HBase的存储架构图
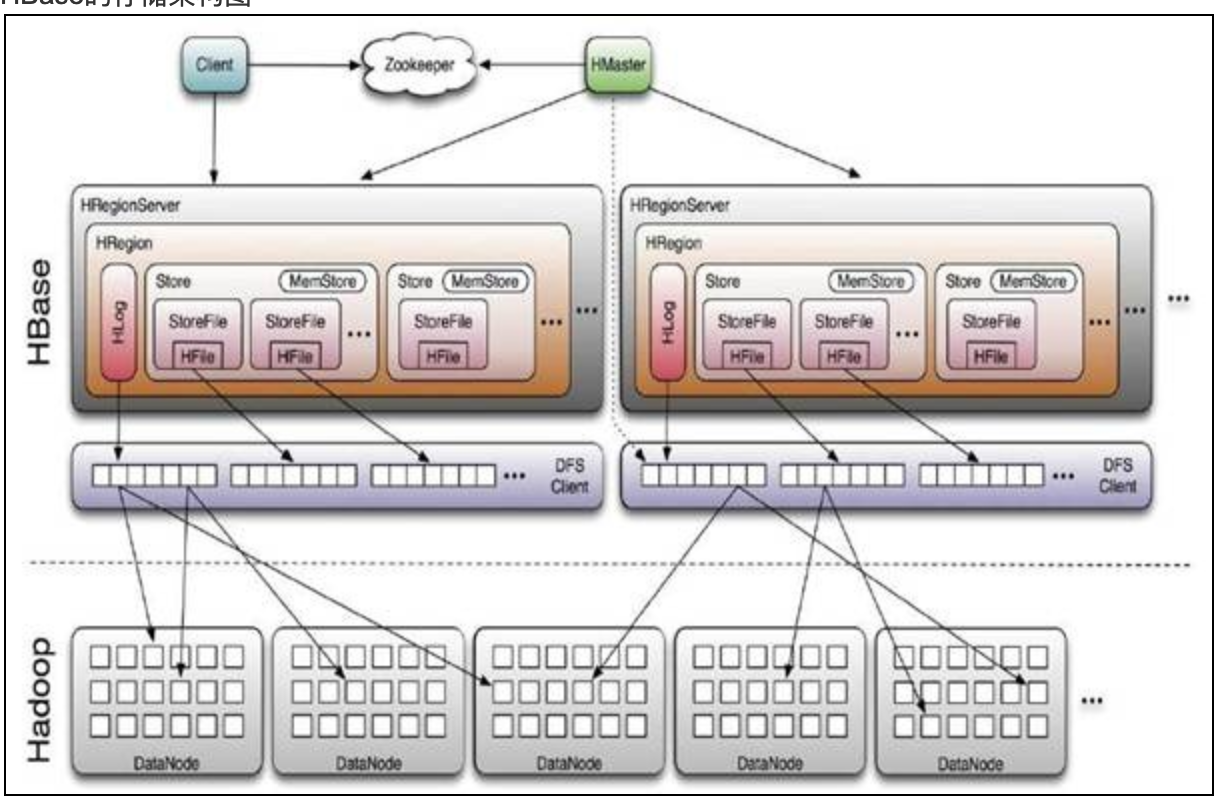
HBase操控两种基本类型的文件,一种用于存储WAL的log,另一种用于存储具体的数据。
这两种文件主要由HRegionServer来管理,但是在有的情况下HMaster会跳过HRegionServer,直接操作这两种文件。这些文件都被存储在HDFS上面,并且每个文件包含了多个数据块。
数据如何被写到实际存储中
Client发起了一个HTable.put(Put)请求给HRegionServer,HRegionServer会将请求匹配到某个具体的HRegion上面。紧接着的操作时决定是否写WAL log。是否写WAL log由Client传递的一个标志决定,你可以设置这个标志:Put.setWriteToWAL(boolean write)。WAL log文件是一个标准的Hadoop SequenceFile(现在还在讨论是否应该把文件格式改成一个更适合HBase的格式)。在文件中存储了HLogKey,这些Keys包含了和实际数据对应的序列号,用途是当RegionServer崩溃以后能将WAL log中的数据同步到永久存储中去。做完这一步以后,Put数据会被保存到MemStore中,同时会检查MemStore是否已经满了,如果已经满了,则会触发一个Flush to Disk的请求。HRegionServer有一个独立的线程来处理Flush to Disk的请求,它负责将数据写成HFile文件并存到HDFS上。它也会存储最后写入的数据序列号,这样就可以知道哪些数据已经存入了永久存储的HDFS中。
数据的大致流程。假设你需要通过某个特定的RowKey查询一行记录,首先Client端会连接Zookeeper Qurom,通过Zookeeper,Client能获知哪个Server管理-ROOT- Region。接着Client访问管理-ROOT-的Server,进而获知哪个Server管理.META.表。这两个信息Client只会获取一次 并缓存起来。在后续的操作中Client会直接访问管理.META.表的Server,并获取Region分布的信息。一旦Client获取了这一行的位 置信息,比如这一行属于哪个Region,Client将会缓存这个信息并直接访问HRegionServer。久而久之Client缓存的信息渐渐增 多,即使不访问.META.表也能知道去访问哪个HRegionServer。
HRegionServer打开这个Region并创建一个HRegion对象。当HRegion打开以后,它给每个table的每个 HColumnFamily创建一个Store实例。每个Store实例拥有一个或者多个StoreFile实例。StoreFile对HFile做了轻 量级的包装。除了Store实例以外,每个HRegion还拥有一个MemStore实例和一个HLog实例。
存储文件
HBase在HDFS上面的所有文件有一个可配置的根目录(由zookeeper.znode.parent参数决定目录名称),默认根目录是/hbase。通过使用hadoop的DFS工具就可以看到这些文件夹的结构。1
2
3
4
5[hadoop@hostname /home/q/hadoop/hadoop-2.3.0-cdh5.1.0]$ ./bin/hdfs dfs -ls /
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2014-08-04 16:34 /hbase_test1
drwxr-xr-x - hadoop supergroup 0 2014-08-28 16:37 /hbase_test2
drwxr-xr-x - hadoop supergroup 0 2014-08-05 10:02 /user
在根目录下有个WALs文件夹,这里存了所有由HLog管理的WAL log文件。在WALs目录下的每个文件夹对应一个HRegionServer,每个HRegionServer下面的每个log文件对应一个Region1
2
3
4
5
6
7
8
9[hadoop@hostname /home/q/hadoop/hadoop-2.3.0-cdh5.1.0]$ ./bin/hdfs dfs -ls /hbase_test2/WALs
Found 3 items
drwxr-xr-x - hadoop supergroup 0 2014-09-10 11:33 /hbase_test2/WALs/hostname,60020,1409216059863
drwxr-xr-x - hadoop supergroup 0 2014-09-10 11:33 /hbase_test2/WALs/hostname,60020,1409220327233
drwxr-xr-x - hadoop supergroup 0 2014-09-10 11:33 /hbase_test2/WALs/hostname,60020,1409216096540
HBase的每个Table在根目录下面用一个文件夹来存储,文件夹的名字就是Table的名字。1
2
3
4
5
6
7
8
9[hadoop@hostname /home/q/hadoop/hadoop-2.3.0-cdh5.1.0]$ ./bin/hdfs dfs -ls /hbase_test2/data/default
drwxr-xr-x - hadoop supergroup 0 2014-09-04 10:32 /hbase_test2/data/default/TestTable
drwxr-xr-x - hadoop supergroup 0 2014-08-05 18:37 /hbase_test2/data/default/airfare_oneway
drwxr-xr-x - hadoop supergroup 0 2014-08-05 18:38 /hbase_test2/data/default/airfare_return
drwxr-xr-x - hadoop supergroup 0 2014-08-05 18:29 /hbase_test2/data/default/blacklist
在Table文件夹下面每个Region也用一个文件夹来存储,但是文件夹的名字并不是Region的名字,而是Region的名字通过Jenkins Hash计算所得到的字符串。这样做的原因是Region的名字里面可能包含了不能在HDFS里面作为路径名的字符。1
2
3
4
5
6
7[hadoop@hostname /home/q/hadoop/hadoop-2.3.0-cdh5.1.0]$ ./bin/hdfs dfs -ls /hbase_test2/data/default/TestTable
Found 5 items
drwxr-xr-x - hadoop supergroup 0 2014-08-05 10:02 /hbase_test2/data/default/TestTable/.tabledesc
drwxr-xr-x - hadoop supergroup 0 2014-08-05 10:02 /hbase_test2/data/default/TestTable/.tmp
drwxr-xr-x - hadoop supergroup 0 2014-09-04 10:31 /hbase_test2/data/default/TestTable/3a5ac9e6882c9204bd24f6adac4b1af8
drwxr-xr-x - hadoop supergroup 0 2014-09-04 10:31 /hbase_test2/data/default/TestTable/4ce3e4160a0bba40f8784f17d38f6dcb
drwxr-xr-x - hadoop supergroup 0 2014-09-04 10:32 /hbase_test2/data/default/TestTable/736bab73a6d47458f63d084e84b5415d
在每个Region文件夹下面每个ColumnFamily也有自己的文件夹,在每个ColumnFamily文件夹下面就是一个个HFile文件了1
2
3
4
5[hadoop@hostname /home/q/hadoop/hadoop-2.3.0-cdh5.1.0]$ ./bin/hdfs dfs -ls /hbase_test2/data/default/TestTable/3a5ac9e6882c9204bd24f6adac4b1af8
Found 3 items
-rwxr-xr-x 3 hadoop supergroup 68 2014-09-04 10:31 /hbase_test2/data/default/TestTable/3a5ac9e6882c9204bd24f6adac4b1af8/.regioninfo
drwxr-xr-x - hadoop supergroup 0 2014-09-04 11:13 /hbase_test2/data/default/TestTable/3a5ac9e6882c9204bd24f6adac4b1af8/.tmp
drwxr-xr-x - hadoop supergroup 0 2014-09-04 11:13 /hbase_test2/data/default/TestTable/3a5ac9e6882c9204bd24f6adac4b1af8/info
所以整个文件夹结构看起来应该是这个样子的:
/
在每个Region文件夹下面你会发现一个.regioninfo文件,这个文件用来存储这个Region的Meta Data。通过这些Meta Data我们可以重建被破坏的.META.表
HFile
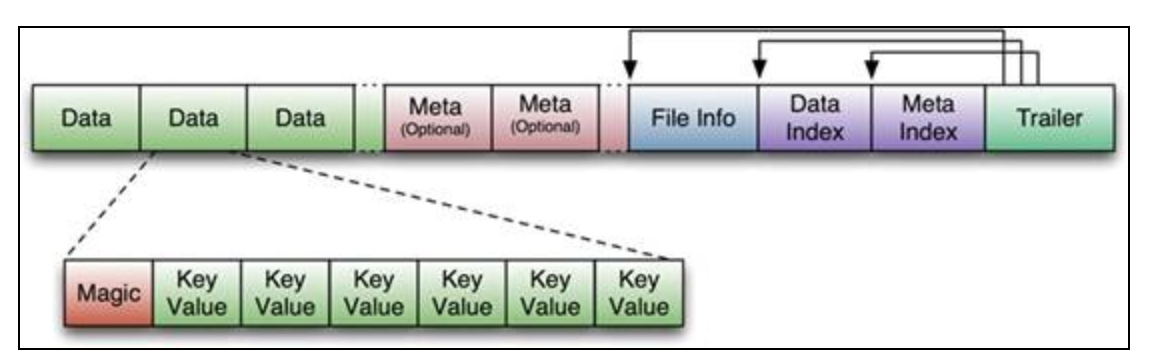
如上图所示,HFile这个文件是不定长的,长度固定的只有其中的两块:Trailer和FileInfo。正如图中所示的,Trailer中有指针指向其他数据块的起始点。Index数据块记录了每个Data块和Meta块的起始点。Data块和Meta块都是可有可无的,但是对于大部分的HFile,你都可以看到Data块。
关于文件块的大小:
默认块大小64KB,在创建表时可以通过HColumnDescriptor设定每个Family的块大小。
大数据块:适合顺序查找,不适合随机查找。
小数据块,适合随机查找,需要更多内存保存Data Index,创建文件慢,更多的flush操作
HFile.main()本身就提供了一个用来dump HFile的工具,类是org.apache.hadoop.hbase.io.hfile.HFile1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65[hadoop@hostname /home/q/hbase/hbase-0.98.1-cdh5.1.0]$ ./bin/hbase org.apache.hadoop.hbase.io.hfile.HFile -v -p -m -f hdfs://mycluster:8020/hbase_test2/data/default/t2/a01c6b2e3bd8b7b2d7c7da725805552b/f1/73cfd18ddfc24b29a3699df4cf7ba88c
2014-09-10 16:45:18,077 INFO [main] Configuration.deprecation: hadoop.native.lib is deprecated. Instead, use io.native.lib.available
2014-09-10 16:45:18,207 INFO [main] util.ChecksumType: Checksum using org.apache.hadoop.util.PureJavaCrc32
2014-09-10 16:45:18,208 INFO [main] util.ChecksumType: Checksum can use org.apache.hadoop.util.PureJavaCrc32C
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:[file:/home/q/prj/mvn/repo/org/slf4j/slf4j-log4j12/1.7.5/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class|file:/home/q/prj/mvn/repo/org/slf4j/slf4j-log4j12/1.7.5/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]]
SLF4J: Found binding in [jar:[file:/home/q/hbase/hbase-0.98.1-cdh5.1.0/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class|file:/home/q/hbase/hbase-0.98.1-cdh5.1.0/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]]
SLF4J: Found binding in [jar:[file:/usr/lib/hadoop-0.20/lib/slf4j-log4j12-1.4.3.jar!/org/slf4j/impl/StaticLoggerBinder.class|file:/usr/lib/hadoop-0.20/lib/slf4j-log4j12-1.4.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2014-09-10 16:45:18,919 INFO [main] Configuration.deprecation: fs.default.name is deprecated. Instead, use fs.defaultFS
Scanning -> hdfs://mycluster:8020/hbase_test2/data/default/t2/a01c6b2e3bd8b7b2d7c7da725805552b/f1/73cfd18ddfc24b29a3699df4cf7ba88c
2014-09-10 16:45:19,035 INFO [main] bucket.FileIOEngine: Allocating 1 GB, on the path:/home/q/hbase/bucketcache/cache.data
2014-09-10 16:45:19,042 INFO [main] bucket.BucketCache: Started bucket cache
2014-09-10 16:45:19,045 INFO [main] hfile.CacheConfig: Allocating LruBlockCache with maximum size 1.4 G
K: 1409554876558|row/f1:/1409624450156/Put/vlen=5/mvcc=0 V: iugsa(这一部分是存储具体数据的KeyValue对,每个数据块除了开头的Magic以外就是一个个KeyValue对拼接而成)
K: 1409560567750|row/f1:/1409624421019/Put/vlen=7/mvcc=0 V: agoajga
K: 1409562897135|row/f1:/1409624602499/Put/vlen=6/mvcc=0 V: sdaojg
Block index size as per heapsize: 400
reader=hdfs://mycluster:8020/hbase_test2/data/default/t2/a01c6b2e3bd8b7b2d7c7da725805552b/f1/73cfd18ddfc24b29a3699df4cf7ba88c,
compression=none,
cacheConf=CacheConfig:enabled [cacheDataOnRead=true] [cacheDataOnWrite=false] [cacheIndexesOnWrite=false] [cacheBloomsOnWrite=false] [cacheEvictOnClose=false] [cacheCompressed=false],
firstKey=1409554876558|row/f1:/1409624450156/Put,
lastKey=1409562897135|row/f1:/1409624602499/Put,
avgKeyLen=31,
avgValueLen=6,
entries=3,
length=1082
Trailer:(这一部分是Tailer块的具体内容)
fileinfoOffset=335,
loadOnOpenDataOffset=217,
dataIndexCount=1,
metaIndexCount=0,
totalUncomressedBytes=981,
entryCount=3,
compressionCodec=NONE,
uncompressedDataIndexSize=44,
numDataIndexLevels=1,
firstDataBlockOffset=0,
lastDataBlockOffset=0,
comparatorClassName=org.apache.hadoop.hbase.KeyValue$KeyComparator,
majorVersion=2,
minorVersion=3
Fileinfo:(这一部分是FileInfo块的具体内容)
BLOOM_FILTER_TYPE = ROW
DELETE_FAMILY_COUNT = \x00\x00\x00\x00\x00\x00\x00\x00
EARLIEST_PUT_TS = \x00\x00\x01H4)\xB2\x9B
LAST_BLOOM_KEY = 1409562897135|row
MAJOR_COMPACTION_KEY = \xFF
MAX_SEQ_ID_KEY = 5
TIMERANGE = 1409624421019....1409624602499
hfile.AVG_KEY_LEN = 31
hfile.AVG_VALUE_LEN = 6
hfile.LASTKEY = \x00\x111409562897135|row\x02f1\x00\x00\x01H4,w\x83\x04
Mid-key: \x00\x111409554876558|row\x02f1\x00\x00\x01H4*$l\x04
Bloom filter:
BloomSize: 8
No of Keys in bloom: 3
Max Keys for bloom: 6
Percentage filled: 50%
Number of chunks: 1
Comparator: RawBytesComparator
Delete Family Bloom filter:
Not present
Scanned kv count -> 3
org.apache.hadoop.hbase.KeyValue