原文链接:http://blog.cloudera.com/blog/2015/02/understanding-hdfs-recovery-processes-part-1/
理解HDFS的恢复机制对使用hadoop的非常有帮助!
HDFS中一个重要的设计原则就是保证生产环境下能够持续正确的执行一些操作,一个重要的点就是保证HDFS在不稳定和网络下,或者节点失败的情况下也能正确写入。HDFS有lease recovery,block recovery,pipeline recovery这几种恢复机制,理解什么情况下将会调用哪种恢复机制也能够帮我们更好的理解我们的集群的工作情况。
本文将带你深入了解恢复机制。首先简单介绍HDFS的write pipr和恢复处理,解释两个重要概念:block/replica stats和generation stamps,然后逐步介绍恢复过程,最后我们总结一些相关的问题。
本文分两部分:part1将会详细介绍lease recovery和block recovery,part2将介绍pipeline recovery。
背景
在HDFS中,文件是切分为一块一块的,多个reader来读文件,一个writer写文件。为了满足数据容错,不同的datanode上会保留文件的备份,备份数量被称为:replication factor。当新的文件块创建,或者要对一个已经存在的文件进行追加时,HDFS会创建一个写管道,管道里面就是存放数据和备份的datanode。如下图写过程: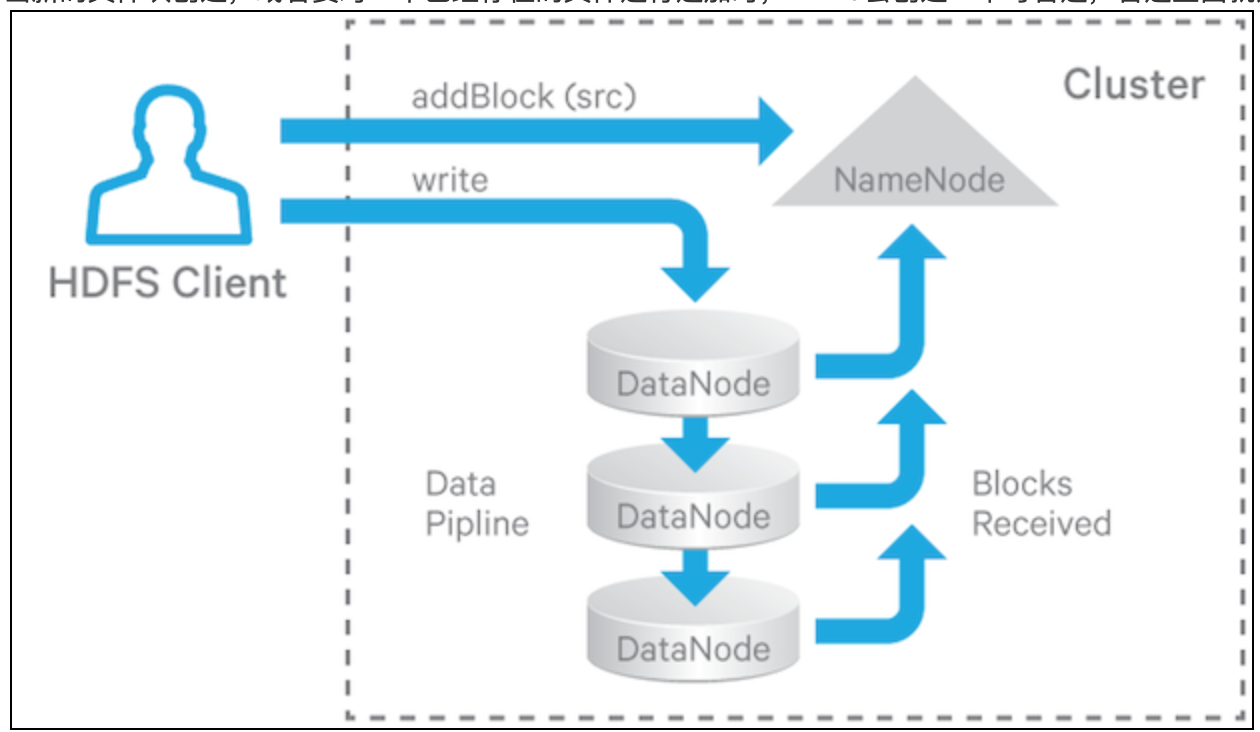
对于读操作,客户端选择含有数据的其中一个datanode,然后发送请求。
下面是两个特别需要容错的场景:
hbase用WAL机制来保证数据安全,WAL是是存放在HDFS上的文件,如果regionserver挂了,就指望WAL来恢复数据了,所以一定要保证写pipeline的正确性。
当一个Flume客户端流式的写入HDFS中时,即使一些datanode挂了,也必须要保证写连续。
既然有了这些需求,下面就该隆重介绍 lease recovery,block recovery,pipeline recovery这三个的作用了。
在client往HDFS中写数据之前,它必须获取一个租约,我们可以理解是一把锁,这样就保证了单点写。这个租约要在预定的时间段内刷新,否则就会超时,HDFS认为这个写操作超时,这时HDFS将会关闭这个文件,释放这个租约,以方便其他client写文件。这个过程叫做lease recovery。
如果正在写入的文件块还没有在所有的datanode中同步时,如果这时候发生lease recovery,那这几个datanode中这个数据块的数据就会不一致,因此在lease recovery关闭这个文件块之前,有必要同步一下各个datanode之间的数据。这个过程叫做block recovery。它只会被lease recovery触发,并且只有不是COMPLETE状态的文件块才会被lease recovery触发block recovery。
在管道写的时候,假如一些datanode挂掉了,这时候HDFS并不会就直接停止写操作,它会试图恢复错误,来保证继续写文件,这个过程叫pipeline recovery。
下面我们详细解释一下:
为了区分namenode上下文中的block和datanode中的blocks,这里我们指定前者为blocks,后者为replicas。
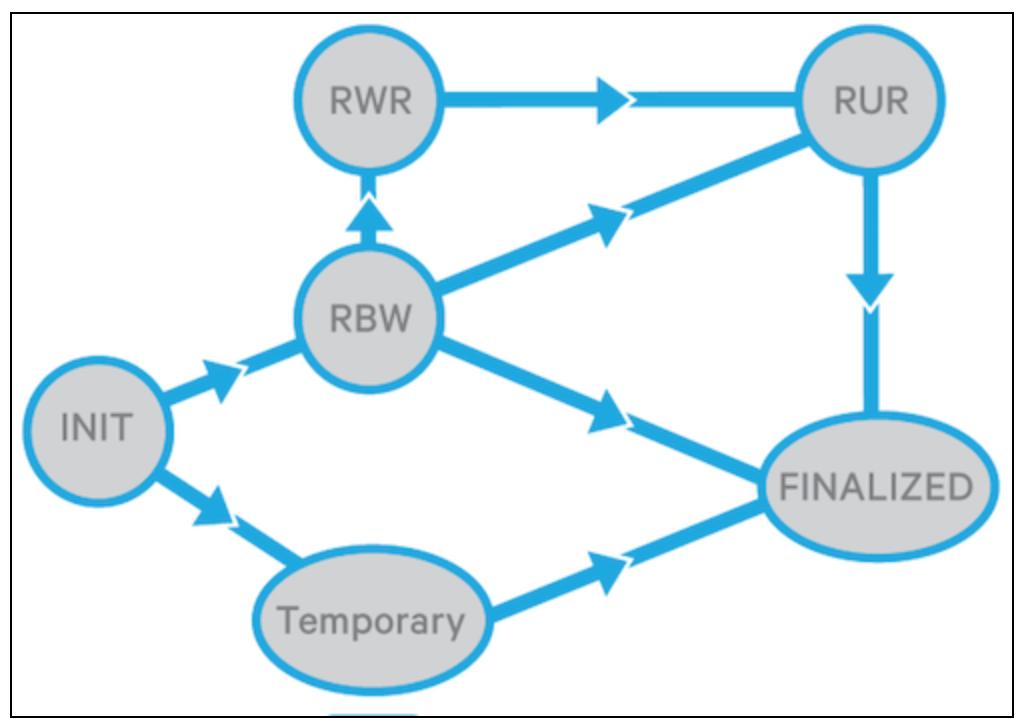
在datanode的上下文中,一个replica的状态有以下几种(可以在org.apache.hadoop.hdfs.server.common.HdfsServerConstats.java这个类中找到ReplicaState枚举类):
FNALIZED:当replica是这个状态时,表明数据已经写完了,这个replica将不会再发生变化,除非这个replica再次因为追加数据被打开。一个block中的所有Finalized的replica都有一个仙童的generation stamp(GS),GS也有可能因为一次recovery而变大。
RBW(replica being written):表明一个replica正在被写入,一般处于RBW的replica都是文件的最后面的block。RBW的replica的数据对cilent是可见的,如果期间发生错误,HDFS将会尝试保护这些没有Finalized的数据。
RWR(replica waiting to be recovered):如果datanode挂了并且重启了,它所有的RBW的replica将会变成RWR状态,RWR状态下的replica要么因为过时被丢弃,要么参与lease recovery(这里是什么意思)。
RUR(replica under recovery):一个non-TEMPRORARY的replica将会变成RUR状态,当它参与lease recovery的时候。
TEMPORARY:为了block replica而临时创建的replica。它和RBW replica很类似,只不过它的数据对client是不可见的。如果replication失败,它将会被删除。
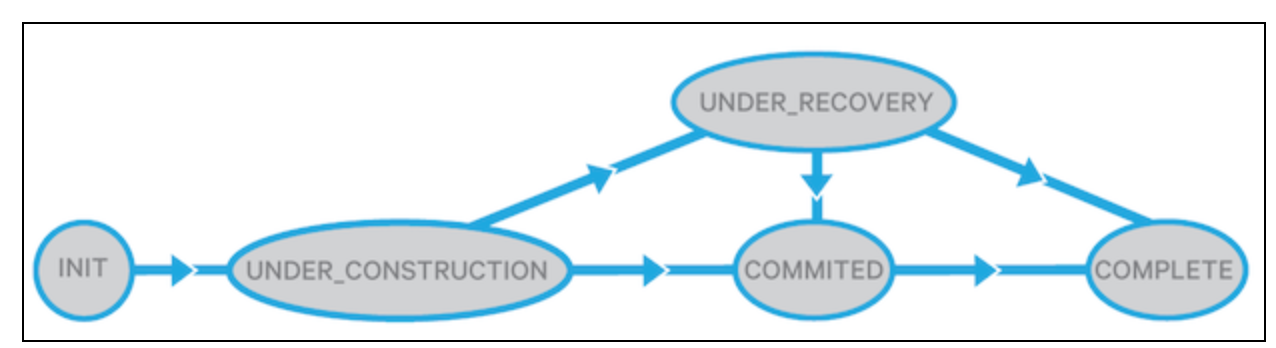
namenode中的block可能有下面集中状态(可以在org.apache.hadoop.hdfs.server.common.HdfsServerConstats.java这个类中找到BlockUCState枚举类):
UNDER_CONSTRUCTION:这个状态发生在正在写入时,UNDER_CONSTRUCTION通常是一个打开的文件的最后一个block,它的茶馆难度和genaration stamp都是可变的,数据对用户也是可见的,这个UNDER_CONSTRUCTION block是namenode是用来追踪写管道,和定位RWR replicas的位置。
UNDER_RECOVERY:如果处于UNDER_CONSTRUCTION的block发生了lease expire,它将变成UNDER_RECOVERY。
COMMITED:这个状态表示block的数据和GS不再改变,但是(还是贴原文吧,这句翻译不好,and there are fewer than the minimal-replication number of DataNodes that have reported FINALIZED replicas of same GS/length,大概意思是:已经FINALIZED的replicas比datanode最小的复制数要少,),这时候为了安全提供读服务,COMMITTEDblock必须追踪RBW replicas的位置,GS,和FINALIZED replicas的数量。当client要求namenode添加一个新的文件block,或者关闭一个文件时,UNDER_CONSTRUCTION block将会变成COMITTED状态。但是如果(这个文件)之前的blocks是COMMITED状态时,文件不能被关闭,client必须部队重试。
COMPLETE:当namenode看到FINALIZED的replica的最小数量和GS/length(疑问)匹配时,对应的COMMITTED block变成COMPLETE状态。只有当文件所有的block都是COMPLETED状态时才可以被关闭。有时block也有可能被强制变成COMPLETE状态,即使replicas的数量并没有满足最低要求,例如:当client要求一个新的block,并且周期i安的block还没有COMPLETE。
datanode持久化replicas的状态到硬盘上,但是namenode并不持久化block的状态,当namenode重启时,它将任何之前打开的文件的最后block变成UNDER_CONSTRUCTION状态,其他的block变成COMPLETE状态。
下面是replica和block的状态转换图:
replica:
block:
generation stamp
GS是一个单调递增的8byte的数字,namenode傻姑娘的每一个block都各自维护一个。GS为了以下目的设计(参考链接:HDFS Append and Truncates ):
发现block中陈旧的replicas:意思是,replica的GS比block的GS要older,例如当一个append操作不知怎么的跳过了replica。
发现datanode上过期时间很长的replica,并且重新加入集群。
下面情况发生时会产生新的GS:
创建一个新文件
client打开一个存在的文件,为了追加或者删除。
当在写数据到datanode上时发生了错误。
namenode为一个文件初始化一个lease recovery
lease recovery和block recovery
lease Manager
租约是namenode上的租约管理器来管理,namenode追踪每一个被client打开写的文件。client不会单独为每一个它所打开的文件刷新租约,它是每隔一段时间发送一个请求来刷新所有的租约。(org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos.RenewLeaseResponseProto类,HDFS client和namenode的RPC协议)
每一个namenode管理一个HDFS namespaces,每个namespaces通过一个lease 管理器来管理所有的文件。(Federater HDFS集群可能有多个namespaces。)
lease管理器维护一个软限制(1分钟)和一个硬限制(1小时)超时时间,在软限制没有过期之前,client拥有对文件的排它写权限,,如果软限制超时,或者文件被关闭,另一个client可以强制领走该文件的租约。如果硬限制超时,HDFS就会认为client已经退出,并且关闭该client在该文件上的所有行为,并且开始恢复租约。
如果一个client已经获取了一个文件的租约,但这并不影响其他client读这个文件,一个client可以对文件写的时候,同时可以有多个client对文件读。
lease管理器内部支持的操作有;
1.为一个client和路径添加租约(如果client已经拥有了租约,它添加路径到这个租约,否则它将会创建一个新的租约,并且绑定路径)
2.移除租约和路径(如果这是租约中的最后一个路径,那么租约也一起移除)
3.检查是否有软限制或者硬限制超时
4.刷新client的租约
lease 管理器每隔2妙会进行一次检查,看是否硬限制超时,如果发现有,它将会触发这个租约上的所有文件的lease recovery。
HDFS client通过org.apache.hadoop.hdfs.LeaseRenewer.LeaseRenewer类来刷新租约,这个类包含了一个用户列表,并且client为每个namenode上的每个用户运行一个线程。这线程定时检查namenode并刷新租约,当lease period过半的时候。
(注意:一个HDFS client只链接一个namenode)
lease recovery process
有2种情况会触发namenode对一个client进行lease recovery:1.监控线程发现硬限制超时,2.当软限制发生时,一个client尝试拿走另一个client上面的租约。它将会检查该client打开的所有文件,如果文件最后的block不是COMPLETE状态,就进行block recovery,并且关闭文件。block recovery只有在恢复文件的租约的时候才会被触发。
下面是lease recovery的算法,针对一个文件f:
1.得到含有f的最后block的datanodes。
2.指定其中的一个datanode为主datanode p。
3.p从namenode上获取一个新的GS
4.p获取每一个datanode上的block信息
5.p计算最小的block长度
6.p更新所有的datanodes,包括GS和最小block长度
7.p通知namenode更新结果
8.namenode更新blockinfo
9.namenode移除f的租约(现在其他的client可以获取这个文件的租约了)
10.namnode提交日志
步骤3到7是block recovery算法,如果一个文件需要block recovery,namenode选择一个主datanode,这个datanode哟国有文件最后block的replica,然后namenode告知这个datanode负责其他datanode的block recovery。然后datanode向namenode汇报结果,namenode更新它自己的block状态,移除租约,提交日志。
有时,管理员需要自己强制执行recovery,在硬限制超时之前,可以通过命令行来执行:1
2hdfs debug recoverLease [-path
<path>] [-retries <num-retries>]
总结:
Lease recovery, block recovery, and pipeline recovery对HDFS的容错是必须的。它们保证即使有网络不稳定,或者节点失败,仍然能够保证数据持续写和一致性。
下篇我们介绍
pipe recovery
the write pipeline:
当HDFS client写文件时,数据作为block块依次写进去,HDFS将block切分为packets,然后发送给datanode管道,如下图:
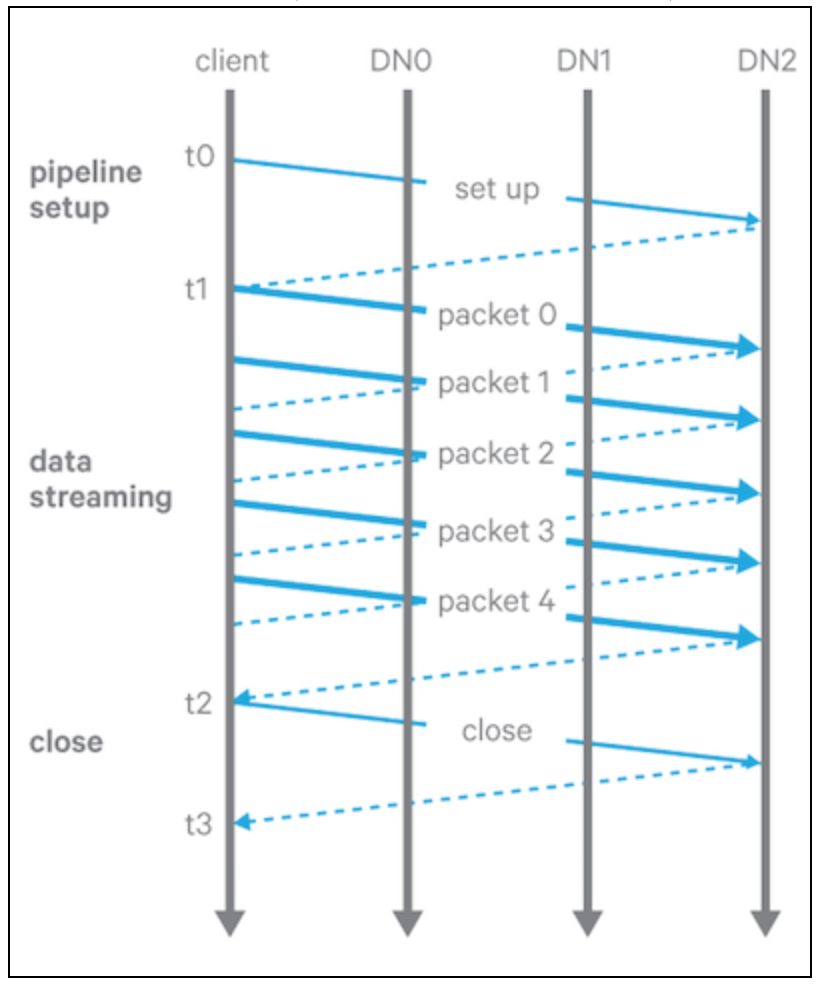
wite pipeline有3个阶段:
1.pipeline setup:client向pipeline发送一个写请求,然后最后一个datanode节点返回一个确认信息,收到确认信息之后,pipeline开始准备写数据。
2.Data streaming:数据是以packet的方式送到pipeline中的,client端缓存数据,当buffer的大小等于packet的大小时,发送出去。client可以选择使用hflush()来强制发送,但是下一个packet必须要等到上一个调用hflush()的pakcet的确认信息后才能发送。
3.close:所有的packet都返回确认信息后,client发送一个关闭请求,所有的datanode将对应的replica变成FINALIZED状态,并且报告给namenode。当FINALIZED的datanode满足配置的replica个数时,然后namenode将block的状态变成COMPLETE。
pipeline recovery:
当datanode在文件正在写入时,以下三种情况下发生错误,都会触发pipeline恢复。
1.recovery from pipeline setup failure
2.Recovery from Data Streaming Failure
3.Recovery from Close Failure