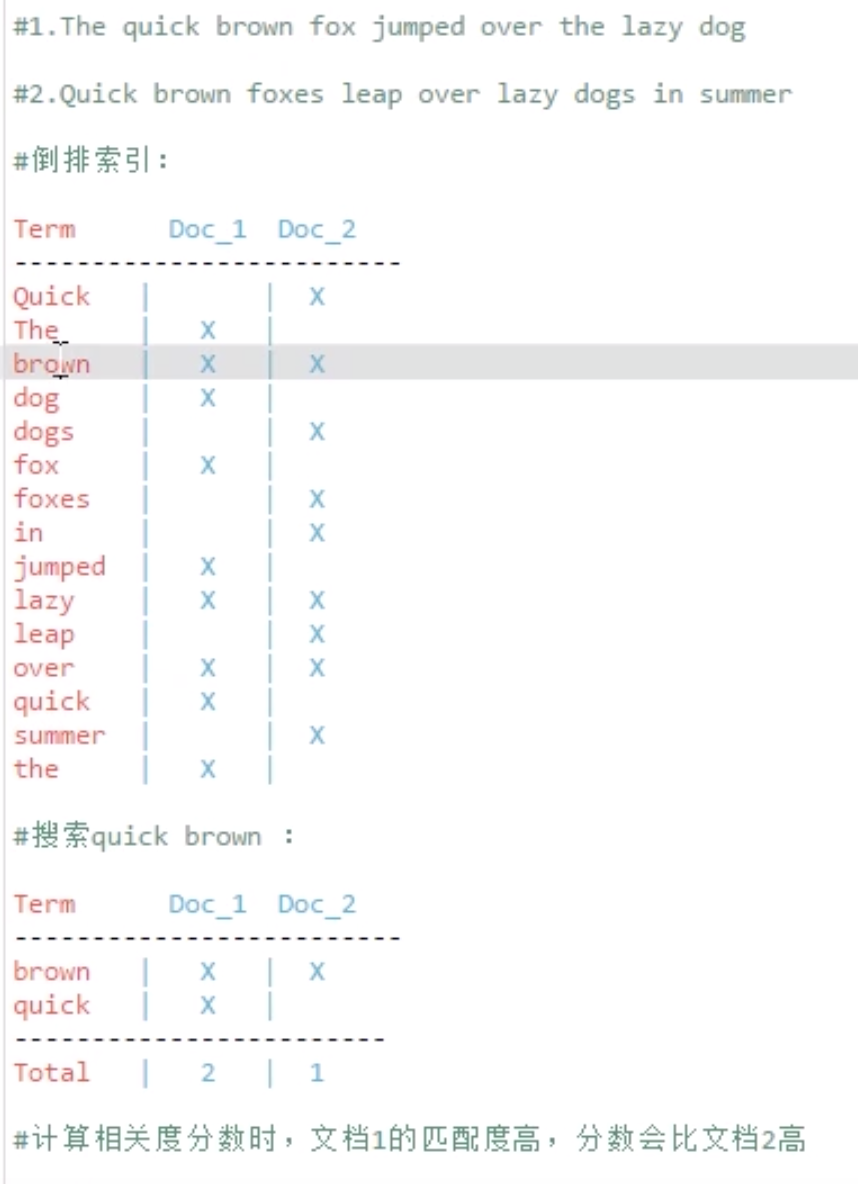

标准化规则(normalization)
并不会单纯直接建立的倒排索引,会使用到标准化规则(normalization)

dog、dogs fox foxes单复数问题只保留一个,有共同词根
Quick、quick 不区分大小写问题
jump和leap意思相近,只保留一个
分词器介绍以及内置分词器

配置中文分词器
重新启动elasticsearch在日志中可以看到。
CRUD
新建索引,默认配置 PUT lib2
查看索引 GET _all/_settings
指定文档id用put,不指定文档id用post
获取doc
GET /lib2/user/1GET /lib2/user/1?_source=age,about

修改文档
修改文档全覆盖用PUT,先把原有文档标记为deleted(es会在合适的时间把它删除掉),然后会创建一个新的文档
修改具体字段用post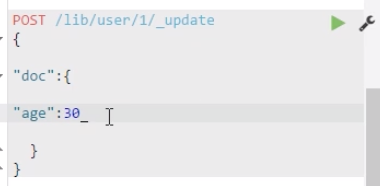
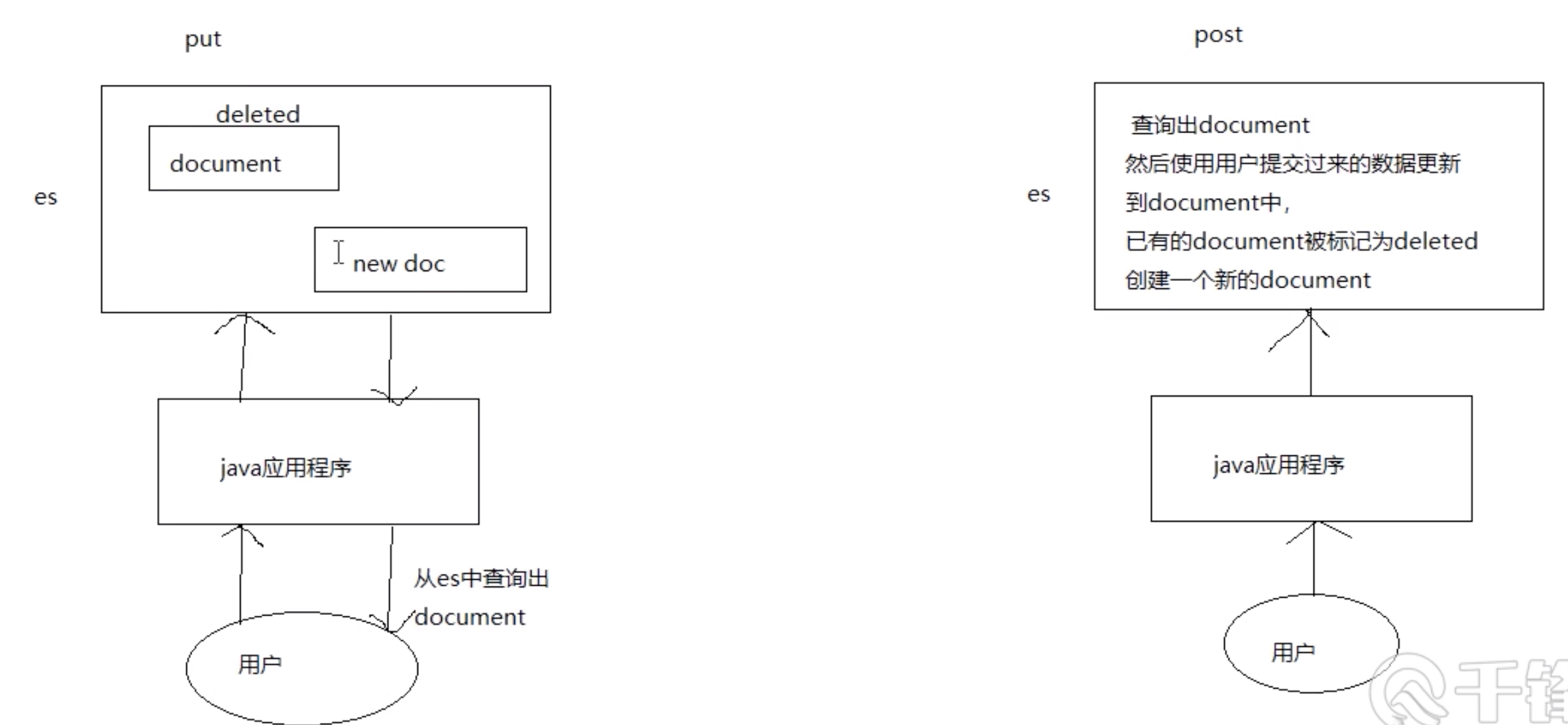
两种修改方式的区别是:

post方式对并发问题处理,可以增加一个重试参数

删除文档
DELETE /lib/user/1
DELETE /lib/user
先把文档标记为deleted,es会在合适的时间把它删除
mget,bulk




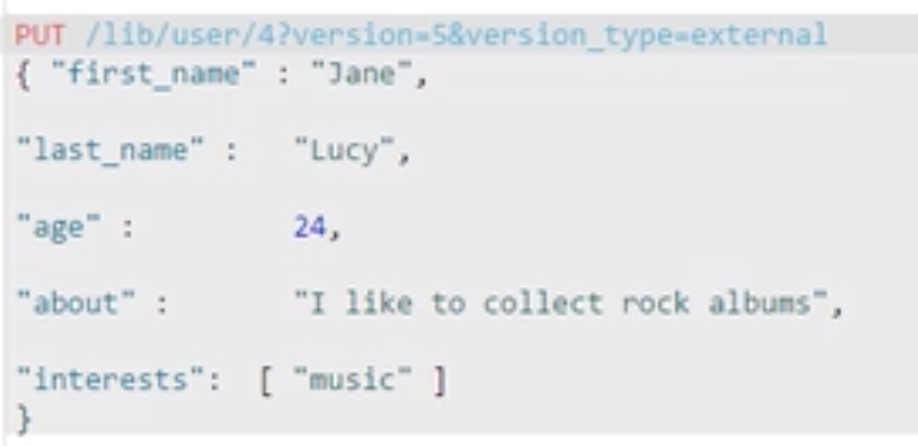
版本控制

外部的版本号需要大于内存的版本号才能成功,相等也不行
mapping
当我们添加一个文档的时候,elasticsearch就会默认给我们创建一个mapping,指定字段的数据类型。

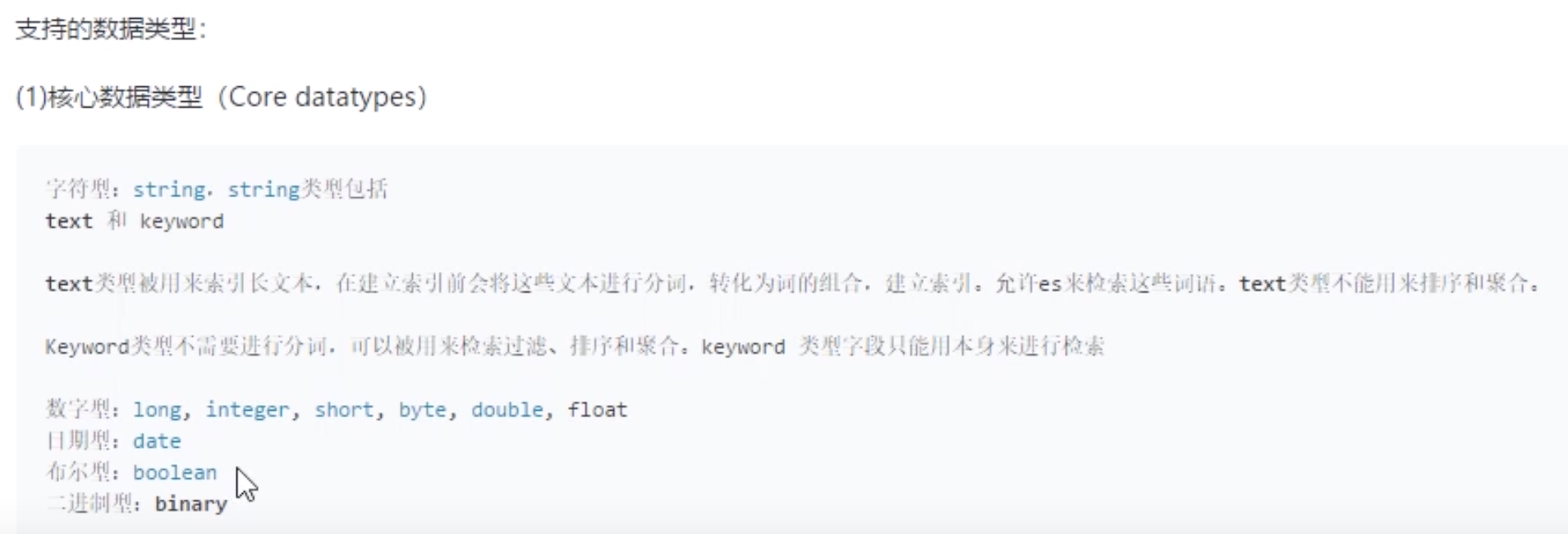
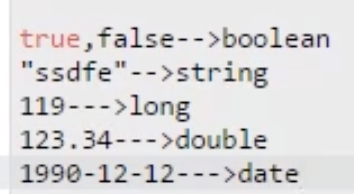
数值,日期类型必须是完全一样才能查出来,即精确查询,没有分词;但是text类型默认进行分词,只需要包含就可以查到
自定义mapping除了规定字段的类型,最大作用就是可以指定字段的属性是否分词,是否存储,是否索引等
字段类型
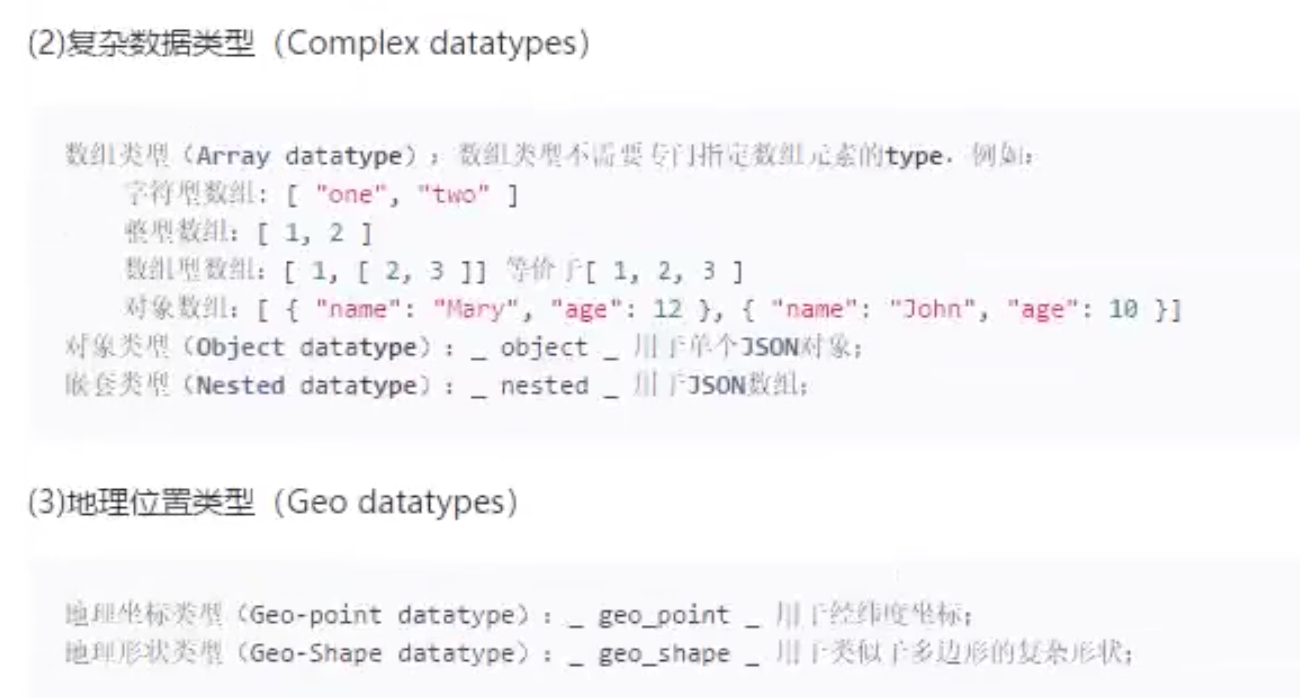
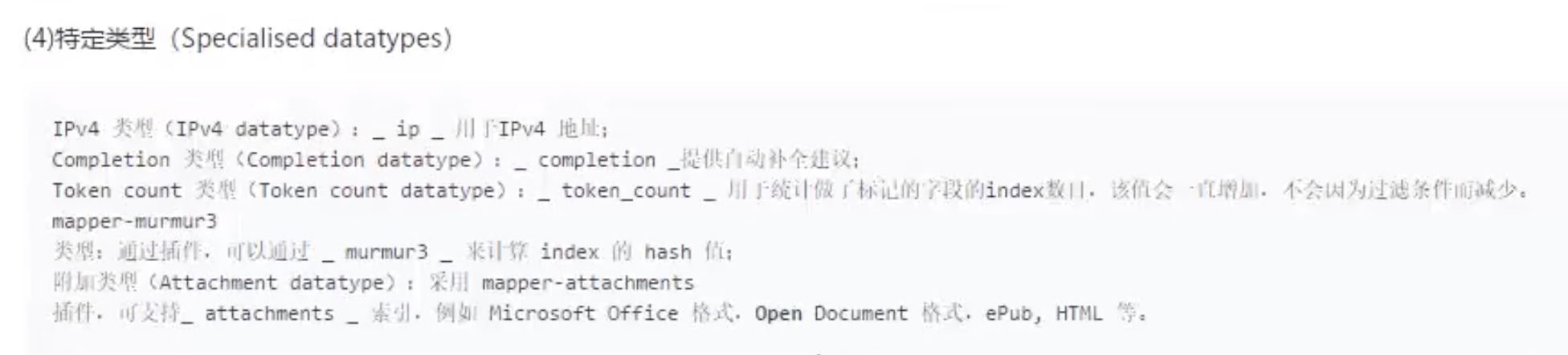
支持的属性

查询

term、terms只会从倒排索引中查询,如果倒排索引中没有就不会查到数据
terms表示包含其中一个即可。
基本查询







中文查询


Filter

建立倒排索引时,会默认转为小写的,所以查大写字符的时,查询条件要转为小写,termId为id100127


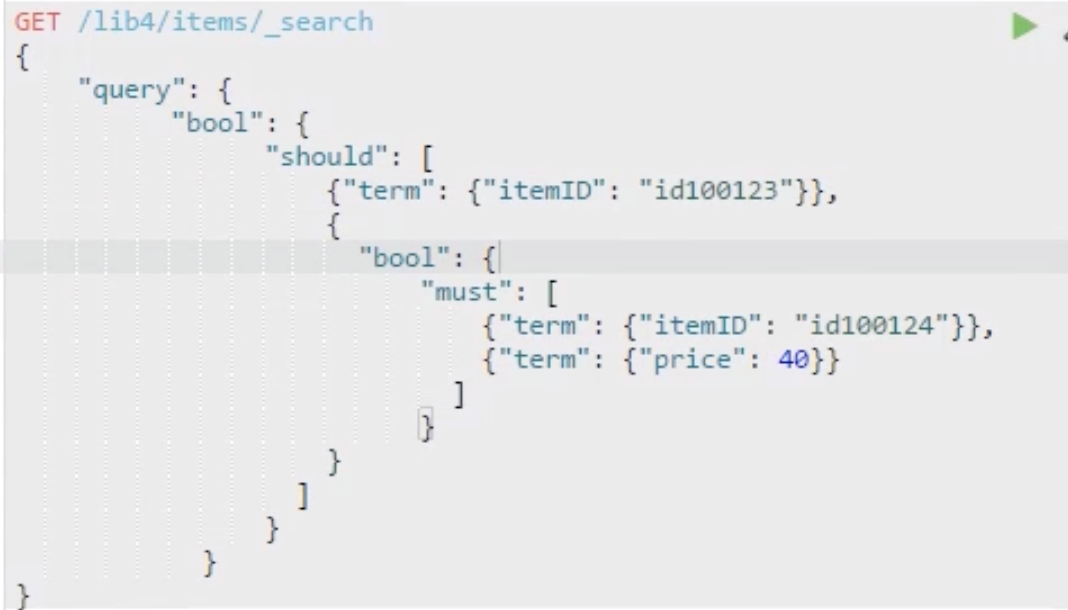

exists相当于数据库的is not null
将query转化为filter进行优化
聚合查询

cardinality相当于数据库的distinct

constant_score由于不查评分,效率会高一些
原理
解析es分布式结构特点

作为应用程序的使用方目前只需要关心怎么添加文档和搜索文档。这就是隐藏特性
垂直扩容是原集群节点数不变,新采购的机器配置高于旧机器。

路由相关到有相关数据的其他节点,就是将请求转发到其他节点,该及诶单将结果再转发回原始请求节点,最终返回给客户端(即应用程序)。
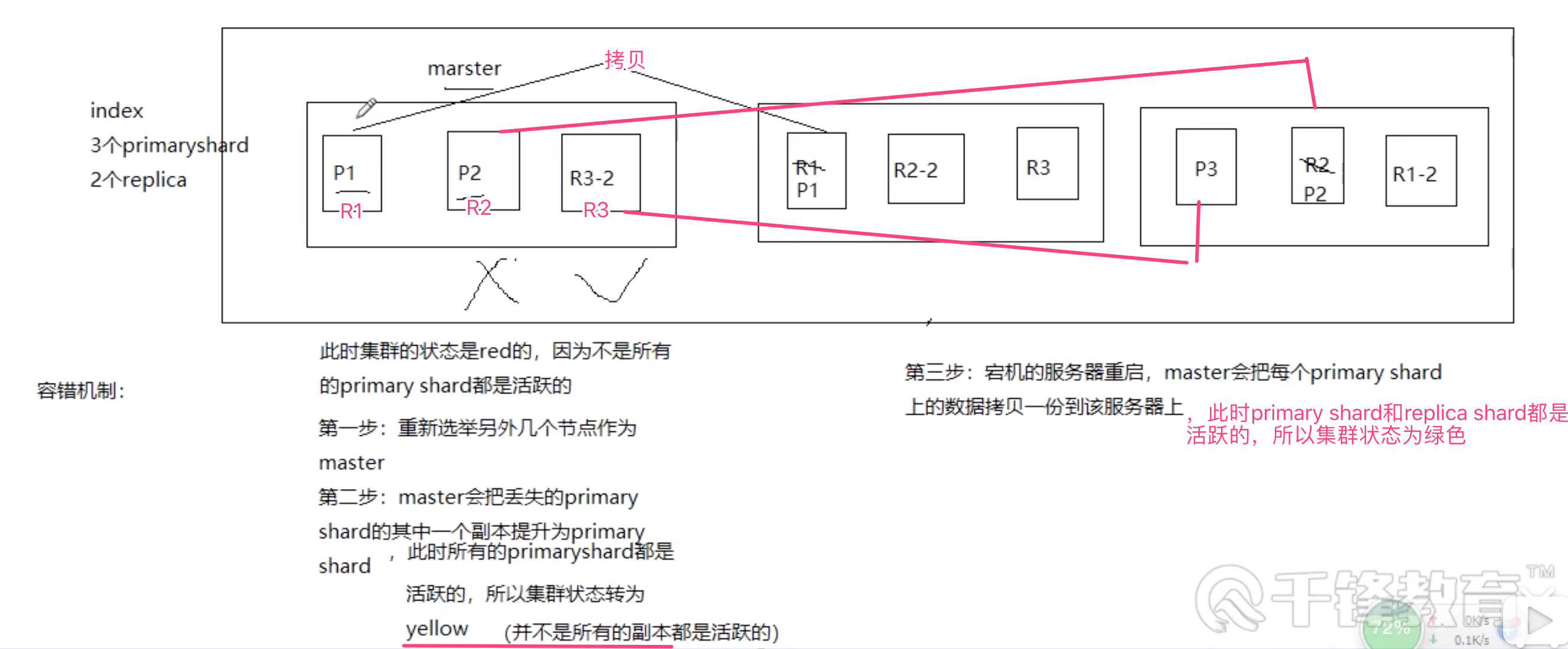
分片和副本机制



新增节点。
副本可以处理查询请求
水平扩容的过程

容错机制
文档核心元数据

从6开始一个index下只能有一个type

GUID算法可以保证在分布式并发情况下生成的id不会冲突
基于grovvy脚本实现partial update

文档数据路由原理
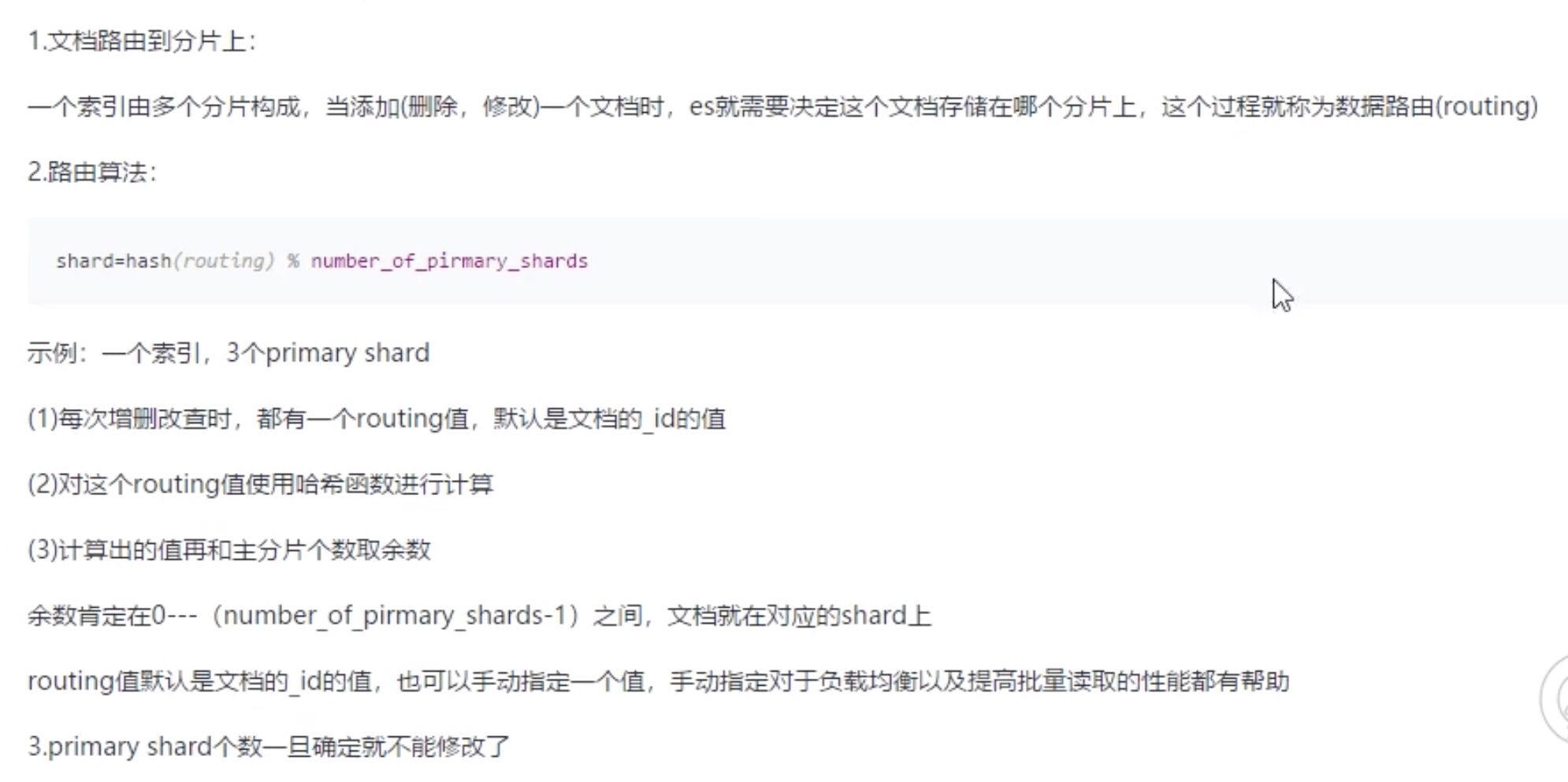
文档增删改内部原理

写一致原理和qurom机制


文档查询内部原理

分页查询中的deep paging问题
mysql也可能会出现

copyto
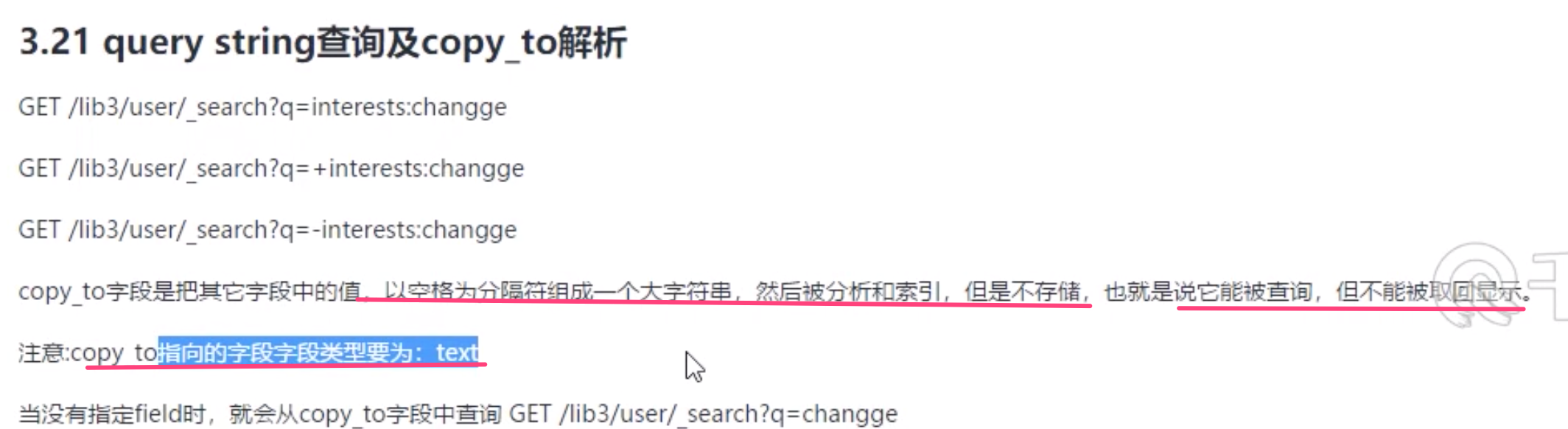

字符串排序问题

如何计算相关度分数


DocValues解析
默认开启的
es对非字符串类型(日期,数字等)除建立倒排索引外,还会建立一个正排索引

基于scroll技术滚动搜索大量数据

dynamic mapping策略

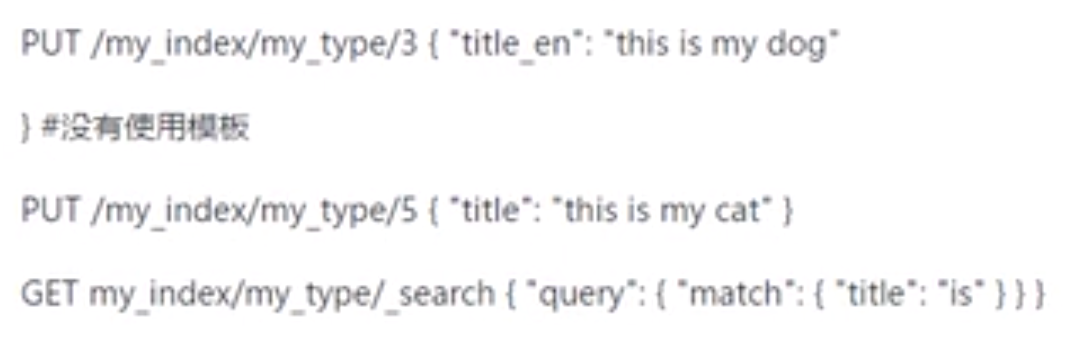
english分词器会把is,a,an等停用词去掉,这些词不会建立倒排索引。而standard会建立。
重建索引


索引不可变的原因