学习来源:HBase官网和http://hbasefly.com/
Java GC
GC的出现是来源于在内存管理时大多数内存对象要么生存周期特别短,可以快速进行内存回收。要么生存周期比较长。 JVM将整个堆内存分为两部分:新生代(young generation)和老生代(tenured generation),同时对于常驻内存的对象JVM设有一个非堆内存区-Perm区(主要是存放静态的类信息和方法信息),class信息和meta元数据信息就存放在此区。
其中Young区为了方便垃圾回收细分为Eden区和两个Survivor区:S0和S1。因此JVM内存结构如下:
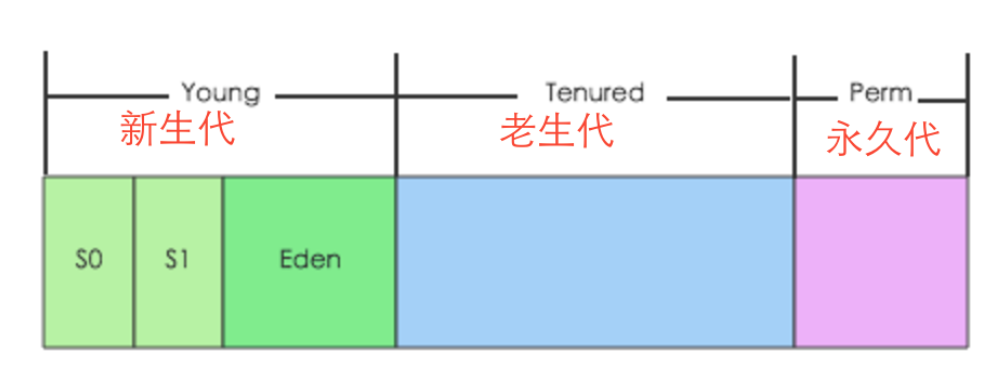
一个内存对象创建后首先会进入新生代,如果内存对象存活时间很长后会迁移到老生代。
在大多数对延迟敏感的业务场景下(比如HBase),建议使用如下JVM参数,-XX:+UseParNewGC和XX:+UseConcMarkSweepGC,其中前者表示对新生代执行并行的垃圾回收机制,而后者表示对老生代执行并行标记-清除垃圾回收机制。可见,JVM允许针对不同内存区执行不同的GC策略。
GC信息查看
jstat -gcutil 3600
S0 S1 E O P YGC YGCT FGC FGCT GCT
0.00 53.12 28.15 93.10 99.17 455569 3210.991 3470 196.670 3407.661
S0 — Heap上的 Survivor space 0 区已使用空间的百分比
S1 — Heap上的 Survivor space 1 区已使用空间的百分比
E — Heap上的 Eden space 区已使用空间的百分比
O — Heap上的 Old space 区已使用空间的百分比
P — Perm space 区已使用空间的百分比
YGC — 从应用程序启动到采样时发生 Young GC 的次数
YGCT– 从应用程序启动到采样时 Young GC 所用的时间(单位秒)
FGC — 从应用程序启动到采样时发生 Full GC 的次数
FGCT– 从应用程序启动到采样时 Full GC 所用的时间(单位秒)
GCT — 从应用程序启动到采样时用于垃圾回收的总时间(单位秒)
如果gc没有问题,继续查看thriftserver的连接数是否异常,如果连接数打满也会有问题:
netstat -apn|grep 15046|grep 9090|wc -l
新生代GC策略-Parallel New Collector
新生代为了方便进行内存回收,分为S0、S1、Eden三部分。新建的内存对象是存放在Eden区,当Eden区满后会触发一次小GC(Minor GC):GC算法会检查所有对象的引用情况,如果对象还被引用则表示存活并进行标记,检查完Eden区后会将标记为存活的对象迁移到S0区,然后回收整个Eden区。 当过段时间Eden区再次满之后,GC算法会检查Eden区和S0区存活的对象并将所有存活的对象迁移到S1区,然后回收整个Eden区和S0区的内存空间。因此S0、S1总会有一个区是空闲预留给下一次存放迁移的存活对象的。
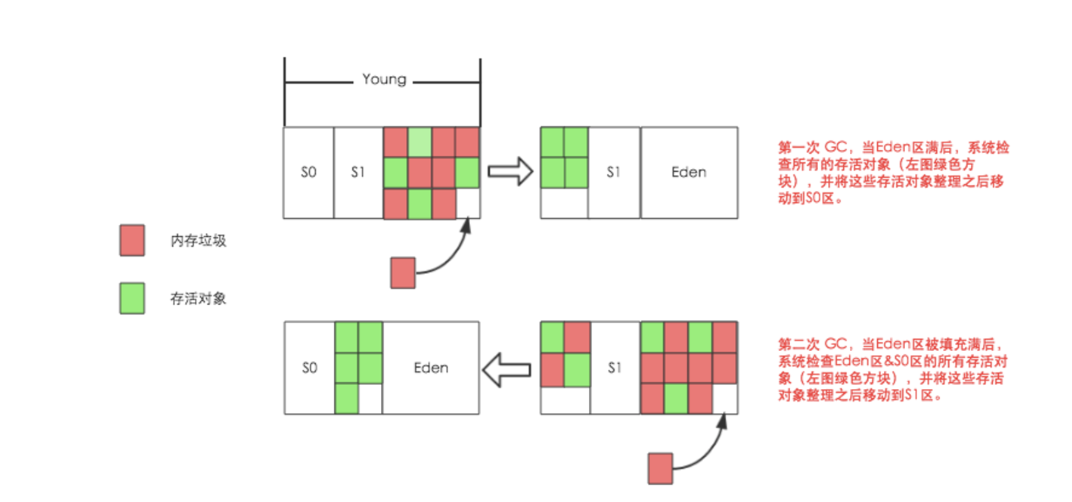
新生代GC算法为复制算法,一般情况影响会很小。需要注意的是:
1.算法会执行 stop-the-world暂停,但是时间非常短。因为Young区通常会设置的比较小(不建议超过512M),同时JVM会启动大量线程并发执行,一次Minor GC通常会在毫秒级完成。
2.新生代GC不会出现内存碎片,每次GC之后都会将存活对象迁移到整个空闲的S0或S1空间,然后回收整个非存活对象存储的区(Eden+ S1/S0)
新生代的对象什么时候迁移到老年代?
内存中所有对象都会维护一个计数器,每次Minor GC迁移一个内存对象后,该内存对象所属的计数器+1,当内存对象的计数达到一定阀值则会将该内存对象迁移到老生代。阀值通过JVM参数XX:MaxTenuringThreshold指定。
老生代GC策略-Concurrent Mark-Sweep
每次执行Minor GC之后都会有部分生命周期长的对象迁移到老生代,久而久之老生代空间也会占满,同样此时需要堆老生代进行GC操作。常见的算法有CMS、G1,先介绍CMS(Concurrent Mark-Sweep)算法。
CMS算法整个流程分为6个阶段,其中部分阶段会执行 ‘stop-the-world’ 暂停,部分阶段会和应用线程一起并发执行:
initial-mark:这个阶段虚拟机会暂停所有正在执行的任务。这一过程虚拟机会标记所有 ‘根对象’(ROOT), 所谓‘根对象’,一般是指一个运行线程直接引用到的对象。虽然会暂停整个JVM,但因为’根对象’相对较少,这个过程通常很快。
concurrent mark:垃圾回收器会从‘根节点’开始,将所有引用到的对象都打上标记。 这个阶段应用程序的线程和标记线程并发执行,因此用户并不会感到停顿。
concurrent precleaning:并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行mark阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。
remark:在阶段3的基础上对查找到的对象进行重新标记,这一阶段会暂停整个JVM,但是因为阶段3已经欲检查出了所有新进入的对象,因此这个过程也会很快。
concurrent sweep:上述3阶段完成了引用对象的标记,此阶段会将所有没有标记的对象作为垃圾回收掉。这个阶段应用程序的线程和标记线程并发执行。
concurrent reset:重置CMS收集器的数据结构,等待下一次垃圾回收。
相应的,对于CMS算法,也需要关注两点:
- ‘stop-the-world’暂停时间也很短暂,耗时较长的标记和清理都是并发执行的。
- CMS算法在标记清理之后并没有重新压缩分配存活对象,因此整个老生代会产生很多的内存碎片。
CMS算法缺点
理想情况下CMS的stop-thr-world时间会很短,ms级别。但是真实业务场景通常并非如此,在读写压力很大的情况下会出现长时间的卡顿,甚至严重阻塞读写。HBase相关会导致RS和ZK超时,RS异常离线后shutdown。 CMS在两种场景下会出现严重的Full GC: Concurrent Failure && Promotion Failure。
Concurrent Failure
根据CMS GC算法,当老生代正在进行GC时,由于读写压力特别大导致新生代一批内存对象需要进入老生代,老生代由于还没有GC完成导致没有足够的空间容纳需要新迁移的新生代对象。这种场景下CMS回收器会stop-the-world,并且回收算法退化到单线程复制算法,重新分配整个堆内存的存活对象到S0中并释放所有其他空间。整个过程会持续很长时间,影响较大。
JVM提供参数XX:CMSInitiatingOccupancyFraction=N来设置CMS回收的时机,其中N表示当前老生代已使用内存占总内存的比例,该值默认为68,可以将该值修改的更小使得回收更早进行。 CMS回收器更早回收就可以避免该类FULL GC的发生。
Promotion Failure
假设此时设置XX:CMSInitiatingOccupancyFraction=60,但是在已使用内存还没有达到总内存60%的时候,已经没有空间容纳从新生代迁移的对象了。罪魁祸首就是内存碎片,上文中提到CMS算法会产生大量碎片,当碎片容量积累到一定大小之后就会造成上面的场景。这种场景下,CMS回收器一样会停止工作,进入漫长的 ’stop-the-world’ 模式。
JVM也提供了参数 -XX: UseCMSCompactAtFullCollection来减少碎片的产生,这个参数表示会在每次CMS回收垃圾之后执行一次碎片整理,很显然,这个参数会对性能有比较大的影响,对HBase这种对延迟敏感的业务来说并不是一个完美解决方案。
注意:CMS GC会不断产生内存碎片,当碎片小到一定程度之后就会基本维持不变,如果此时业务写入一些单条数据量很大的KeyValue,就有可能触发Promotion Failure模式Full GC。在实际线上环境中,很少出现Concurrent Failure模式的Full GC,大多数Full GC场景都是Promotion Failure。
CMS GC调优
GC优化的思想:避免长时间Full GC 和 减少GC时间,这样可以避免影响用户的读写请求和提高读写性能。
CMS默认JVM参数
常见的JVM推荐配置参数模版:
1 | -Xmx -Xms -Xmn -Xss -XX:MaxPermSize= M -XX:SurvivorRatio=S -XX:+UseConcMarkSweepGC -XX:+UseParNewGC |
1 | Xmx 分配给JVM的最大堆内存 |
通过上文对各个GC参数的说明,可以轻松得出第一阶段推荐的参数设置如下,这样的设置基本适用于所有的场景:1
2-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection
-XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=75% -XX:-DisableExplicitGC
CMS GC JVM参数调优
主要的参数在于 Xmn(Young区的大小)、SurvivorRatio(Eden区和Survivor区内存大小比例)。
Xmn -Young区大小设置
JVM调优跟应用的内存对象类型紧密相关,需要区分应用的内存对象是短生命周期居多还是长生命周期居多。HBase应用分析,主要的内存对象有三类:RPC请求、Memstore对象、BlockCache对象。
RPC请求对象:生命周期短,Request对象和Reponse对象在ms~s级别。
Memstore对象:生命周期长,持续到整个Memstore flush到HDFS生成HFile。通常内存对象为2M。
BlockCache对象: 读缓存,生命周期长。
因此HBase应用是生命周期长的内存对象较多,GC时避免大对象进行GC,也就是减少老生代的GC次数。而 新生代的大小直接决定了老生代GC的速度。具体情况就是:
Young区大小决定了minor gc的频率,minor gc频率决定了对象晋升老年代对象的速度(计数器到达即可),从而老年代GC的评率。
Young区设置过大,则minor gc频率降低,单次gc时间会比较长从而stop-the-world时间较长,业务读写操作延迟大。
Young区设置过小,则minor gc频率增大,晋升老年代对象的速度加快,增加了老年代GC的评率和风险。
因此Young区大小设置要合理,在大内存场景RS配置64G内存时 Young区大小建议设置为1~3g:即-Xmn2g。
SurvivorRatio(Eden区和Survivor区内存大小比例)
每次Minor GC都会将存活对象从Eden区复制到Survivor区,因此增大Survivor区可以容纳更多的存活对象。Survivor区的合理设置可以避免因为Survivor区太小导致存活对象没有达到MaxTenuringThreshold阀值就直接进入老生代,减少老生代GC的评率。但是如果设置过大会导致存活对象来回的在Young区进行复制,增加了Minor GC的开销。
SurvivorRatio越大,Survivor区大小越小,建议设置为2。即新生代中Eden区20%,S区80%。
MaxTenuringThreshold阀值不能设置过小,该值直接决定了新生代存活对象进入老生代的概率.默认设置为15即可。
CMS GC 调优结论
- 缓存模式采用BucketCache策略Offheap模式
- 对于大内存(大于64G),采用如下配置:
1
2
3-Xmx64g -Xms64g -Xmn2g -Xss256k -XX:MaxPermSize=256m -XX:SurvivorRatio=2 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+CMSParallelRemarkEnabled -XX:MaxTenuringThreshold=15 -XX:+UseCMSCompactAtFullCollection
-XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=75 -XX:-DisableExplicitGC
其中Xmn可以随着Java分配堆内存增大而适度增大,但是不能大于4g,取值范围在1~3g范围;
SurvivorRatio一般建议选择为2;MaxTenuringThreshold默认设置15即可;
对于小内存(小于64G),只需要将上述配置中Xmn改为512m-1g即可
不同于CMS等其他的分代回收算法、收集的范围都是整个新生代或者老年代,而G1不再是这样。G1将堆空间划分成了互相独立的heap区块(Region)。每块区域既有可能属于O区、也有可能是Y区,且每类区域空间可以是不连续的(对比CMS的O区和Y区都必须是连续的)。G1在全局标记阶段(global marking phase)并发执行, 以确定堆内存中哪些对象是存活的。标记阶段完成后,G1就可以知道哪些heap区的empty空间最大。它会首先回收这些区,通常会得到大量的自由空间. 这也是为什么这种垃圾收集方法叫做Garbage-First(垃圾优先)的原因。现有参数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15-Xms64g
-Xmx64g
-XX:PermSize=256m
-XX:MaxPermSize=256m
-XX:+UseG1GC
-server
-XX:+DisableExplicitGC
-XX:+UseFastAccessorMethods
-XX:SoftRefLRUPolicyMSPerMB=0
-XX:G1ReservePercent=15
-XX:InitiatingHeapOccupancyPercent=40
-XX:ConcGCThreads=18
-XX:+ParallelRefProcEnabled
-XX:-ResizePLAB
-XX:ParallelGCThreads=18
优化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20-Xms64g
-Xmx64g
-XX:PermSize=256m
-XX:MaxPermSize=256m
-XX:+UseG1GC
-server
-XX:+DisableExplicitGC
-XX:+UseFastAccessorMethods
-XX:SoftRefLRUPolicyMSPerMB=0
-XX:G1ReservePercent=15
-XX:InitiatingHeapOccupancyPercent=50
-XX:ConcGCThreads=6
-XX:+ParallelRefProcEnabled
-XX:-ResizePLAB
-XX:ParallelGCThreads=18
-XX:+UnlockExperimentalVMOptions
-XX:MaxGCPauseMillis=90
-XX:G1NewSizePercent=5
-XX:MaxTenuringThreshold=1
-XX:G1HeapRegionSize=32m
参考:
http://blog.csdn.net/u013980127/article/details/53913994
http://blog.csdn.net/renfufei/article/details/41897113
http://www.oracle.com/webfolder/technetwork/tutorials/obe/java/G1GettingStarted/index.html
http://www.oracle.com/technetwork/articles/java/g1gc-1984535.html
http://ifeve.com/深入理解g1垃圾收集器/
https://blogs.apache.org/hbase/entry/tuning_g1gc_for_your_hbase
http://hbase-help.com/?/question/19
http://www.cnblogs.com/ityouknow/p/5614961.html
https://cantellow.iteye.com/blog/1472072