last conact值一直增大是cdh5 的bug:http://heylinux.com/archives/3490.html
集群故障:
操作失误,导致业务受影响时间加长(10分30秒)。
1) 手动stop datanode(问题根源:不用手动操作,namenode自己会kill datanode,否则namenode会一直尝试去进行kill datanode)
这样下线会导致namenode只是发现datanode连接不上而不是死亡,并且开始不停的尝试获取心跳。此期间业务请求还会往此datanode进行发送,从而影响业务响应时间。
2) 修改slave文件去掉下线datanode节点,namenode进行 /home/q/hadoop/q_hadoop/bin/hadoop dfsadmin -refreshNodes
datanode停机后汇报到namenode的时间差问题 默认10分30秒,该操作时间也是维护窗口(网络抖动、下线多久才hdfs balance),设置太小不适合运维。1
2
3
4
5
6
7HDFS默认的超时时间为10分钟+30秒。
这里暂且定义超时时间为timeout
计算公式为:
timeout = 2 * dfs.namenode.heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的dfs.namenode.heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认的大小为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒
改小参数值会导致namenode负载较高。
http://www.firefoxbug.com/index.php/archives/2429/
如下操作可以让namenode迅速知晓datanode死亡并下线服务(正确操作)。
- 修改slave文件去掉下线datanode节点,namenode执行
- /home/q/hadoop/q_hadoop/bin/hadoop dfsadmin -refreshNodes
该操作会kill掉节点上datanode服务,namenode感知节点dead并下线服务。
问题排查及改进
datanode 下线操作很常见,业务受影响严重意味着业务强依赖hbase,客户端没有设置超时时间并且没有重试机制。( tc 异步客户端默认不设置超时时间,会一直等待响应 )
在Hadoop集群中,当一个datanode发生故障(宕机,进程被kill,网络不通等)时,namenode在一定时间内(默认10分30秒)无法收到该datanode的心跳信息,就会将该datanode从集群中下线设置为dead。在感知到下线之前这段时间,认为该节点还在提供服务,访问该节点的数据块就会失败,为了尽快让namenode感知到该节点已经下线,我们可以手动进行一些操作,具体如下:
1.规范化datanode下线操作,有两种方法:
方法一: 修改salve文件后namenode执行refresh。让namenode去kill datanode并下线服务。
方法二:引入参数 dfs.hosts.exclude, 类似于对应slave文件的参数dfs.hosts。
在Namenode上把需要Decommission的Datanode的机器名加入到dfs.hosts.exclude(该配置项在hdfs-site.xml)所指定文件中,也就是告诉Namenode哪些Datanode要被Decommission。
在hdfs-site.xml文件中增加配置1
2
3
4
5
6
7
8<property>
<name>dfs.hosts</name>
<value>/home/q/hadoop/hadoop-2.5.0-cdh5.2.0/etc/hadoop/slaves</value>
</property>
<property>
<name>dfs.hosts.exclude</name>
<value>/home/q/hadoop/hadoop-2.5.0-cdh5.2.0/etc/hadoop/excludes</value>
</property>
1)下线datanode
2)执行命令./bin/hdfs dfsadmin -refreshNodes
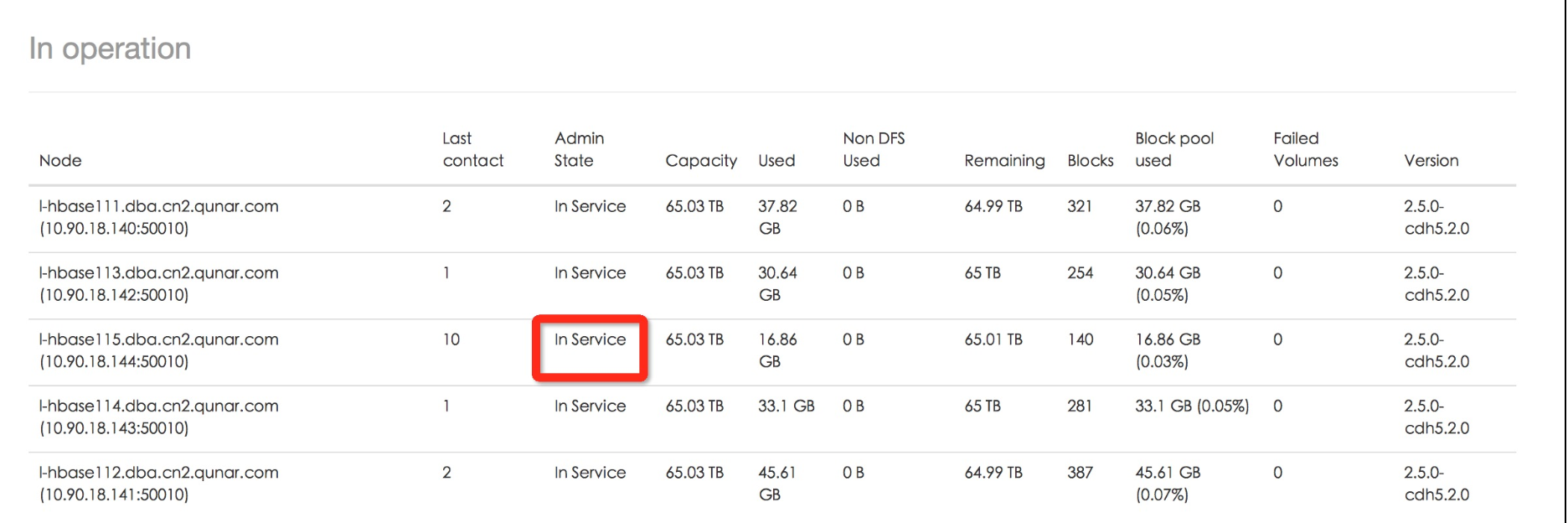
下线datanode后该节点的last contact一直增大,Admin State为In Service状态。
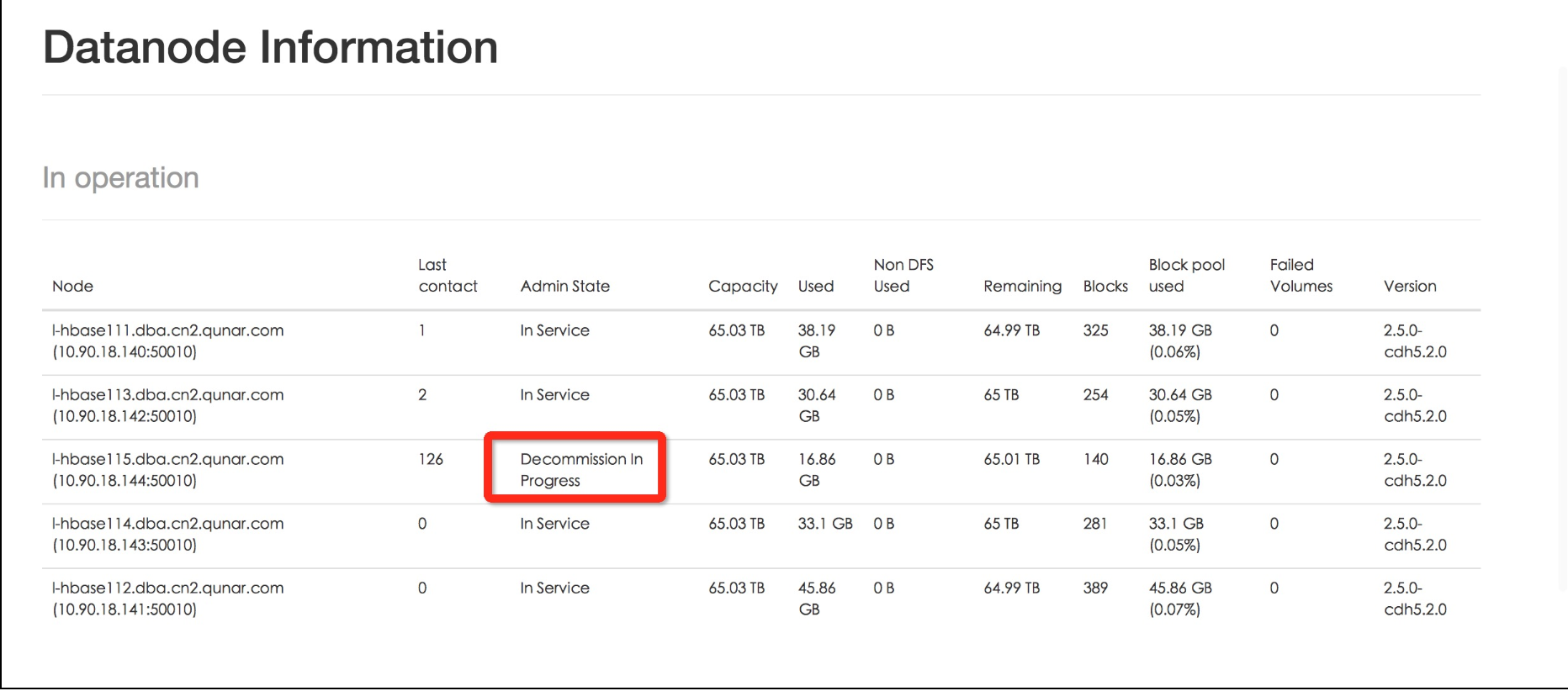
执行refresh操作后节点状态Admin State为Decommisson In Progress,last contact值依旧增大,该节点数据都balance完成后状态变为退役完成Decommissioned 。
该方法会导致last contact一直增大。
2.客户端设置超时时间和重试机制1
2
3
4hbase.rpc.timeout rpc超时时间
hbase.client.operation.timeout 写超时的参数
hbase.client.scanner.timeout.period 查询scan超时的参数
client设置参数,请求超时后client发起重试。
3.datanode参数优化
datanode 相关优化功能点主要游:
1)开启Short Circuit Local Read 功能
2)开启Hedged Read功能。
以下内容为整理和实际实践笔记:
在Hadoop集群中,当一个datanode发生故障(宕机,进程被kill,网络不通等)时,namenode在一定时间内(默认10分30秒)无法收到该datanode的心跳信息,就会将该datanode从集群中下线设置为dead。在感知到下线之前这段时间,认为该节点还在提供服务,访问该节点的数据块就会失败,为了尽快让namenode感知到该节点已经下线,我们可以手动进行一些操作,具体如下:
添加文件excludes,在该文件中添加想要退役节点的机器名
在hdfs-site.xml文件中增加配置1
2
3
4<property>
<name>dfs.hosts.exclude</name>
<value>/home/q/hadoop/hadoop-2.5.0-cdh5.2.0/etc/hadoop/excludes</value>
</property>
最后执行命令./bin/hdfs dfsadmin -refreshNodes
下面我执行操作之后web ui的情况
可以通过观察,首先我直接关闭了一台datanode,节点还是处于in Service中,只是last contact在不断增大
接着根据上面的操作执行了./bin/hdfs dfsadmin -refreshNodes之后节点在退役过程中
最后等节点数据都转移完成后,退役完成Decommissioned
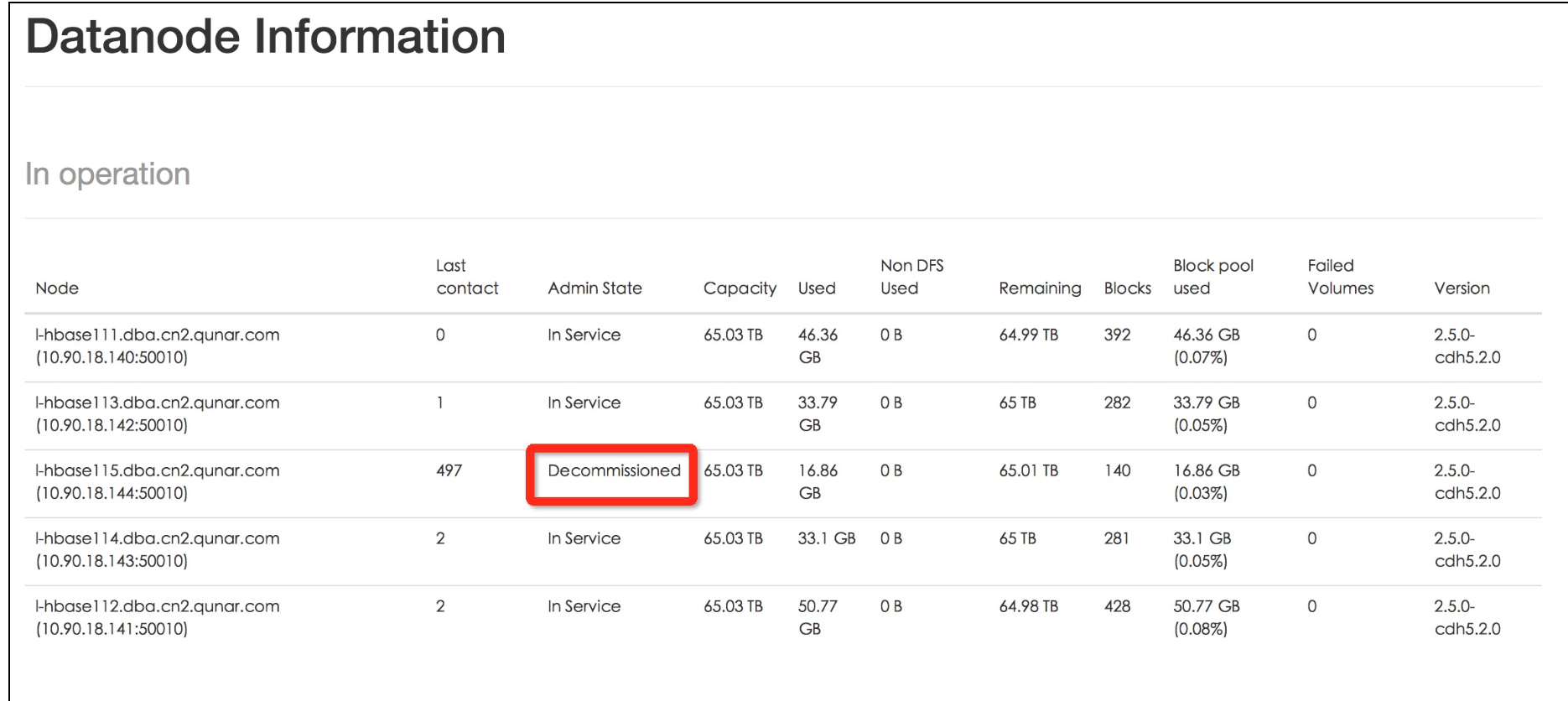
验证成功
访问web UI查看集群信息
访问http://master:50070/可以看到"Live Nodes”的数量,如果增加了新节点数,说明添加成功。
执行命令查看
1 | yarn rmadmin -refreshNodes |
集群负载均衡
在master主机上面,运行start-balancer.sh进行数据负载均衡。目的是将其他节点的数据分担一些到新节点上来,看集群原来数据的多少需要一定的时间才能完成。
设置带宽,配置均衡器balancer,一般不在主节点上运行,以避免影响业务,可以有专门的balancer节点1
2
3
4
5hdfs dfsadmin -setBalancerBandwidth 1048576
# 如果某个datanode的磁盘里用率比平均水平高出5%,Blocks向其他低于平均水平的datanode中传送
hadoop balancer
或者
start-balancer.sh -threshold 5
负载均衡作用:当节点出现敀障,或新增加节点时,数据块可能分布不均匀,负载均衡可重新平衡各个datanode上数据块的分布,使得所有的节点数据和负载能处于一个相对平均的状态,从而避免由于新节点的加入而效率降低(如果不进行balance,新数据一般会被插入到新节点中)
随时时间推移,各个datanode上的块分布来越来越不均衡,这将降低MR的本地性,导致部分datanode相对更加繁忙。
balancer是一个hadoop守护进程,它将块从忙碌的datanode移动相对空闲的datanode,同时坚持块复本放置策略,将复本分散到不同的机器、机架。
balancer会促使每个datanode的使用率与整个集群的使用率接近,这个“接近”是通过-threashold参数指定的,默认是10%。
不同节点之间复制数据的带宽是受限的,默认是1MB/s,可以通过hdfs-site.xml文件中的dfs.balance.bandwithPerSec属性指定(单位是字节)。
建议定期执行均衡器,如每天或者每周。
新增节点是需要同时启动nodemanager1
2hadoop-daemon.sh start datanode
yarn-daemon.sh start nodemanager
参考:
https://www.cnblogs.com/fefjay/p/6048269.html
https://www.cnblogs.com/learn21cn/p/6196183.html