案例一
背景
1 | CREATE TABLE `timesheets` ( |
需要得到的结果: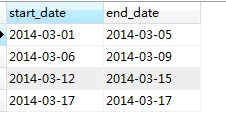
解答一
首先需要明确,查询的结果肯定是通过表自身的连接得到的,因为查询的两个字段来自不同的记录行,不妨分组得到可能的记录再筛选:1
2
3
4SELECT a.start_date,b.end_date
FROM timesheets a,timesheets b ,timesheets c
WHERE a.end_date<=b.end_date
GROUP BY a.start_date,b.end_date;
哪些记录需要排除呢,结果字段在原表同一条记录的两值之间的记录都得干掉,起点和起点可相同,终点和终点可相同:1
2
3
4
5
6
SELECT a.start_date,b.end_date
FROM timesheets a,timesheets b ,timesheets c
WHERE a.end_date<=b.end_date
GROUP BY a.start_date,b.end_date
HAVING MAX(CASE WHEN (a.start_date>c.start_date and a.start_date<=c.end_date) OR (b.end_date>=c.start_date and b.end_date<c.end_date) then 1 ELSE 0 END) =0 ;
基于hive版本1.2.1可以执行上面的语句,from多张表也没问题,而且having中有c也没问题。1
2
3
4
5
6
7
8
9
10
11
12
13
14如果having限定的是字段则必须也必须出现在select列表中。但如果字段被以聚合函数如sum、count、avg、min、max、first、last等计算获取的分组汇总信息则不受限制,可随意对这些汇总信息做所需的限定
a) where子句里进行连接
select a.学号,avg(b.成绩) as 各科平均分
from 学生表 a,选课成绩表 b
where a.学号=b.学号
group by a.学号
having avg(b.成绩)>=80;
b) 在having子句里进行连接
select a.学号,avg(b.成绩) as 各科平均分
from 学生表 a,选课成绩表 b
group by a.学号,b.学号
having a.学号=b.学号 and avg(b.成绩)>=80;
最后,从这个结果集中分组得到最终的结果,起始时间和组内最小的终止时间:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16SELECT d.start_date,
MIN(d.end_date)
FROM
(SELECT a.start_date,
b.end_date
FROM timesheets a,
timesheets b ,
timesheets c
WHERE a.end_date<=b.end_date
GROUP BY a.start_date,
b.end_date
HAVING MAX(CASE WHEN (a.start_date>c.start_date
AND a.start_date<=c.end_date)
OR (b.end_date>=c.start_date
AND b.end_date<c.end_date) THEN 1 ELSE 0 END) =0) d
GROUP BY d.start_date;
解法二
hive不支持不等值连接,下面给出的是mysql中的语法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#干掉起点时间在某记录起止时间之间的
SELECT a.start_date
FROM timesheets a
LEFT OUTER JOIN timesheets b
ON a.start_date>b.start_date AND a.start_date<=b.end_date GROUP BY a.start_date
HAVING COUNT(b.start_date)=0;//having表示关联不上的
#干掉终点时间在某记录起止时间之间的
SELECT a.end_date
FROM timesheets a
LEFT OUTER JOIN timesheets b
ON a.end_date>=b.start_date AND a.end_date<b.end_date
GROUP BY a.end_date HAVING COUNT(b.start_date)=0;
SELECT x.start_date,MIN(y.end_date)
FROM
(SELECT a.start_date
FROM timesheets a
LEFT OUTER JOIN timesheets b
ON a.start_date>b.start_date AND a.start_date<=b.end_date GROUP BY a.start_date
HAVING COUNT(b.start_date)=0
) x
INNER JOIN
(SELECT a.end_date
FROM timesheets a
LEFT OUTER JOIN timesheets b
ON a.end_date>=b.start_date AND a.end_date<b.end_date
GROUP BY a.end_date
HAVING COUNT(b.start_date)=0
) y
ON x.start_date<=y.end_date
GROUP BY x.start_date;
案例二
对案例一的拓展。1
2
3
4
5
6
7
8
9CREATE TABLE `t`(
`card_id` int,
`locator_id` int,
`starttime` int,
`endtime` int);
insert into t values(100 ,1 ,1 ,2),(100 ,1 ,2 ,3),(100 ,1 ,3 ,4),(100 ,1 ,5 ,6);
insert into t values(200 ,1 ,1 ,2),(200 ,1 ,2 ,3),(200 ,1 ,3 ,4),(200 ,1 ,5 ,6),(200 ,1 ,6 ,7);
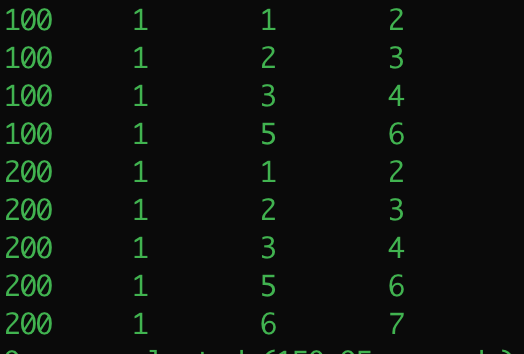
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26SELECT d.card_id,
d.starttime,
MIN(d.endtime)
FROM
(SELECT a.card_id,
a.starttime,
b.endtime
FROM t a,
t b ,
t c
WHERE a.endtime<=b.endtime
AND a.card_id = b.card_id
AND a.card_id = c.card_id
GROUP BY
a.card_id,
a.starttime,
b.endtime
HAVING MAX(CASE WHEN (a.starttime>c.starttime AND a.starttime<=c.endtime)
OR (b.endtime>=c.starttime AND b.endtime<c.endtime)
THEN 1 ELSE 0 END
) =0
) d
GROUP BY d.card_id,
d.starttime;
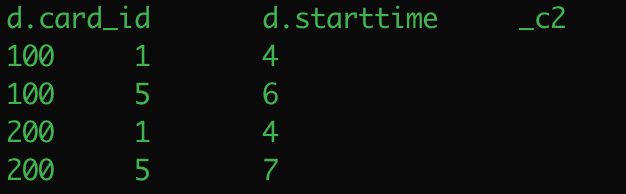
总结
笛卡尔积的使用
having分组筛选1
2
3
4MAX(CASE WHEN (a.starttime>c.starttime AND a.starttime<=c.endtime)
OR (b.endtime>=c.starttime AND b.endtime<c.endtime)
THEN 1 ELSE 0 END
)
案例三
1 |
|

参考:
https://blog.csdn.net/liyong199012/article/details/20628627
https://zhidao.baidu.com/question/749982848966951572.html
http://www.cnblogs.com/geekpaul/p/4125322.html
http://www.poluoluo.com/jzxy/200801/9937.html